 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The Frontier supercomputer – still fresh off its chart-topping 1.1 Linpack exaflops run and maintaining its number-one spot on the Top500 list – was still very much in the spotlight at SC22 in Dallas last month. Six months after Frontier achieved exascale and Top500 glory at ISC 2022 in Hamburg, details of the HPE-AMD system’s nail-biting Linpack finish were still being spilled. While there’s no doubt the crossing of the exascale milestone was an extraordinarily exciting achievement for the Frontier team and the DOE’s Oak Ridge National Laboratory, the story of how that goal was met even more importantly underscores the utility of the High Performance Linpack (HPL) benchmark as a means of shaking out a machine – ensuring all of the hardware and software comes together as intended into an instrument for solving grand scientific challenges.

At the SC22 Top500 birds-of-a-feather, Scott Atchley (system architecture lead at Oak Ridge National Laboratory) provided a play-by-play of the painstaking process of standing up the system and getting 9,000+ nodes to work as a single unified entity. In what was unquestionably an all-hands team effort, involving over 100 core contributors, one of the hero roles was played by HPE’s Nic Dubé, SVP at HPE and technical deployment lead for the Frontier supercomputer. Dubé devised a diagnostic tool that was a cornerstone of the troubleshooting process, providing a real-time visualization of Frontier’s progress.
“We have millions and millions of components in a system this size and you have to shake the system out, you have to find the marginal hardware, and we did so with the help of HPE’s Nic Dubé,” said Atchley at the Top500 BoF. “Nic and his team put together a diagnostic tool [that] represents all of the cabinets in Frontier, and each of the little dots is one of the nodes. And Nic implemented a testing routine that would stress this system 24 hours a day. It used HPL as its primary measuring stick, but it also used things like STREAM and some MPI benchmarks. We were hitting all the components of the system, but HPL was the big part of it.
“The different colors represented where that node was. If it was completely dark, it was powered down. If it was light gray, it was powered up, but no test running, and then once the test started running, then you got the different colors. Green meant that it was passing its single node performance. And blue meant that a full cabinet was passing. This is all HPL that’s being reported. Other dashboards looked at thermals, looked at GPU temperatures, GPU memory temperatures, CPU memory temperatures, but this was the one that we watched on a daily basis to see the progress of the machine coming together. And as we started making more progress, more cabinets came online and went green and then blue. Blue was good. And then once they started running multi-cabinet HPL, then the colors changed to pink and purple. So we could at any time pull this up and see how things were going on Frontier and we knew things were going well when the lights started to flicker,” said Atchley.
Watch Dube tell the rest of story in his own words in this video interview conducted at SC22. The lightly-edited transcript appears further down.
Frontier is approaching acceptance and is on track to enter production starting in January 2023. It has exceeded its performance goals on two Exascale Computing Project (ECP) applications, with WarpX achieving a 110x speedup and Exasky achieving a 271x speedup over the Titan supercomputer (the minimum requirement was to deliver a 50x improvement over that former Oak Ridge supercomputer). Frontier was also used by two Gordon Bell Prize finalist research groups, including the winning team, which used “up to 8,192 nodes” of Frontier to to conduct in-depth research on plasma accelerator technologies.
If you are a registered SC22 attendee, you can also view the Top500 BoF recording.
Tiffany Trader: We’re here in Dallas at Supercomputing, SC22, and joining me is Nic Dubé, senior fellow and chief architect at Hewlett Packard Enterprise. Nic is also the lead technical deployment of the Oak Ridge Frontier supercomputer, a DOE, HPE, AMD collaboration. Nic, we were both at the Top500 BoF last night. It was really great. And one of the lead, key speakers there was Scott Atchley, HPC systems engineer at Oak Ridge. And I didn’t realize until his talk – I knew some of the details, the behind the scenes details, but this was the most detailed that I had heard yet. A fascinating talk about the intense period of benchmarking and troubleshooting that led up to the eventual crossing of the exascale threshold, this heroic effort to get over that exaflops finish line. And what I learned is that you have something of a hero role in this story, going on site, living on site and developing these management tools that specifically ended up providing the visibility that led to a critical fix. Scott Atchley said the performance management tool that you designed had amazing resolution beyond any capability that they’ve had before. So I’d like to hand it off to you to share what happened, and some of those details, and what that was like.
