 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
For a few moments, the atmosphere was more Rock Concert than Supercomputing Conference with many members of a packed audience standing, cheering, and waving signs as Jack Dongarra took the stage to deliver the annual ACM Turing Award lecture at SC22. Few people are as deeply associated with evolution of HPC software or with the Top500 list that spotlights the fastest supercomputers in the world than Dongarra, who with Hans Meuer, and Erich Stromaier, created the Top500 in 1993. (The latest Top500 was unveiled on Monday at SC22.)
“I wasn’t expecting this. Wow,” said Dongarra, visibly moved. “I have to say it’s a tremendous honor to be the most recent recipient of the ACM A.M. Turing Award. An award like this couldn’t have come about without the help and support of many people over time.”

Considered the Nobel Prize of computer science, the ACM A.M. Turing Award, named for Alan Turing, also carries $1 million prize. Here’s brief excerpt of the ACM tribute to Dongarra:
“Dongarra has led the world of high-performance computing through his contributions to efficient numerical algorithms for linear algebra operations, parallel computing programming mechanisms, and performance evaluation tools. For nearly forty years, Moore’s law produced exponential growth in hardware performance. During that same time, while most software failed to keep pace with these hardware advances, high performance numerical software did – in large part due to Dongarra’s algorithms, optimization techniques, and production-quality software implementations.
“These contributions laid a framework from which scientists and engineers made important discoveries and game-changing innovations in areas including big data analytics, healthcare, renewable energy, weather prediction, genomics, and economics, to name a few. Dongarra’s work also helped facilitate leapfrog advances in computer architecture and supported revolutions in computer graphics and deep learning.”
The title of Dongarra’s talk – A Not So Simple Matter of Software – nicely captures Dongarra’s decades-long work in HPC software development. Without underlying software, the stunning advances we’ve seen in HPC hardware would never deliver their promise. While co-design methodologies are increasingly used and seek to better blend hardware and software development – the Exascale Computing Project is a good example – the ground-level truth is that software is always a step behind.
“We’re in sort of a catch-up mode all the time, I feel,” said Dongarra. “The architecture changes and the algorithms and software try to catch up with that architecture. I have this image of the hardware people throwing something over the fence, and the algorithms people and software guys scrambling to figure out how to fit their problems on that machine to effectively deal with it. It takes about 10 years to do that. Then [a] new machine is thrown over the fence and we start that cycle over again.”

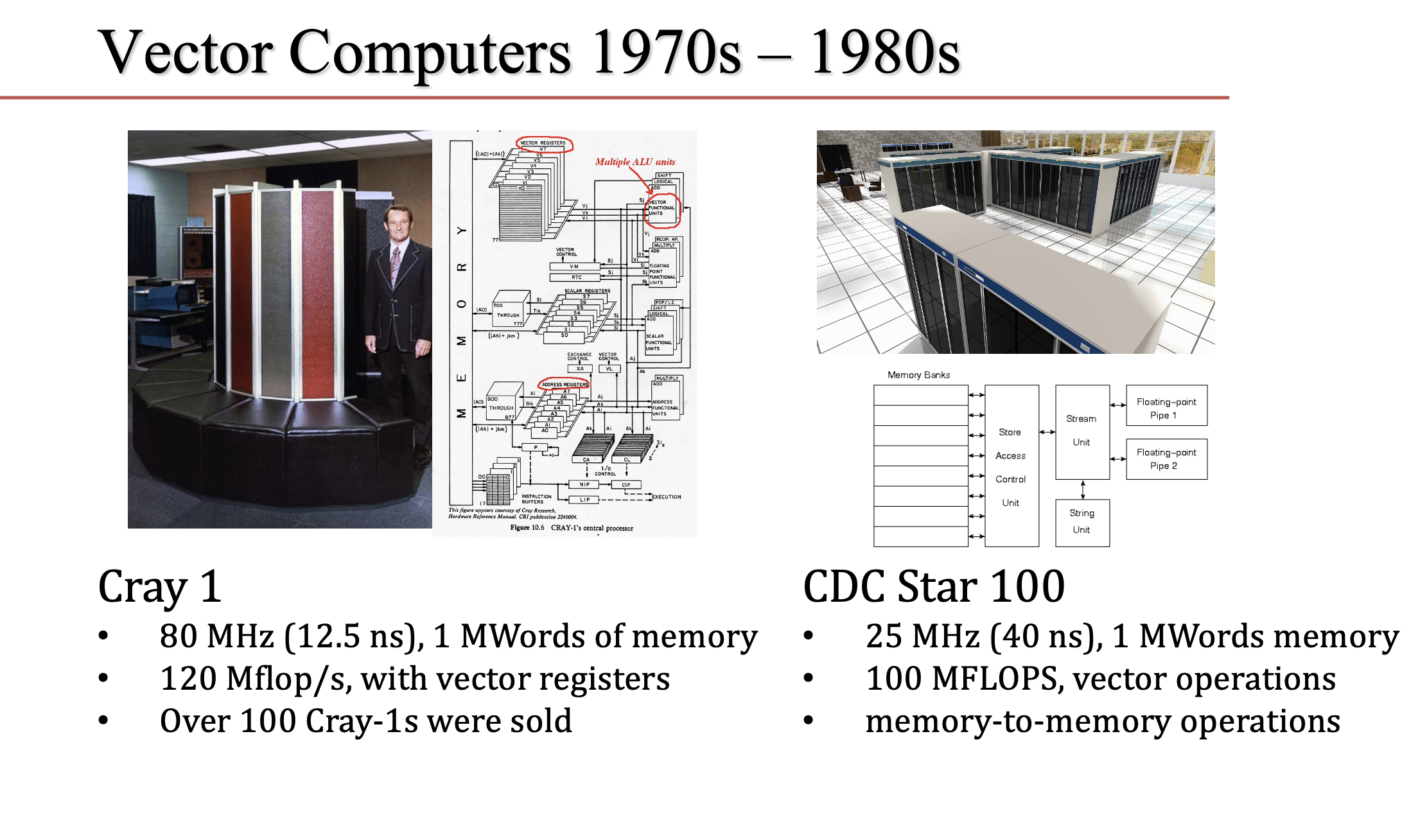
