 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Brazil’s state-owned petroleum corporation, Petrobras, has been on a roll for the past few years, launching system after system to the Top500 and carving out a prominent name for itself in the HPC world. At the HPC-AI Advisory Council’s 14th Annual Stanford Conference this week, Luiz Monnerat, IT master advisor for Petrobras, discussed the company’s history with and commitment to HPC.

HPC, Monnerat explained, was essential for both oil and gas exploration and for positioning the individual wells. Drilling a well is an extraordinarily expensive process, particularly offshore – Monnerat cited the cost for each well at up to $50 million, adding that Petrobras plans hundreds of offshore wells in the next five years, totaling some $10 billion or more. “The oil wells are not the only reason [we have HPC],” he said, “but even if they were the only reason, they are quite a relevant reason for us to have HPC.”
“But please note that it doesn’t mean that computers find oil by themselves, or even that they are able to create the images of the subsurface by themselves,” he hedged. “Our supercomputers are indeed very powerful tools – that are used by our technicians to generate better images and better reservoir simulations, improving the quality of the information we need for very critical decisions for our business.”
Petrobras’ HPC needs
The two main workloads for these tasks: seismic processing and reservoir simulation, which Monnerat simply referred to as “seismic” and “reservoir” for much of the talk. “Most of our capacity – in fact, more than 90% of our capacity – is dedicated to seismic processing and reservoir simulation,” he said.
The bulk of that capacity – Monnerat said upwards of 80% – is dedicated to seismic processing. “Which doesn’t mean that seismic is more important than reservoir or other demands,” he added. “It really means that the seismic applications are much more compute-intensive.”
Seismic workloads, he said, are single-precision and apply very large datasets across several different applications. Those applications – the most compute-intensive at Petrobras – are developed in-house because “the most critical seismic applications are not available commercially.” To support these workloads, Petrobras employs predominantly GPU-based processing (“At least 80% of our processing capacity is based on GPUs,” Monnerat said) that is dedicated almost wholly to its in-house seismic applications.
“We basically don’t use GPUs for reservoir,” Monnerat continued. Those workloads, he said, typically leveraged commercial applications and ran at double-precision with much smaller datasets – though several hundred reservoir jobs typically run parallel to one another.
A long history with computing
Monnerat said that Petrobras had been leveraging computation for its oil and gas work as far back as 1969. When Monnerat himself started working at Petrobras in the ‘80s, the company was using IBM mainframes – then, in the ‘90s, RISC-based machines. The first x86 machine at Petrobras went online in the late 90s, and by 2007, Petrobras was comparing compute solutions like FPGAs, GPUs, and the processors inside the PlayStation 3. Obviously, Monnerat said, the GPUs won the contest: “We were able to have our first GPU cluster by the end of 2008.”
Petrobras’ steady investment in computing and HPC – including its early lead on the GPU front – was interrupted when the oil prices dropped in the mid-2010s and the budgets for HPC work were cut. “Due to the lack of investment, we arrived at 2018 with our HPC infrastructure quite obsolete,” Monnerat said. But that year, they built a plan to revamp their HPC infrastructure – though they had to approach it in waves.
Petrobras’ present (and future) capacity
This brings us more or less to the present day. Monnerat said that the wave-based approach led to some fragmentation, with Petrobras employing more than 10 different clusters. “We could have maybe six or seven,” he said. “It’s not a big issue – it makes things more complex. … We would have some fragmentation anyway, as clusters that are good for reservoir are not good for seismic. … Even inside seismic, we have quite different workloads that require different machines.”
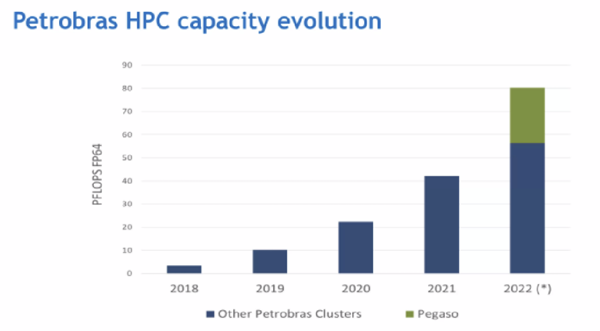
Three of those clusters are dedicated to reservoir work, all of which have similar node structures and all of which are managed more or less as a single cluster. “For seismic,” Monnerat said, “we have … a number of different clusters in a much more complex environment.” Those include Petrobras’ Atos-built heavy-hitters on the Top500: Fênix (3.16 Linpack petaflops, 2019); Atlas (4.38 Linpack petaflops, 2020); Dragão (8.98 Linpack petaflops, 2021); and the most recent entrant, Pégaso (19.07 Linpack petaflops, 2022, ranking 33rd). The systems are split between two datacenters: one proprietary datacenter dedicated fully to HPC, the other rented and hosting a variety of workloads.

If you noted the years of those systems, you might have noticed a pattern: Petrobras has launched a new major system every year for the past four years, continually one-upping itself with a new biggest supercomputer in Latin America. In 2018, Monnerat said, the company had just three petaflops of computing capacity. One year later, that had tripled. Two years after that, it had tripled again. Petrobras now has ~20× the computing capacity it had when it set out on its revitalized HPC journey.
Petrobras isn’t stopping, either: less than a month ago, the company announced its Dell-built “Gaia” system, which will deliver 7.7 peak petaflops that will be used for seismic imaging research rather than the production workloads that run on the bulk of Petrobras’ other systems. Petrobras is also looking into cloud applications – though, Monnerat said, cloud can be expensive to use if not approached with care. “One big problem that we have is that porting seismic to the cloud is quite complex and it may take several years,” he added – so, for now, Petrobras is working on running reservoir and machine learning workloads in the cloud.
























































