 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The ability to scale current computing designs is reaching a breaking point, and chipmakers such as Intel, Qualcomm and AMD are putting their brains together on an alternate architecture to push computing forward.
The chipmakers are coalescing around a sparse computational approach, which involves bringing computing to data instead of vice versa, which is what current computing is built around.
The concept is still far out, but a new design is needed as the current computing model used to scale the world’s fastest supercomputers is unsustainable in the long run, said William Harrod, a program manager at the Intelligence Advanced Research Projects Activity (IARPA), during a keynote at the SC22 conference last week.
The current model is inefficient as it cannot keep up with the proliferation of data. Users need to wait for hours to receive the results of data sent to computing hubs with accelerators and other resources. The new approach will shorten the distance that data travels, process information more efficiently and intelligently, and generate results faster, Harrod said during the keynote.
“There needs to be an open discussion because we’re transitioning from a world of dense computation… into a world of sparse computation. It is a big transition, and companies are not going to move forward with changing designs until we can verify and validate these ideas,” Harrod said.
One of the goals behind the sparse computing* approach is to generate results in close to real-time or in short time, and see the results as the data is changing, said Harrod, who previously ran research programs at the Department of Energy that ultimately led to the development of exascale systems.
The current computing architecture pushes all data and computing problems – big and small – over networks into a web of processors, accelerators and memory substructures. There are more efficient ways to solve problems, Harrod said.

The intent of a sparse computing system is to solve the data-movement problem. Current network designs and interfaces could bog down computing by making data move over long distances. Sparse computing cuts the distance that data travels, processing it smartly on the nearest chips, and placing equal emphasis on software and hardware.
“I don’t see the future as relying on just getting a better accelerator, because getting a better accelerator won’t solve the data movement problem. In fact, most likely, the accelerator is going to be some sort of standard interface to the rest of the system that is not designed at all for this problem,” Harrod said.
Harrod learned a lot from designing exascale systems. One takeaway was that scaling up computing speed under the current computing architecture – which is modeled around on the von Neumann architecture – wouldn’t be feasible in the long run.
Another conclusion was that energy costs of moving data over long distances amounted to wastage. The Department of Energy’s original goal was to create an exascale system in the 2015-2016 timeframe running at 20 megawatts, but it took a lot longer. The world’s first exascale system, Frontier, which cracked the Top500 list earlier this year, draws 21 megawatts.
“We have incredibly sparse data sets, and the operations that are performed on the datasets are very few. So you do a lot of movement of data, but you don’t get a lot of operations out of it. What you really want to do is efficiently move the data,” Harrod said.
Not every computing problem is equal, and sticking small and big problems on GPUs is not always the answer, Harrod said. In a dense computing model, moving smaller problems into high-performance accelerators is inefficient.
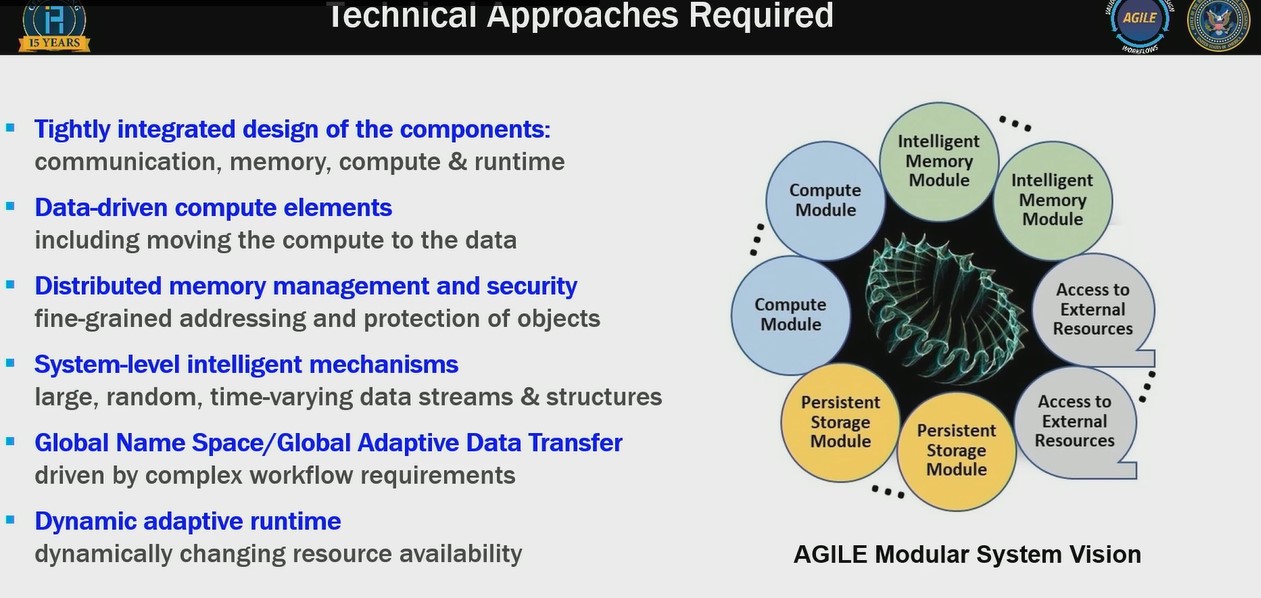
IARPA’s computing initiative, called AGILE (short for Advanced Graphical Intelligence Logical Computing Environment), is designed to “define the future of computing based on the data movement problem, not on floating point units of ALUs,” Harrod said.
Computation relies typically on generating results from unstructured data distributed over a wide network of sources. The sparse computing model involves breaking up the dense model into a more distributed and asynchronous computing system where computing comes to data where it is needed. The assumption is that localized computation does a better job and reduces the data travel time.
The software weighs equally, with a focus on applications like graph analytics, where the strength between data connections is continuously analyzed. The sparse computing model also applies to machine learning, statistical methods, linear algebra and data filtering.
IARPA signed six contracts with organizations that include AMD, Georgia Tech, Indiana University, Intel Federal LLC, Qualcomm, University of Chicago on the best approach to developing the non-von Neumann computing model.
“There’s going to be an open discussion of the ideas that are being funded,” Harrod said.