Dongarra covered a lot ground in his talk, starting with the early vector-based machines (think Cray1) of the 1970s and pushing forward through multicore-based CPUs and clustering to today’s heterogeneous architectures (think Frontier) that combine CPUs and a variety of accelerators. Software development was the connecting thread. He’s had his hands in the development of math libraries (various BLAS, LAPACK), message passing (MPI), the LINPACK benchmark, directed acyclic graph (DAG) scheduling, and more.
He provided a brief glimpse into his roots.
“My grandfather was 42 when he took the family to Naples, boarded a boat, and sailed for Ellis Island. And that was in 1929. He had $25 in his pocket, and filled with hopes and dreams of a life there. My father was 10 years old,” said Dongarra. “I did pretty good in math and science, but really struggled with reading and spelling and later as an adult I learned I was dyslexic.” He went to Chicago State University, graduating in 1972.
“My dream was to be a high school teacher. My last semester in college, I was encouraged to apply for a position at Argonne National Laboratory. This was a position where you would spend a semester with a scientist. I think I joined about 30 other undergraduates at Argonne. I was in the math and computer science division at Argonne, working with Brian Smith on software for mathematical software and it was a transformational semester. I realized I had a passion for those kinds of things, developing software, mathematical software, and linear algebra. As a result of that encounter, I stayed at Argonne from that point until 1989.”
Not bad for someone of modest roots and modest early ambition. From Argonne National Laboratory he joined Oak Ridge National Laboratory and the University of Tennessee and has been there since. He retired from teaching in July but maintains his research schedule and, of course, his role in the Top500.
Capturing all of Dongarra’s comments is beyond the scope of a short article. Presented here are a few of his comments and slides around key points in his long career. That said, no account would be complete without going back to the creation of the Top500 which Dongarra calls “The Accidental Benchmark.” The story starts in the early 70s when vector machines ruled the roost and the creation of LINPACK.

“We were evolving our ideas about software, trying to match the hardware characteristics of the time. The hardware characteristics were vectors. We thought we should put in place ideas that highlighted those vector operations,” recalled Dongarra. “There was a de facto community-based standard that was proposed by four people – Chuck Lawson, Fred Crowe, David Kincaid, and Dick Hanson – for doing these vector operations [and] I went off and immediately implemented them in Fortran and used the technique of unrolling the loops. So that’s a standard time technique that we assume a compiler can do. But back in 1973, that was a rather novel thing to do. And that resulted in my first publication, unrolling loops in Fortran and it led to an improvement in performance of about 10-to-20% on many, many systems.
