 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Enabling interoperability across U.S. exascale supercomputers is one of the chief goals for the U.S. Exascale Computing Project (ECP), which has broadly overseen development of the early software ecosystem needed to support the new class of supercomputers. Earlier this month, ECP held its annual community BOF days, a virtual event spanning a wide range of topics – including a session on SYCL, which has been gaining momentum as a programming framework for heterogeneous computing.
The rise of heterogeneous computing (typically CPU/GPU pairings) is the big challenge that many hope SYCL can help address, and the first round of U.S. exascale supercomputers is something of a poster child for that challenge.
Frontier, the first U.S. exascale system, is now up and running at the Oak Ridge Leadership Computing Facility (OLCF), and El Capitan, the third scheduled system (hosted by Lawrence Livermore National Laboratory), both use CPU/GPU pairings from AMD. Aurora, which is now being stood up at Argonne Leadership Computing Facility (ALCF), will use an Intel CPU/GPU. Add to this the practical reality that virtually all of the big pre-exascale systems, such as Perlmutter at the National Energy Research Scientific Computing Center (NERSC), use Nvidia GPUs, and you get a sense of the challenge to maintain interoperability.
As the number of accelerators – mostly GPUs – has grown, so has the number of programming models created to support them. Currently, CUDA (Nvidia), ROCm with HIP (AMD), and most recently SYCL/oneAPI (Intel) are the big players. Others will likely emerge as more vendors bring GPUs and other accelerators to market. These tools will need to able to talk to each other in productive ways to wring maximum value from exascale systems and other major supercomputers.

At the core of ECP’s recent SYCL BOF were lightning talks from ALCF, OCLF, and NERSC on their efforts to support interoperability, as well as a somewhat longer update from Intel – a SYCL/oneAPI driver – on SYCL’s evolving feature set. Unfortunately, the sessions were not recorded, but BOF leader Abhishek Bagusetty, a computer scientist at ACLF, said he would compile the slides and make them available.
By way of quick background, SYCL is a royalty-free, cross-platform abstraction layer that builds on the underlying concepts, portability and efficiency from OpenCL. The idea is to enable code for heterogeneous processors to be written in a “single-source” style using standard C++. Intel introduced DPC++ (data parallel C++) based on SYCL and used it in the oneAPI framework that will be used with Aurora. SYCL itself is a Khronos Group project begun in 2014, and Codeplay is the company that’s been most involved in SYCL development. The latest version is SYCL 2020.
Here’s the Khronos description:
“SYCL defines abstractions to enable heterogeneous device programming, an important capability in the modern world which has not yet been solved directly in ISO C++. SYCL has evolved with the intent of influencing C++ direction around heterogeneous compute by creating productized proof points that can be considered in the context of C++ evolution.
“A major goal of SYCL is to enable different heterogeneous devices to be used in a single application — for example simultaneous use of CPUs, GPUs, and FPGAs. Although optimized kernel code may differ across the architectures (since SYCL does not guarantee automatic and perfect performance portability across architectures), it provides a consistent language, APIs, and ecosystem in which to write and tune code for accelerator architectures. An application can coherently define variants of code optimized for architectures of interest, and can find and dispatch code to those architectures.
“SYCL uses generic programming with templates and generic lambda functions to enable higher-level application software to be cleanly coded with optimized acceleration of kernel code across an extensive range of acceleration backend APIs, such as OpenCL and CUDA.”
Presented here are a few brief comments from ALCF, OLCF, NERSC talks and a bit more from Intel SYCL update.
ALCF – Leveraging oneAPI and CUDA APIs
Not surprisingly, there’s a significant effort readying Aurora for use with oneAPI/SYCL. Bagusetty provided the ALCF briefing.