 Nic Dubé: The story is actually quite amazing, and it’s an untold story. For the first time yesterday Scott actually mentioned some pieces of it. Many of us ended up kind of going to Oak Ridge at the end of February, early March because well, May was coming fast, you know, and this year, the Top500 for ISC was almost a month sooner because ISC was almost a month sooner, usually it’s at the end of June. And you know, bringing up Frontier, it’s not only the largest system ever built, but it’s the first of its class, right, with a brand new fabric of that scale, new infrastructure, new AMD GPU, new software. So there was new on top of new on top of new, and then being the largest one in the world. Well, it sets up for very interesting challenges. But we were basically in a, alright we’re throwing everything we have at it [moment]. I was very fortunate to lead the team. It was amazing, but it was a huge team. We had over 100 people working on this. We worked on it around the clock; we had people literally working on the system around the clock, and it started with getting the infrastructure solid and going, and then what you were talking about, the dashboard. For a system the size of Frontier, a lot of the monitoring tools just don’t comprehend a system that has like 40,000 GPUs because it’s so big – the data ingest – just to capture the data – all of the feeds that are coming from the performance of the nodes – is massive. So we designed a new tool and you saw it yesterday at Scott’s presentation, with a dashboard, every node in the rack had a colored dot, and we started by what we called greening up the racks right. Green meant all the nodes were performing individually, and then we blued up the rack, which meant that the rack was performing normally at the rack level. And then we moved up at the row and then at the system level.
Nic Dubé: The story is actually quite amazing, and it’s an untold story. For the first time yesterday Scott actually mentioned some pieces of it. Many of us ended up kind of going to Oak Ridge at the end of February, early March because well, May was coming fast, you know, and this year, the Top500 for ISC was almost a month sooner because ISC was almost a month sooner, usually it’s at the end of June. And you know, bringing up Frontier, it’s not only the largest system ever built, but it’s the first of its class, right, with a brand new fabric of that scale, new infrastructure, new AMD GPU, new software. So there was new on top of new on top of new, and then being the largest one in the world. Well, it sets up for very interesting challenges. But we were basically in a, alright we’re throwing everything we have at it [moment]. I was very fortunate to lead the team. It was amazing, but it was a huge team. We had over 100 people working on this. We worked on it around the clock; we had people literally working on the system around the clock, and it started with getting the infrastructure solid and going, and then what you were talking about, the dashboard. For a system the size of Frontier, a lot of the monitoring tools just don’t comprehend a system that has like 40,000 GPUs because it’s so big – the data ingest – just to capture the data – all of the feeds that are coming from the performance of the nodes – is massive. So we designed a new tool and you saw it yesterday at Scott’s presentation, with a dashboard, every node in the rack had a colored dot, and we started by what we called greening up the racks right. Green meant all the nodes were performing individually, and then we blued up the rack, which meant that the rack was performing normally at the rack level. And then we moved up at the row and then at the system level.