Software portability, not surprisingly, was both a growing concern and goal.
“We wanted to take all the concepts and the opportunities for doing portable programming that were gained in the EISPAC project and move them into another thing, solving systems of linear equations. The Eigenvalue problem was one of the first things that was tackled. The follow-on project was going to do systems of linear equations, least-squares problems, and singular values. This project would respect the Fortran organization, use the de facto standard that had just put in place to accomplish,” recalled Dongarra.
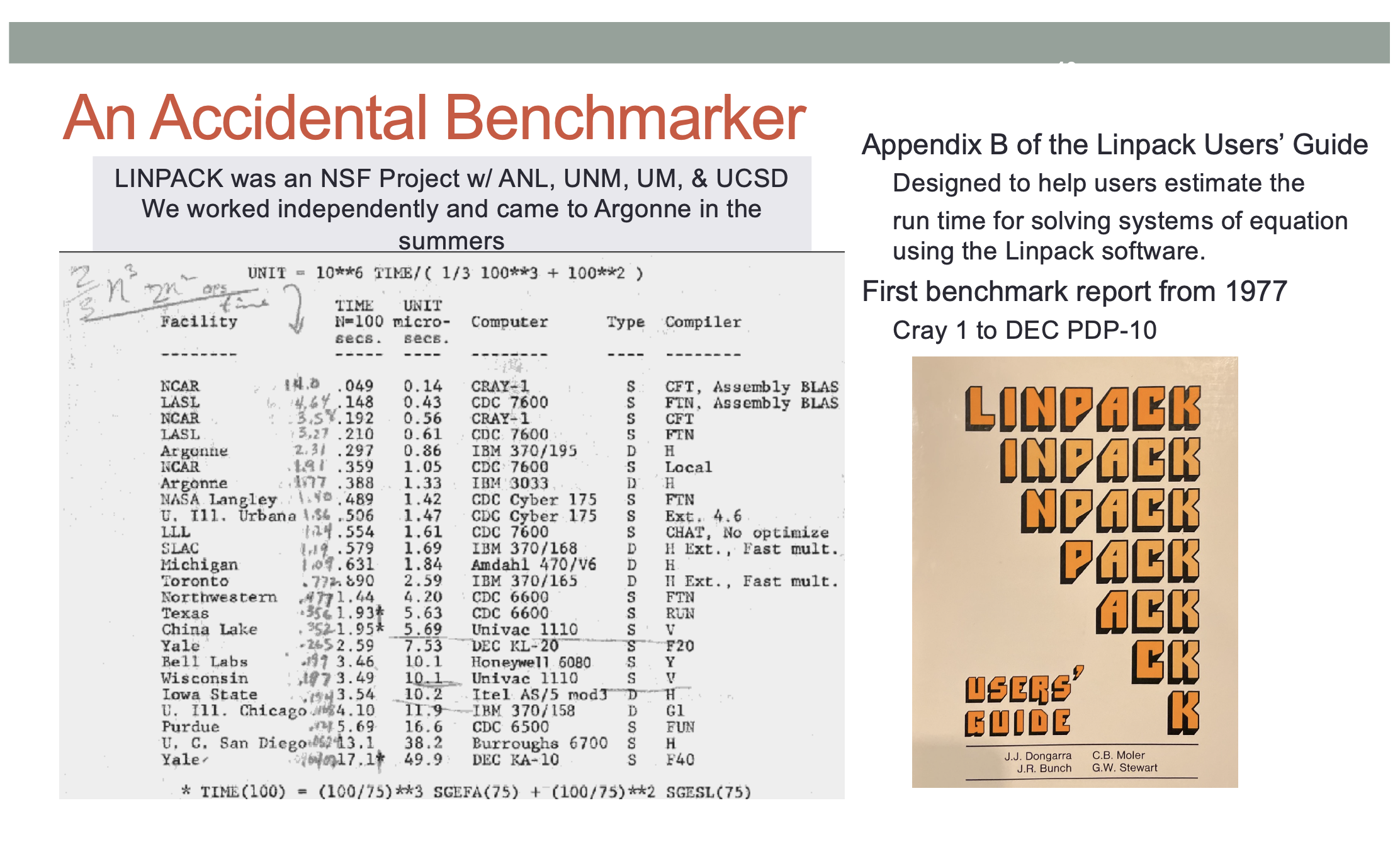
“That’s really the origins of the LINPACK project. So LINPACK – many people think of it as a benchmark, but it’s actually a collection of software for solving systems of linear equations. It was funded by NSF [and] involves four groups, one at Argonne that was contributed by myself, [another at the] University of New Mexico [with] Cleve Moler, the University of Maryland [with] Pete Stewart, and University of California with Jim Bunch. So that’s a picture of us. Jim Bunch on the far right here, Pete Stewart, Cleve Moler. And that’s the 1979 version of me with a little bit more hair. And that’s my car.”

