 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Cerebras is putting down stakes to be a player in the AI cloud computing with a supercomputer called Andromeda, which achieves over an exaflops of “AI performance.”
The company called Andromeda one of the fastest AI systems in the U.S. The system strings together 16 CS-2 systems in a cluster, with a total of 13.5 million compute cores focused on AI.
Each CS-2 system has a wafer-sized chip with 850,000 cores, which is considered the largest piece of silicon ever made. The Andromeda system has 96.8 terabits of internal bandwidth.
For preprocessing, Andromeda is attached to 284 single-socket servers, with each system having an AMD Epyc 7713 “Milan” CPUs, 128GB RAM, three 1.92TB NVMe drives and two 100Gb Ethernet network cards.
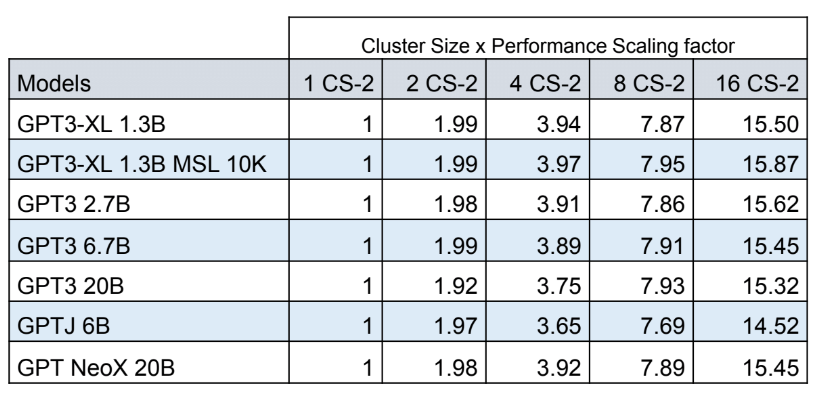
The exaflop benchmark is based on 16-bit, half precision performance with linear scaling, said Andrew Feldman, CEO of Cerebras.
“Linear scaling means when you go from one to two systems, it takes half as long for your work to be completed. That is a very unusual property in computing,” Feldman said, adding that Andromeda can scale beyond the 16 connected systems.
A single chip in the CS-2 can train language models with billions of parameters. Andromeda can potentially train larger language models with trillions of parameters, or train smaller models in less time.
Andromeda cost about $30 million to build and was set up in just three days, Feldman said.
Feldman said the system offers comparable performance to the Polaris supercomputer at Argonne Leadership Computing Facility, which has 2,240 Nvidia A100 GPUs and 560 AMD Milan CPUs. The Top500 implementation of Polaris delivers 25.8 Linpack petaflops (out of a theoretical 34.2 petaflops) in 64-bit double-precision, or roughly 700 petaflops of FP16 tensor core performance.
The Andromeda system is built over 16 racks, and is smaller in size than Polaris, which uses 40 racks. Polaris is the 14th fastest supercomputer in the world, according to the Top500 list released in June this year.
The supercomputer, which is deployed at a Colovore datacenter in Santa Clara, California, is being used in multiple ways. The system is accessible via the cloud to companies who want to try the hardware before buying. It is also available to companies looking to rent computing resources.
“We’re using it for companies who have a big problem that they want to solve and don’t want all the equipment necessary to solve it,” Feldman said.
The Andromeda system is also available for free to students and academics. It takes just a few lines of code to deploy AI models, Feldman said.
Cerebras’ shift to becoming an AI cloud provider follows the footsteps of chip makers like Intel and Nvidia, which have their cloud services for customers to test chips or code. The company’s customer list includes TotalEnergies and GlaxoSmithKline.
Meta is also developing an AI supercomputer with 6,080 Nvidia A100 GPUs to augment its AI and metaverse driven computing, while Tesla also has an AI supercomputer with 7,360 A100 GPUs.
The systems in the Andromeda cluster are connected by a fabric called SwarmX to disaggregate memory, computing and networking into separate clusters. The compute and memory elements operate as a single system and scale independently, which helps in faster training of AI models. The parameters are stored in an internal system called MemoryX.
The disaggregation of resources in CS-2 is different from GPU environments, in which computing is broken up over AI cores distributed over a wide area. Calculations need to be orchestrated over this network of cores, which Feldman has said can be time consuming and inefficient. AI calculations also need GPUs to operate identically across thousands of cores to get a coordinated response time.


























