The proposals suggest technological approaches such as the development of data-driven compute elements, and some of those technologies are already there, like CPUs with HBM memory and memory modules on substrates, Harrod said, adding “it doesn’t solve all the problems we have here, but it is a step in that direction.”
The second technological approach involves intelligent mechanisms to move data. “It’s not just a question of a floating point sitting there doing load storage – that’s not an intelligent mechanism for moving data around,” Harrod said.
Most importantly there needs to be a focus on the runtime system as an orchestrator of the sparse computing system.
“The assumption here is that these systems are doing something all the time. You really need to have something that is looking to see what is happening. You don’t want to have to be a programmer who takes total control of all this – then we’re all in serious trouble,” Harrod said.
The runtime will be important in creating the real-time nature of the computing environment.
“We want to be in a predictive environment versus a forensic environment,” Harrod said.
The proposals will need to be verified and validated via tools like FireSim, which measures the performance of novel architectures, Harrod said.
Approaches of the six partners (aka Performers in IARPA-speak):
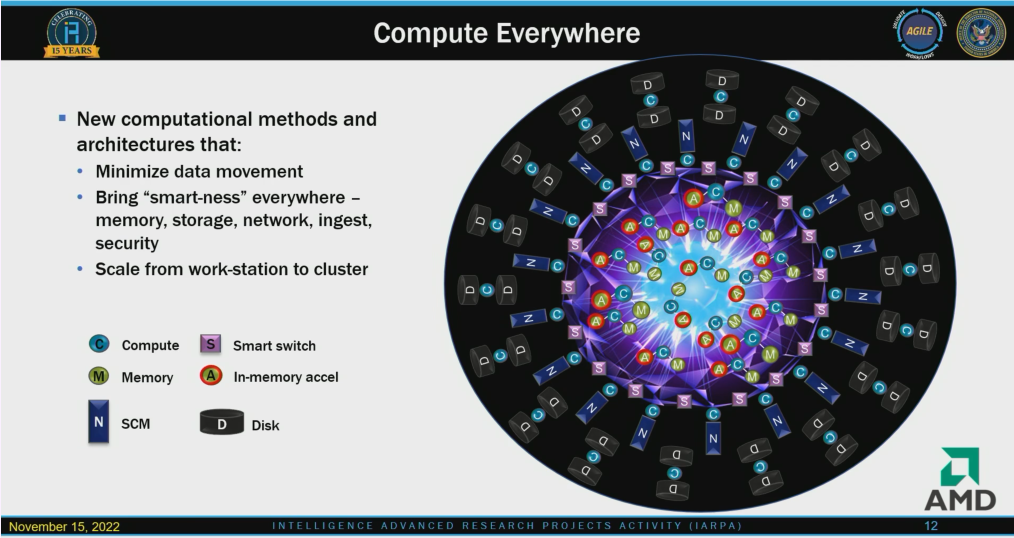

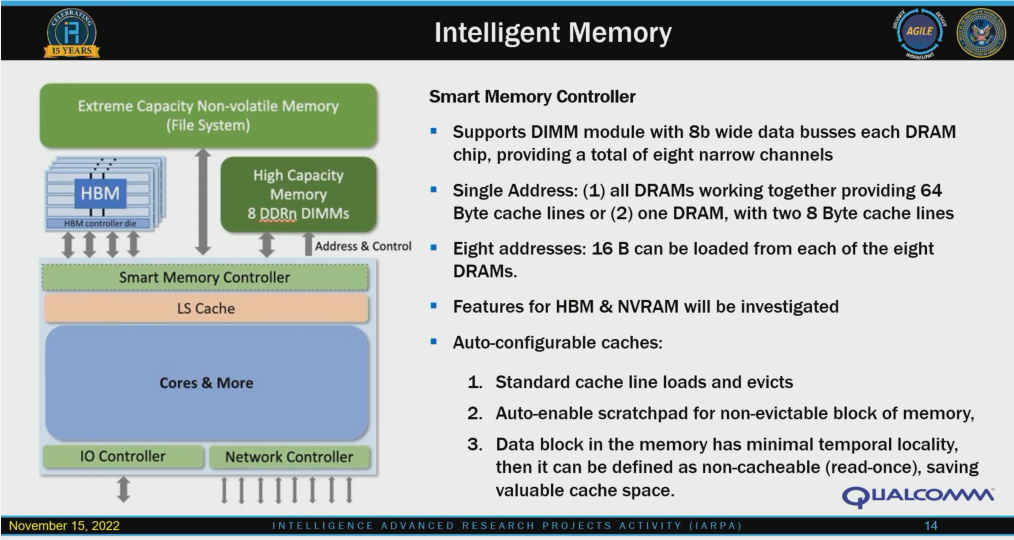



* Sparse computing here is distinct from the established concept of “sparsity” in HPC and AI, in which a matrix structure is sparse if it contains mostly zeros.


























