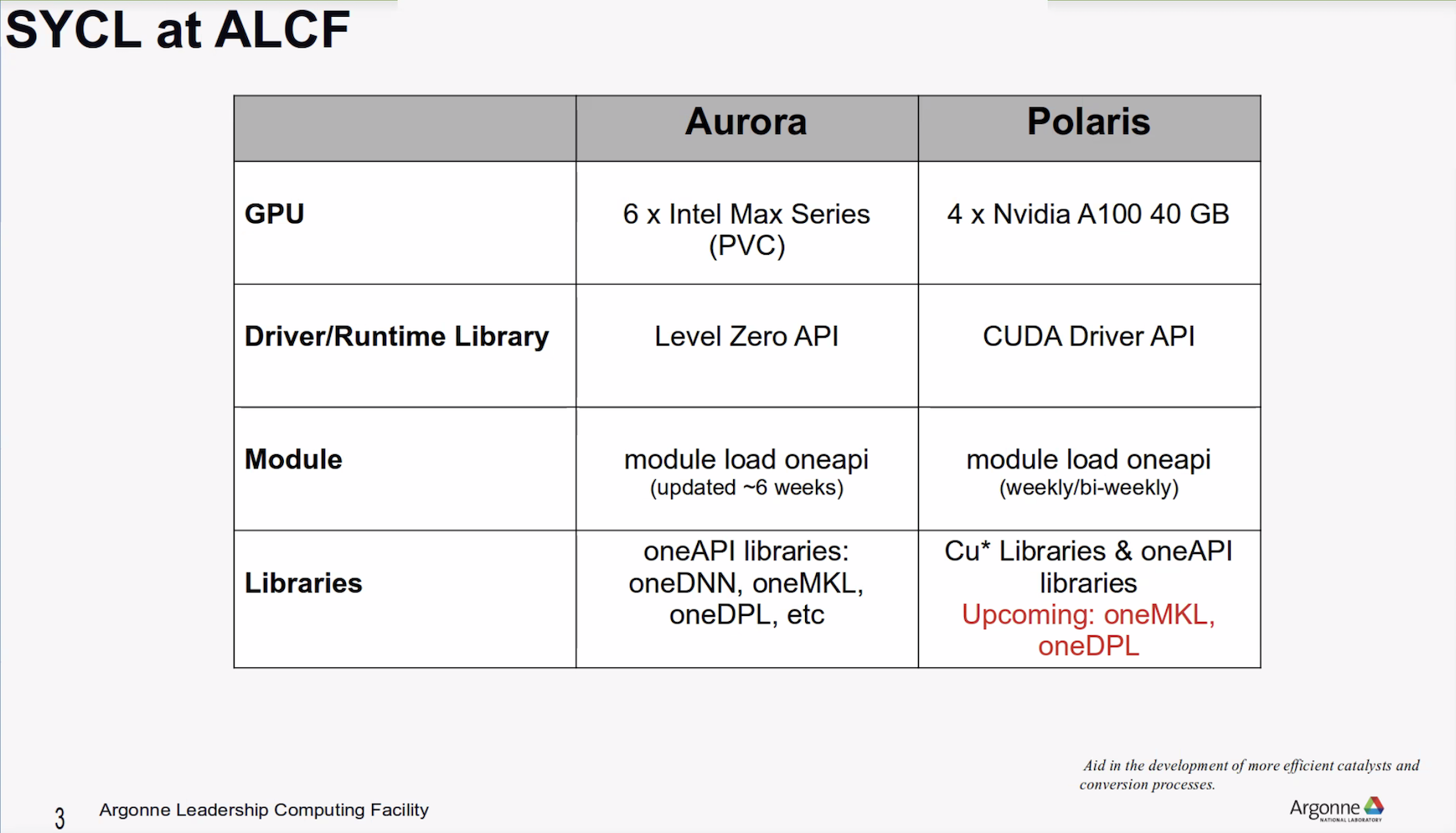
“At ALCF, our natural experience is with Aurora, so we use pre-developed or started developing applications for Aurora. One additional machine that we have is a pre-exascale machine, Polaris, which is a similar architecture to NERSC’s Perlmutter. I’ve listed how SYCL can be used on these two machines at ALCF. One important difference is the driver library; as most of you know LevelZero is the API for Aurora. Similarly, the standard CUDA Driver API’s are the runtime library for Polaris, and that too is driven by SYCL,” said Bagusetty.
“We have modules for ease of access on both of these machines, with different cadences on how they get updated. Aurora has all the libraries that we that we use for the applications. On Polaris, since it’s a CUDA-based machine, we do have cu-based libraries – it could be cu-BLAS, cu-SPARSE, all the math libraries. In addition to oneAPI, which provides a single compiler, currently there is bit of testing going on to make oneMKL and oneDPL available. The first one that will be available is oneMKL. OneDPL is still [undergoing] testing, so watch out for that if you have an application that uses SYCL or oneMKL or oneDPL in that in that space. It’s worth giving it a shot on Polaris and scaling up to several hundreds of nodes,” he said.
OLCF – Working on Prototype DP++ for AMD GPUs
The Frontier exascale system at OCLF is an AMD CPU/GPU machine and relies heavily on AMD’s HIP – Heterogeneous Interface for Portability – as a programming model and tool. Balint Joo, a group leader at OLCF, talked about efforts to also become able to use SYCL to gain interoperability with Aurora.