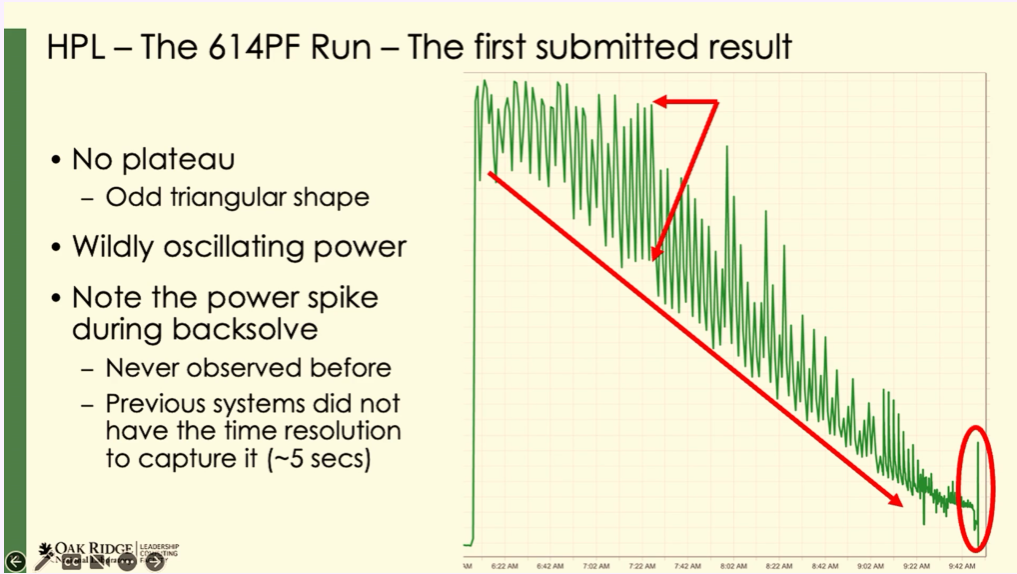
We overcame many things, and what people don’t realize is that… people are like oh my god, you guys, it’s like a miracle what you guys did, and I’m like no, no, no, a system the scale of Frontier is statistically very, very difficult to make and come together and work for an extended period of time without any failure. And people that build smaller systems or that are not in our business sometimes don’t fully comprehend that. But you’re like 40,000 GPUs just the high memory bandwidth you’re looking at 2.4 million memory chips. And for the Linpack run that lasted about three and a half hours, that means you got zero failure, or whatever failure you get, you have the resiliency put in place then you come on top of it. So that’s a pretty amazing accomplishment that the team pulled off. We cut it really tight. Towards the end, and Scott mentioned that yesterday, we kind of had, we called it a sawtooth problem. And it was caused by a setting, a default setting in the lib fabrics driver that when we tune, then the system really performed. It’s an option that actually if you read the manual pages, it tells you this option might lower performance. In a nutshell basically, the system will run over 20 megawatts when it’s running flat out, but we were seeing swings that were like eight to 10 megawatts every five minutes. And it was linear. Usually, you know, when you run a system at scale and you’d have what we call the calm pattern and you see spikes, everybody stops, spikes. That means you have a straggler, you find the straggler, this system comes together, you perform, but this was a sawtooth, it was going on like that [shows with hands, see graphic on left]. And it meant that the GPUs were kind of running out of work, one after the other. So we were looking at different matrices, how to position the job, and ultimately we got the team together and we’re like okay guys, it’s something we’ve never seen. It’s something different. And Kim McMahon on our team, who’s one of our rockstar MPI engineers, she started digging into it with the rest of the team and she said, how about we flip that, and then the system got there.
Trader: And you went from 600 to 900 (petaflops).