So where’s the list?
“In the appendix of this user’s guide, I put together a little table that was a result of solving a system of equations for a matrix of size 100 and it reported on 24 machines ranging from a Cray1 to a DEC (Digital Equipment Corp) PDP 10 computer. This table (slide below) is a record of that benchmark – if you will – solving a system of linear equations. I put down the time it took to solve it. The hand scribble is the is the rate of execution for each of those machines,” he said.
“So the Cray and NCAR [system] turned out to be the fastest computer at 14 megaflops for solving that system of linear equations. The guy at the bottom of the list is a PDP system that was at Yale. That’s really the origins of the LINPACK benchmark. This is the first ranking of it (LINPACK). The Top500 hasn’t even been thought of at this point in time. But I maintained this list and [it] grew from 24 machines to 100 machines, to 1,000 machines, to about 5,000 systems at one point. So there were many, many machines and we had a good basis for looking at performance.”
Looking through the systems and vendors on the list below is a neat stroll through computer history.
The Top500 was eventually created in 1993. “Since 1978, I had this list of machines for solving systems of equations. Hans and Erich had a list of the fastest computers, ranked those machines by their theoretical peak performance. Hans and Eric approached me and said, we should really merge our two lists and call it the Top500,” said Dongarra, and so they did. The Top500 list is updated twice a year, once at SC in November and again at ISC in May or June.
“The way to think of this [benchmark] is we’re going to solve a system of equations. The ground rules say you must use Gaussian elimination with partial pivoting, you have to do 64-bit computations, and we’re going to look at the performance. Typically, as you increase the size of the problem, the performance goes up until it reaches some asymptotic point, and what we’d like to do is capture the asymptotic performance for solving a system of equations using Gaussian elimination and 64-bit floating point arithmetic. That’s the basis for all the numbers we have since this list was created.”
A champion of collaborative software development generally, Dongarra reviewed somewhat similar experiences around the development LAPACK and MPI. Throughout his talk, he emphasized that it is changes in the hardware that drive changes in software. Consider the arrival of powerful microprocessors and cache memory.
“Because the machines had cache, we realized that we needed to raise the level of granularity of the operations. Vector operations were too simple. We wanted to exploit the cache as much as possible. So we got together a community activity to define what we call the level two and level three BLAS (Basic Linear Algebra Subprogram). Level two BLAS perform matrix vector operations and level three do matrix-matrix operations,” he said.
“The idea being that we could cache store a part of that data and get very rapid access to the elements of the matrices, and the performance would be enhanced as a result of exploiting of that characteristics. We decided to form an effort to develop the software for this project. It was funded mainly by the National Science Foundation and the Department of Energy. [The goal] was to take the ideas and algorithms in LINPACK together with the algorithms and ideas in EISPACK and put them together in a single package,” said Dongarra.
The result was LAPACK designed to effectively exploit the caches on modern cache-based architectures and the instruction-level parallelism of modern processors.
The rise of distributed memory machines was another driver and helped give rise to MPI.
“Message passing was in the air. We didn’t have a standard. Each manufacturer had its own way of doing message passing, each group had its own way of doing it. The group at Argonne had P4, the guys at U Tennessee had PVM, there was a group at Caltech that had its way of doing it, another group out in Germany had their way, and there were guys at Yale doing something else. There was really a need to have a standard so [we could] develop software that would be effective and portable across the machines without having to do major rewrites of the software. That was the catalyst for MPI,” said Dongarra, who emphasized this too was a community-driven project.