“There has been interest in DPC++ and SYCL at OLCF. The primary focus is from facilities interoperability. We’d like to be interoperable with Aurora, and this is sort of complementary to the HIP-LZ (HIP on Level Zero) effort at Argonne, which is to have compatibility with HIP from Frontier. This is a potential additional onramp for other applications and libraries. It’s just another way to try getting on if you already have (SYCL) in your code. So this is a risk mitigation exercise. [Thus far] we have part-funded and participated in prototype work with Codeplay, and that was a prototype for DPC++ on AMD GPUs. It’s basically an AMD plugin like the CUDA plugin. Some of us have been doing personal tests in their own directory looking at hipSYCL, which has now become openSYCL,” said Joo.
“In terms of what’s installed on the systems currently, Codeplay does nightly builds of their of their prototype work on Spock, which is an MI100 (AMD GPU) machine here. This is what’s called user managed software. So the modules you need to load are ums for user and then ums15, which I guess is Codeplay’s account there. Then you can use odpcpp and should get a client++, which can compile SYCL on the back end to the extent the features are available in that prototype (see slide below). John Holman has made the public DPC++ installation on Crusher (development system for Frontier). I’m not 100% sure what the difference between that and the prototype is, [but] I suspect they’re the same. If you log on to Crusher, you can just do a module of DPC++ and you can get it (see slide). Right now, we’re in discussions with Codeplay to finish the prototype for Frontier. The prototype already has a lot of features, but it’s not fully-featured. So the plan is to make that the case,” said Joo.

NERSC – Attempts Support for Wide Range of Programming Model
The Perlmutter architecture at NERSC has been optimized for AI workloads and, while not an exascale system, it is formidable at 64.6 petaflops and was number seven on the most recent Top500 List. It uses AMD CPUs and Nvidia GPUs. Brandon Cook, acting group lead for the Programming Environments and Models group at NERSC, provided the update which was quite brief.
