 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
A new generation of designs ready to shake up conventional server architecture emerged at the recent Open Compute Project Summit, where Google, Facebook and Microsoft showed off new blueprints for high-performance computers.
The hardware demonstrated at the trade show, which was held in Santa Clara, California, showed that cloud providers were continuing to deprioritize CPUs, while putting more focus on networking, storage and accelerators like GPUs and AI chips. The OCP designs can be replicated and improved upon by server makers.

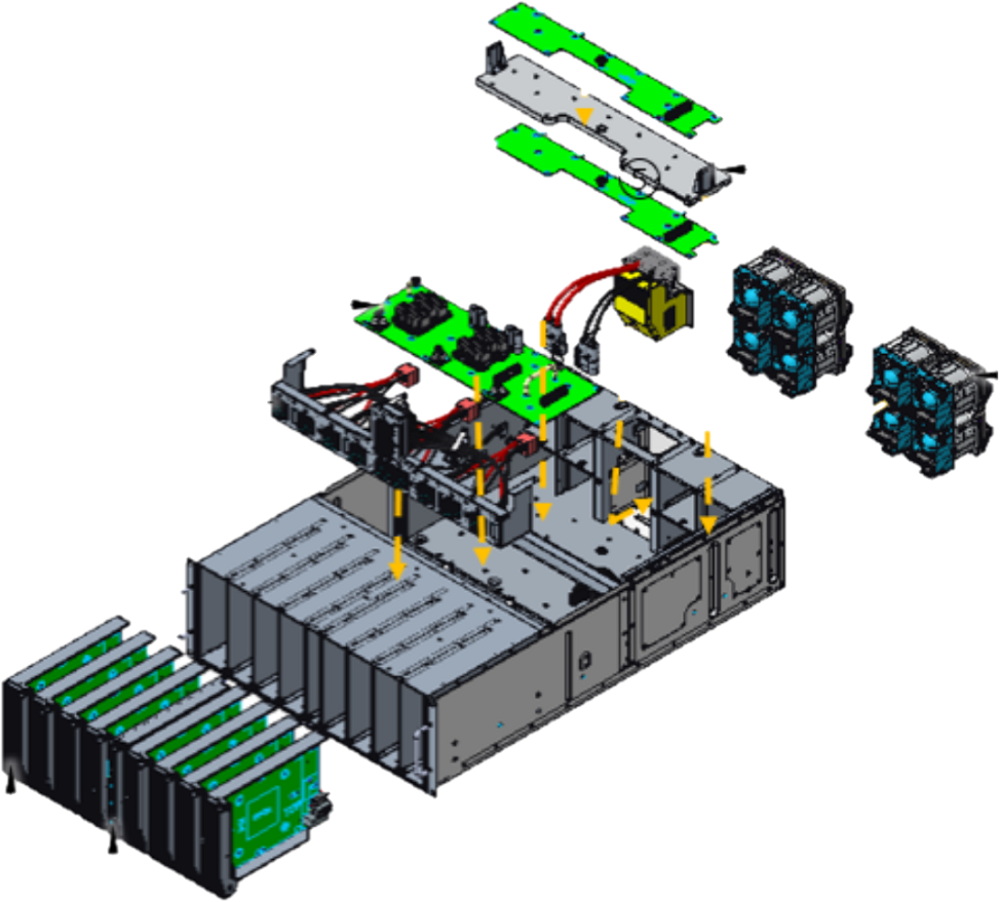
The headliner was Meta’s server design called Grand Teton, which the company is deploying for datacenters to run artificial intelligence applications. Meta’s goal is to bring to its mega datacenters more AI capacity, which underpins many functions on its social media platforms, but also prepare for its metaverse future, said Alexis Bjorlin, vice president of engineering at Meta, in a blog entry.
OCP includes the who’s who of the server world – Meta, Google and others – with all the cool new hardware showing up here before it comes to standard racks from Dell, HPE and Lenovo, said Dylan Patel, said founder of SemiAnalysis, a semiconductor research and consulting firm, who attended the show.
“When we’re talking about that hardware it was a lot of much higher power but also efficient. It might be high power because it is used in Facebook’s AI or it might be high power because it is a server that is packed very dense,” Patel said.
Patel also noted that many next-generation servers were also shown with Intel next-generation Xeon server CPU codenamed Sapphire Rapids and AMD’s upcoming Genoa.
Bjorlin last month said that Meta plans to build mega clusters with over 4,000 accelerators by 2025. The cores, which will be organized as a mesh, will have a bandwidth of 1 terabyte per second among accelerators. Bjorlin detailed those plans during a speech at the AI Hardware Summit last month, but did not share hardware details. The company uses Nvidia GPUs extensively.
Meta’s fundamental approach to server designs includes stripping out unnecessary components, and shrinking hardware at the system and chip levels. The shrinkage of system and chip size would contribute to the creation of AI training clusters that would draw more power, but also deliver significantly more performance per watt.
The deep-learning models are growing significantly to tens of trillions of parameters, and “can require a zettaflop of compute to train,” Bjorlin said in the Grand Teton announcement.
“AI and machine learning models are becoming increasingly powerful and sophisticated and need more high-performance infrastructure to match,” Bjorlin said.
Grand Teton is the successor to the Zion-EX scale-out system introduced in 2021. Grand Teton is significantly faster than its predecessor with four times more host-to-GPU bandwidth, and two times the compute capacity and throughput.
“Grand Teton also has an integrated chassis in contrast to Zion-EX, which comprises multiple independent subsystems,” Bjorlin said.
Microsoft showed off a modular system called Mt. Shasta, which is a chassis that can house accelerators for AI and high-performance computing. The module fits into high-performance servers through a 48-volt power feed. The module can be hotswapped and accommodate multiple accelerators. The system was designed with Molex and Quanta, and is compatible with OCP’s Open Rack V3 design, which opens up rack-level disaggregation for systems.
The Mt. Shasta module solves common problems faced in implementing accelerators in datacenters, Microsoft said in a blog post. The accelerators can be implemented easily within a datacenter’s power, cooling and connectivity guidelines, and automates interfacing with software-based management for hardware control. A node-level hook makes the module hot-swappable, which can also be difficult within the PCI Gen 3.0 interface, which is old but still used on older servers.
Diversifying server hardware for accelerators has always been a priority, but there was a lot of excitement this year around CXL (Compute Express Link), which provides the hooks to easily add a range of accelerators, said Nathan Brookwood, principal analyst at Insight 64, who visited the show.
“Clearly, the guys who are deploying in the cloud – you’re looking at Google, Microsoft, and such – those guys know what they need. They would probably be the ones who would strip out more bells and whistles that HPE and Dell put into general purpose, enterprise-class products,” Brookwood said.
CXL is a critical building block that is set to change the way servers are designed, customized and configured. CXL allows for easier selection and assembly of building blocks of servers. The technology provides a communication link between computing, memory and storage systems, and includes tools to provision and manage computing across the server.
“CXL is moving rapidly toward acceptance, which is surprising, because the general-purpose processors that support it haven’t yet been released, including [Intel’s] Sapphire Rapids, and [AMD’s] Genoa,” Brookwood said.
While Facebook’s Grand Teton was an integrated server, Google focused on a “multi-brained” server of the future, which consolidates storage, accelerators, memory and infrastructure processing units into separate trays. The modular hardware architecture is based on interconnects that include CXL and NVMe and distributed system management tools such as OpenBMC and RedFish.
The excitement around CXL was equally shared by smaller server makers, Brookwood said.
“As those come out, I think smaller server makers, especially in the cloud, are going to be looking at that,” Brookwood said.