Dubé: Because that was only 8,192 nodes. Because at the time there were a number of racks that we had kind of broken out from the big system to do other tests. So they had different firmware versions. They had different, all sorts of different settings. What was beautiful – so that was on May 26 that Kim and the team had the aha moment – and then all of the team we started a Teams call and all the engineers kind of came together and what was great is that okay, we need to flash that firmware and then one of the guys would pick it up, okay, we need to remount Lustre there. And by that time the team was like an engine, it was like gears that were all clicking together. And within a matter of two to three hours, we basically rebuilt the system. We re-integrated all of the racks that we had forked out, we re-baselined it, and then we told Kim and the performance team, alright test the fabric, greenlight, fabric is good. We almost made it on May 26. We fail in a backsolve of the run. We were at 95% and then the backsolve failed. And then we had a few tries during the night, and then I remember, many of us that night didn’t sleep much. And I remember kind of somewhat waking up at five in the morning and I’m still in my bed on my phone, tailing the run on the logs. Looking at the power curve and it’s good. And I go on Slack, because we had a big Slack channel, and I’m like, Oh, this one is looking good. And then Scott is like “Nic, don’t jinx it.” And then it’s coming, and after the end of the run, we call them the tail and then like the tail is looking like it’s gonna end over an exaflop and then the number comes out and then you need to pass the residual test, meaning that the run needs to be precise, and that was one of the most numerically accurate, precise runs that we did on the system. So I’m literally, 6:15am, May 27, I’ll remember that 6:15am my whole life. I was literally jumping in my bed crying. I’m still emotional about it. So it was yeah, it’s an accomplishment of a lifetime for many of us.

Dubé: Yeah, we had the dashboard, everybody loaded up the dashboard. I can talk of my family, but I think it’s true from all of us that that kind of lived at Oak Ridge. It’s not just the team. It’s all of our families that supported it.
Trader: And of course I’m referring to Justin Whitt, the project manager for Frontier. And after the backsolve, was there one more test after that you had to get through?
Dubé: It’s called a residual test. You need to – basically Linpack run will test for numerical accuracy. And the way I explain that to people that are not in our field, they’re like, Oh, how can that be, aren’t supercomputers always numerically accurate? And it’s like well, you know, you’re dealing with silicon. And the best way to explain that is remember your math class when you were in high school and your teacher said, you know, when you’re doing calculations on your calculator, make sure you keep all the digits after the decimal. Well imagine a supercomputer is doing a billion, billion calculations per second. If there’s only one bit that flips, the error multiplies really fast. And that’s why when you do a large scale Linpack run, it’s not just about getting the number, but it’s also testing it to make sure it’s numerically precise, and basically validating that you really got the right answer. And on that run, it was one of our best runs. And so we were really celebrating. It was amazing.
Trader: It’s a great story. So speaking of the Linpack run – the official run was 1.1 exaflops out of 1.7 exaflops peak. And I think you have some thoughts about the Linpack efficiency – it’s 65% and you have thoughts on how it could could be higher.
Dubé: So remember, I mean when when the list – it goes the other way in this case – but you know, the peak is basically a mathematically calculated equation. So in this case, you look at the number, the GPUs have 220 compute units times 0.8 gigahertz times 256 flops per core per clock, and then you multiply by the number of GPUs and then you add the CPUs and that’s giving you the peak number. So you do the ratio. However, what you really want to look at is how efficient are you at the node level like individually because what you want to compare is weak scaling to strong scaling. So at the node level, what you’re looking at is – the run ended up being on 9,248 nodes. Out of the 9,248 nodes, there’s a distribution, right, of the node performance taken individually and always the slowest one of all of them is actually going to be the last one to come in and the barriers during the run. If you look at this and you basically do a Linpack efficiency from multiplication of the individual node performance times the total number of nodes versus the strong scaling run, the system is actually 85% efficient, and I think that’s a more accurate measurement of the fabric efficiency.
The other way to look at it is when during the first part of an HPL run before that tail, Frontier was actually running at 1.4 exaflop. And we were monitoring the fabric; there was no back pressure, the fabric was just kicking it. And the reason for that is really because in a way, well one, the Slingshot fabric performed, but two, HPL doesn’t stress the fabric that much. And we kind of proved it again, even on an exascale system. So I’m not making the point for building lightweight fabric, Slingshot is a plenty capable fabric and I think for applications in general, we need to build great capable systems. But in this case, you know that the real way to measure the efficiency actually leads to an 85% efficiency.
Trader: Do you see some headroom to increase the Linpack score and would you deploy a different configuration? Would you add some of those other nodes back in? [Ed note: The current Top500 implementation has 9,248 nodes, but the full system has 9,408 nodes.]