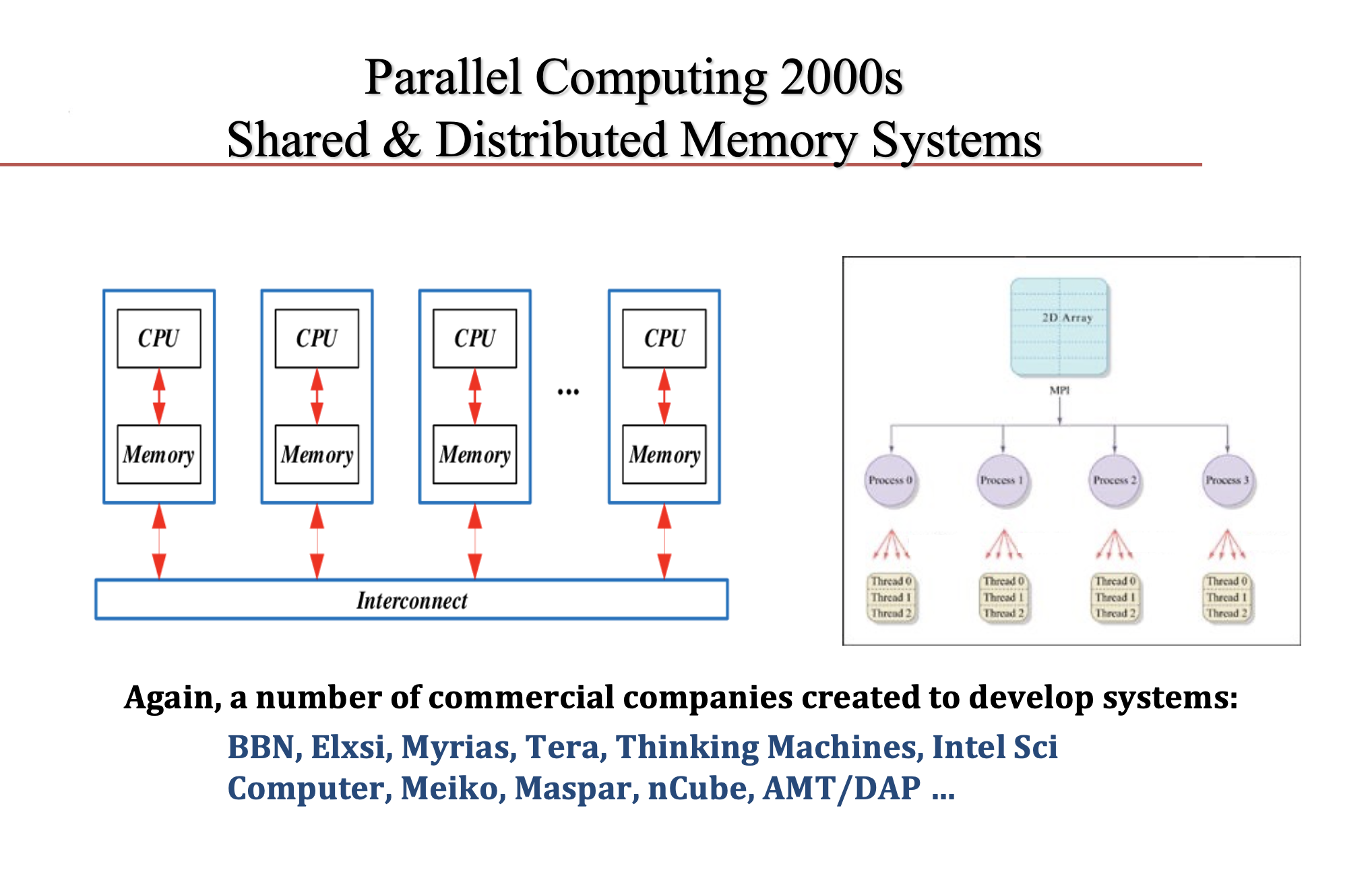

“It was started by perhaps 35-40 people. We followed the roadmap that Ken Kennedy had laid out using the same template that he had for the HPF Forum (High Performance Fortran Forum). The idea was to bring together that group of people every six weeks, and do that for three days concentrating on developing the standard. We decided that around a year and a half would be the right time. That was a target,” he recalled.