“We were supporting sort of every programming model we can and compiler possible. One of the key ones is the Intel LLVM and SYCL programming model. We have a new group that’s focused on this space. Throwing some support behind these types of activities is something that NERSC is doing. Last year I mentioned our prototype LLVM programming environment, which we have found to be very successful [based on] the positive feedback. The maturity of the components has really increased in the past year. We’re currently working on integrating that as the default set of modules that will kind of plug right into the standard Cray Programming Environment.”

INTEL – SYCL Performance on Par with CUDA and HIP
John Pennycook, an application engineer from Intel, had the longest presentation of the BOF and presented snapshots of SYCL conformance, performance against Nvidia and AMD tools, and reviewed the evolving feature set. One sore spot in the latter currently is the lack of formal support for complex numbers and greater than 3-dimensional coding structure in SYCL although there are workarounds.
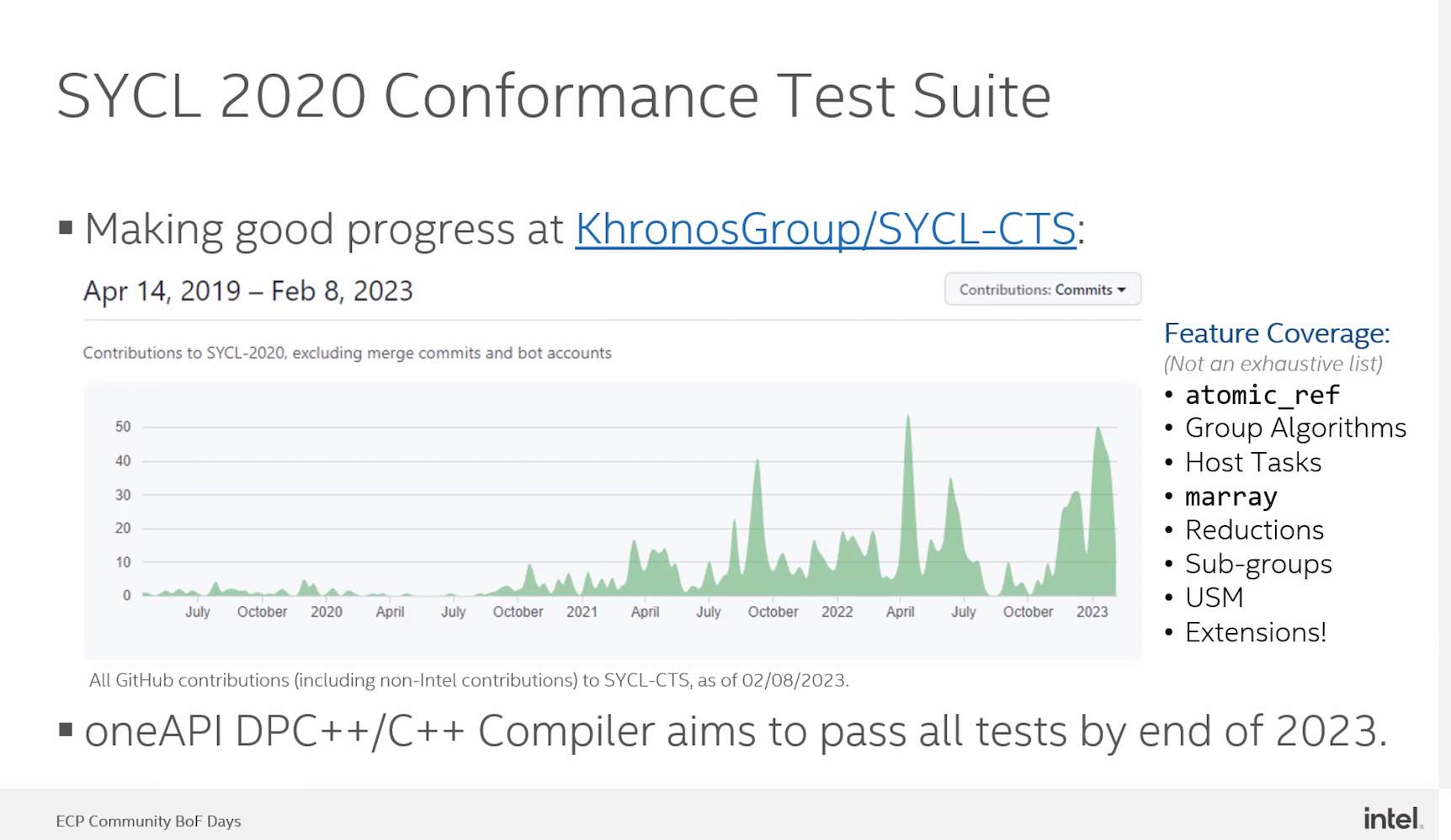
“I want to give a very quick status update on the oneAPI DPC++ compiler, which is the official name of the open source project (SYCL) at Intel. For those of you who may be new to SYCL and Khronos specifications, in general, with a Khronos specification, before an implementer can actually say that they are conformant, or compliant with a particular version of the specification, they have to pass what is known as the conformance test suite, or CTS. SYCL 2020 doesn’t actually have a CTS yet. But Intel is working with contractors and other members of the SYCL Kronos working group to get this CTS ready so that we can start to test all of the different implementations and see if any of them are conforming,” said Pennycook.
“If you look at this graph that I grabbed from GitHub, you can see that over the last two years, we’ve kind of got this steady upward trend in terms of activity in the CTS. I think we’re on track to actually have better coverage in the SYCL 2020 CTS than we did for version 1.2.1. And if you look at the right-hand side of this slide, you can see a list of some of the features we now have tests for. This isn’t an exhaustive list, but stuff I thought would be of interest to this audience. So, things like atomics group algorithms, reductions, subgroups, unified shared memory, we all have tested all of those things now. DPC++ is tracking these tests quite closely. Every time a new test comes out, we want to aim to pass it as quickly as we can. And we aim to pass all of the tests by the end of 2023.”