IT infrastructure company Wiwynn, a subsidiary of the Taiwan-based Wistron Group, is focusing on the building blocks to tailor server designs. The company previously specialized in integrated server designs for OCP, but this year’s focus was on custom designs built to specific requirements.
Wiwynn’s building blocks include OCP-certified cooling, power, components, interconnects, NICs and security modules. The CXL interconnect was also in the design, sitting in the middle to facilitate communications between storage, memory and processing units.
The design is for a wide range of x86 server chips from Intel and AMD, and Arm server chips like Ampere’s CPUs. It also supports accelerators like Habana Gaudi AI processors from Intel.
The change in focus to building blocks came from clients as they are interested in building servers closer to their datacenter requirements, said Steven Hwang, executive director, for sales enablement at Wiwynn, during a press briefing ahead of the OCP Summit.
Specifically, there was a lot of interest in power conversion components, Hwang said, adding, “a lot of datacenters are going green and the energy becomes very, very sensitive… so the power loss from DC to AC and AC back to DC is certainly something that people can benefit [from] immediately.”

At OCP, Google, Microsoft, Nvidia and AMD also partnered to create a specification, called Caliptra, that lets system makers embed security layers at the chip and system levels. The specification, which is in version 0.5, focuses on creating a root of trust in silicon.
“As a reusable open source, silicon-level block for integration into systems on a chip – such as CPUs, GPUs, and accelerators – Caliptra provides trustworthy and easily verifiable attestation,” said Mark Russinovich, Microsoft’s Azure CTO, in a blog entry.
The Caliptra spec includes a series of blocks to store and encrypt data, and to make sure only authorized parties get access to data in a secure enclave. It also ensures security of data so it is not exposed to hardware-based hacks like Spectre and Meltdown while on-premise or in the cloud. The cloud providers are interested in Caliptra to improve confidential computing offerings and to secure virtual machines.























