“We had great contributions from many people. The guys at Argonne, Bill Gropp and Rusty (Ewing) Lusk, decided to do an implementation of the standard as it was being developed. So, we had a way to test out ideas immediately. That [provided] terrific feedback that allowed us to make changes and ultimately ended up with having the standard implemented and easily being adopted by many groups.”
Dongarra had lots to say about the Top500, the fading value of LINPACK as a metric and his strong belief that HPCG [High Performance Conjugate Gradients] is a better measure. He also talked at length about memory-bound obstacles, the rise of CPU-supervised systems in which GPUs do the vast bulk of the work. HPCwire will have coverage of those issues in its reporting on the recent Top500 results. At his talk, he urged attendees to go to the Top500 BOF, which he said would tackle many of the thorny issues facing the Top500.
Q&A turned up a couple of interesting discussion points. One question, not surprisingly, was around future architectures.
“Today, we have machines that are built on manycore plus GPUs. I would think that in the future, we would see that expand, [and] have other accelerators added to that collection. So think about adding an accelerator that does something specific for AI. Or think about adding an accelerator which does something like neuromorphic computing. We can add accelerators to the collection to help in solving our problems. Maybe quantum would be another accelerator – I don’t see quantum being its own compute,” said Dongarra.
The benefit, said Dongarra, is “that specific applications could draw on those components to get high performance or a user could dial up perhaps what mixture of accelerators they choose to have on their specific system, according to the applications. It’s about making sure that we have the hardware matching the applications that are intended to run on this machine and having the right mixture.”
He’d noted earlier in his talk how modern systems affect math library development and use.
“Today’s environment for developing numerical libraries is highly parallel, it uses distributed memory. There’s an MPI and OpenMP programming model. It’s heterogeneous using commodity processors and accelerators. It exploits things that avoid simple loop level parallelism and tries to focus on looking at a directed acyclic graph for the computation. The thing to point out is that communication is tremendously expensive on these machines; these machines are over-provisioned for floating point. And the communication is really where we’re spending most of the time. And that has to be taken into account in designing algorithms,” said Dongarra.
“Conventional wisdom would say that if we’re going to decide between two algorithms to use on a machine, one algorithm does more floating point arithmetic than the other algorithm, that conventional wisdom would say we would choose the algorithm that does less floating point arithmetic, but because these machines are over-provisioned, and really, it’s communication that we’re paying for. We really should look deeper and not just focus on the floating point operations, but look at what kind of communication is going on. The other thing we have to realize is that 64-bit computations is what we commonly think of, but machines today are capable of 32-bit, 16-bit, and even eight-bit floating point operations. We should be looking at ways to leverage that increased performance by using this mixture [and] there’s been some pretty good success stories in the linear algebra domain,” said Dongarra.

Another questioner noted the Turing lecture provides an opportunity to discuss what the awardee would like to see happen and what areas might benefit from added investment.
“I’ve harped on the imbalance of the machines today. We build our machines based on commodity off-the-shelf processors, from AMD or Intel, commodity off-the-shelf accelerators, commodity off-the-shelf interconnects. [That’s] commodity stuff. We’re not designing our hardware to the specifics of the applications that are going to be used to drive them. Perhaps we should step back and take a closer look at the how the architecture should interact with the applications, with the software Co-design [is] something we talk about but the reality is very little co-design takes place today with our hardware,” he said.
Citing Fukagu’s impressive efficiency numbers, “Perhaps a better indicator is what’s happening in Japan, where they have much closer interactions with the architects, with the hardware people, to design machines that have a better balance. If I was going to look at forward-looking research projects, I would say maybe we should spin up projects that look at architecture and have the architecture better reflected in the applications.”


Circling back to Dongarra’s comments on winning the ACM A.M. Turing Award, he was eager to spread credit.
“I want to just give a shout out to my mentors, colleagues, generations of postdocs, students, friends, my staff at the University of Tennessee, who push things in the right direction to receive this distinction. I’m incredibly proud of the numerical software libraries that were created, the standards that were put in place, and the performance development tools that we deploy. I feel that this award is a recognition by the computer science community of the importance of HPC in computing, and our collective contributions to computer science. So, congratulations to us.”



























