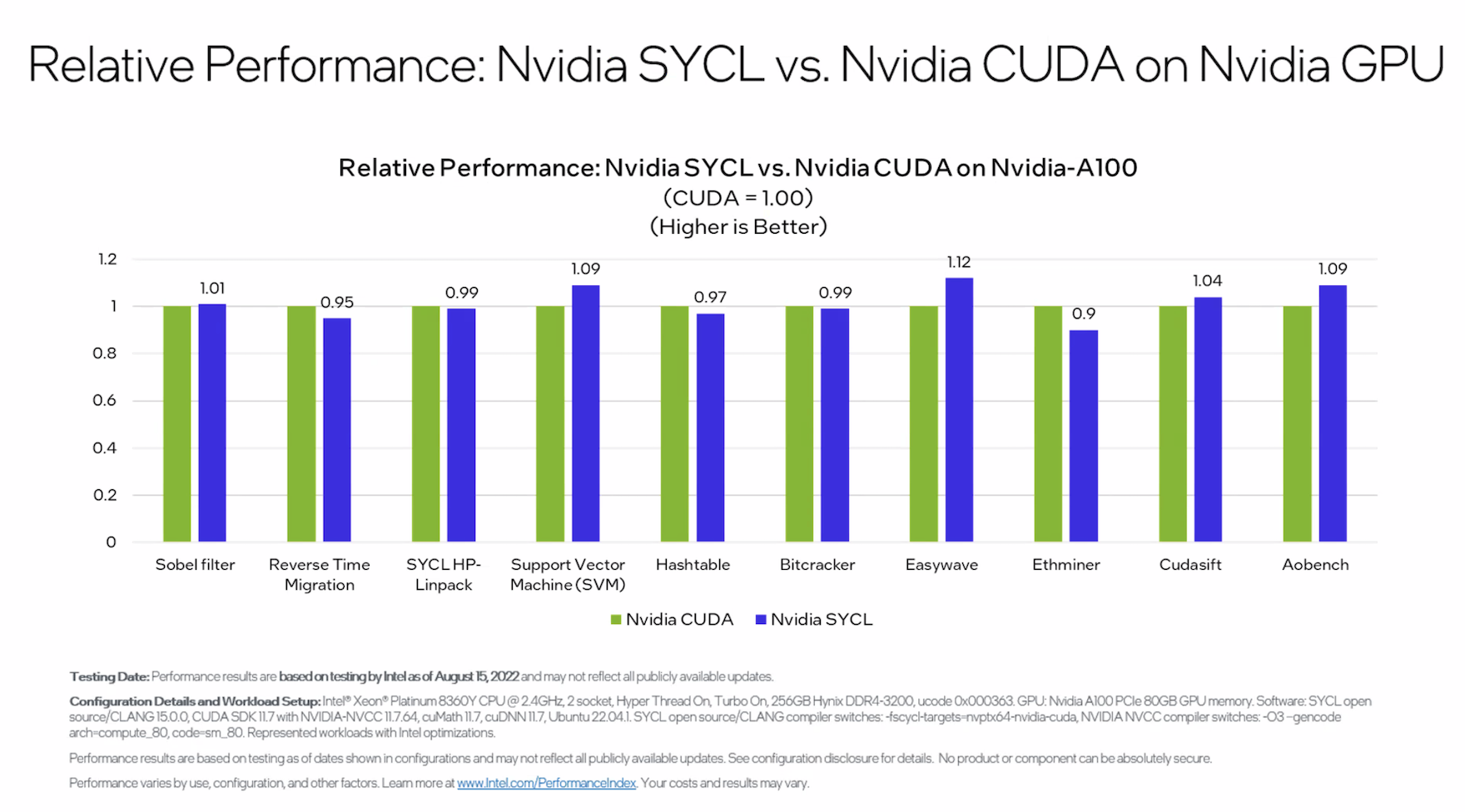
Pennycook presented comparative performance data on SYCL versus CUDA on Nvidia GPUs (A100) and HIP on AMD GPUs.
“Don’t pay too much attention to which bar is higher or lower. For each of these applications, the point that I really want to make is that they’re comparable. So SYCL is getting a comparable performance to CUDA across all of these applications and this demonstrates that SYCL is a high-performance language for NVIDIA GPUs. The reason that there is some difference here is because we’re not just comparing languages, but it’s actually also a comparison of compilers. CUDA is being compiled with NVCC (Nvidia CUDA Compiler) and SYCL is being compiled with the open source Clang pts/x end. In some cases, the compilers make different choices and perform different optimizations,” said Pennycook.
Pennycook presented similar graph comparing SYCL versus HIP on an MI100 (AMD GPU).
“Again, some of the [performance bars] are higher, some of them are lower, but things are comparable. I think that’s a good place for us to be. It used to be until fairly recently that if you wanted to use DPC++ to compile for NVIDIA GPUs or AMD GPUs, you actually had to build everything from source yourself. That’s no longer true. So as of the 2023 release of the Intel DPC++ compiler, you can now actually install these plugins alongside the Intel toolkit and have a single compiler that supports Intel CPUs and GPUs, NVIDIA GPUs and AMD GPUs. These plugins are freely available,” he said.

Pennycook also discussed some of the new features being incorporated into SYCL and a few of those slides are shown below.





























