Dubé: Maybe we could. Honestly, this is a system that if you ask my own personal opinion, this is a system that was designed for science. Already on some of the ECP apps, we’re seeing over 100x improvement, and that’s what that system has to be used for. And you know, just the power that goes into that system, I think it should be used to run science rather than benchmarks.
Trader: And speaking of power, Frontier did very well on the Green500 as well. Frontier, along with its companion system, one and two when they debuted on the list, and still have a significant showing on the current list. There are seven HPE systems in the top ten of the current Green500 list that came out here at the show. You hit that DARPA target that got set, you know, 15 years ago, came in under that 20 megawatts at exascale.
Dubé: So we did basically 1.102 exaflops in 21 megawatts, so we’re just slightly over 19 megawatts. Honestly, that’s a target… I’ve been working on exascale through PathForward and all that on the research for over a decade. I never thought we’d hit that target. That was the one I was like, yeah, we’re never gonna make it in 20 megawatts. So when it came in, I’m like oh my god, we made 20 megawatts. So that was a great outcome.
Trader: You benchmarked for the HPCG this year, the High Performance Conjugate Gradients benchmark, a ranking that measures data movement and has notoriously low efficiency of peak, just how it is, the top one (Fugaku) is 3%. The second one (Frontier) is 0.8%. Thoughts on the importance of HPCG, stressing data movement, and if design should go in a direction [that would achieve better HPCG results].
Dubé: So the Japanese systems, like at Riken… the Japanese have always built more fabric rich systems, and that goes all the way back to the Earth Simulator and I think it’s basically a different design point. There are tons of arguments in the community about the trade off there. It’s almost like you put two geeks around beers and you debate around VI and Emacs. I mean, both points are actually great. I think, if you look at Frontier, you really want to look at the performance of the apps. It actually really pays out, but really it pays out because a lot of the work that was done in the ECP, it’s all about overlapping compute with communications. If you’re able to do that, you’re gonna be using your interconnect very efficiently for the flops you get, and so far, right, the application community and the scientific community has been able to keep improving the application. So although as a system engineer, I’d like to build systems that are more capable that have always-richer fabrics, so far, the speedups we’re getting on applications, even the flops-to-interconnect-bandwidth ratio, the flops is skyrocketing. It’s kind of proving that we still have room to improve our apps and crank out the most out of it.
Trader: As you pointed out, we love to talk about the hardware, but it’s all in service to a greater mission, which is the science and solving some of the grand challenges of humanity. Another way that you’re working on that is through this internet of workflows that I’ve heard you talk about. Could you talk about your vision for internet of workflows and what HPE is doing to to bring that to fruition?
Dubé: Really, people are like, okay, what comes after exascale, and I’m not gonna say the Z word this morning.
Trader: It’s a little early.
Dubé: Right. I think really, what comes after exascale is kind of a system of systems. If you look at the operating model that we’ve been having in high performance computing for like forever, it’s really kind of an island with almost like an airgapped security around the system. So for anyone to compute on a supercomputer, you log in, or you VPN in, you upload your data, you do your compute, and once you’re done, you kind of egress out. Let me give you a great example of where I think that as a community we’re headed. There’s a group that’s in San Diego at San Diego Supercomputer Center that’s called WIFIRE. What they do is that they have infrared and visible cameras on airplanes that are flying over California to basically detect ignition to detect if there’s a fire that may happen at any point in time. And I mean, I know you’re from California.
Trader: I’m from San Diego.
Dubé: So for people there, that’s a very critical workflow. And what happens is that when it detects ignition, that’s like intelligence at the edge, if you will, in this case it’s on an airplane, it tells the pilot to fly around to capture more video, but what’s really interesting is that then it sends all of the data, the temperature, the wind, the video feeds to San Diego Supercomputer Center, and in real time, they basically compute fire propagation models for like 15-minutes, 30-minutes, 45-minutes, an hour, because they’ve built a whole model of California and for every acre, they know the amount of fuel and fuel in this case is like either you know, woods, or houses or things like that. And they’ve modeled the level of drought, the wind, the temperature conditions, and with that, they’re able to build that model and tell the fire chief, a local fire chief, hey, here’s what the fire will look like in 15 minutes and 30 minutes and 45 minutes. So the local authorities can go, okay, if we can get to the fire within 15 minutes, we’ll be able to contain it like that. If we can’t get there before 45, we need to call the C-130s, basically the big stuff, to try to put it out. And that’s for me, one of the most vivid examples of the internet of workflows, which is coupling data feeds that are coming in real time with supercomputing models to actually have a real outcome on people’s lives. And I really think that’s where we’re going next. It’s all about coupling exascale supercomputers and smaller ones, together with sensors and then producing real-time output, in this case to save property and people’s lives.
Trader: Yeah, that’s a great example and shout out to the lead there: İlkay Altıntaş. And that’s just one example. You know, the time that we’re living in with climate change and everything, you know, we really need these solutions that have a direct impact on our life, our property our economic situation. I’m sure there’ll be lessons learned to carry over to other grand challenges.
So here we are at SC22 in Dallas. Feels like back to the usual times of SC.
Dubé: I think we’re all happy we can get together.
Trader: Yes, there’s a lot of excitement, enthusiasm, energy, activity, great conversations, meeting people I haven’t seen in quite a few years, including yourself. So what are some of your SC highlights here or other memorable SC highlights or just how you’re finding the event here?
Dubé: Well, I mean, look for us, ISC was was still kind of on the smaller side. Obviously, we had the exascale run for ISC in Hamburg, but we’re kind of still almost partying here with being in the U.S. So we’re really happy about that. But if you go to the HPE booth, it’s all around the Spaceborne computer and how we’re gonna go to moon exploration.
Trader: Speaking of flipping bits.
Dubé: Yep, exactly. There you go. So, ultimately, what we’re really looking at and what people are telling us is capability computing, people are looking for ways to really consume it on demand, and people want to burst for capacity, but a lot of folks are also coming into burst for diversity, because a lot of our community will still build supercomputers on prem – that may be of architecture X, Y, or Z, but they’re like, yeah, but we’d like to run on that AI accelerator when we need it or that GPU accelerator when we need it. So at HPE, we’re working with the community to look at – and it’s coupled with the internet of workflows – but basically meta-orchestration between sites, and also providing that on-demand capability computing to our user base. And we’re talking to our customers with that; we’re not going full press release about that yet. But you can see how the internet of workflows vision is gelling with some of the stuff we’re working on in R&D.
Trader: So there’s this holistic vision from the top supercomputers to the internet of workflows to the cloud and enabling all these different kinds of workflows.
Dubé: It’s kind of a rebirth of the grid. Right? Remember the grid back then, over a decade ago.
Trader: I’m even hearing the word federation again.
Dubé: Yeah, so it’s federations of systems, and honestly I think that’s the way forward because there’s such a diversity of silicon and software and now workloads, and the workloads – it’s not just, you know, doing modeling and simulation kind of in isolation. It’s coupling it with machine learning models. I mean, you might have radio telescopes that will have data that’s being fed in and then being pre-processed by a DSP and that’s then fed into a simulation model, and that simulation might be steered by machine learning. All of those are all now…
Trader: Throw in some optical photonics in there.
Dubé: Yeah, well as you know, we’ve been working quite a bit on that. That’s definitely part of our future. And by the way, that’s also the way to build highly capable supercomputers. And we’re gonna see more and more optics into our systems in the coming years.
Trader: Nic, there’s so much more we could talk about; we’re gonna save it for next time. It’s been great talking to you and thanks everybody for watching. See you next time.

























































