 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel has finally provided specific details on wholesale changes it has made to its supercomputing chip roadmap after an abrupt reversal of an ambitious plan to unite the CPU and GPU in a chip.
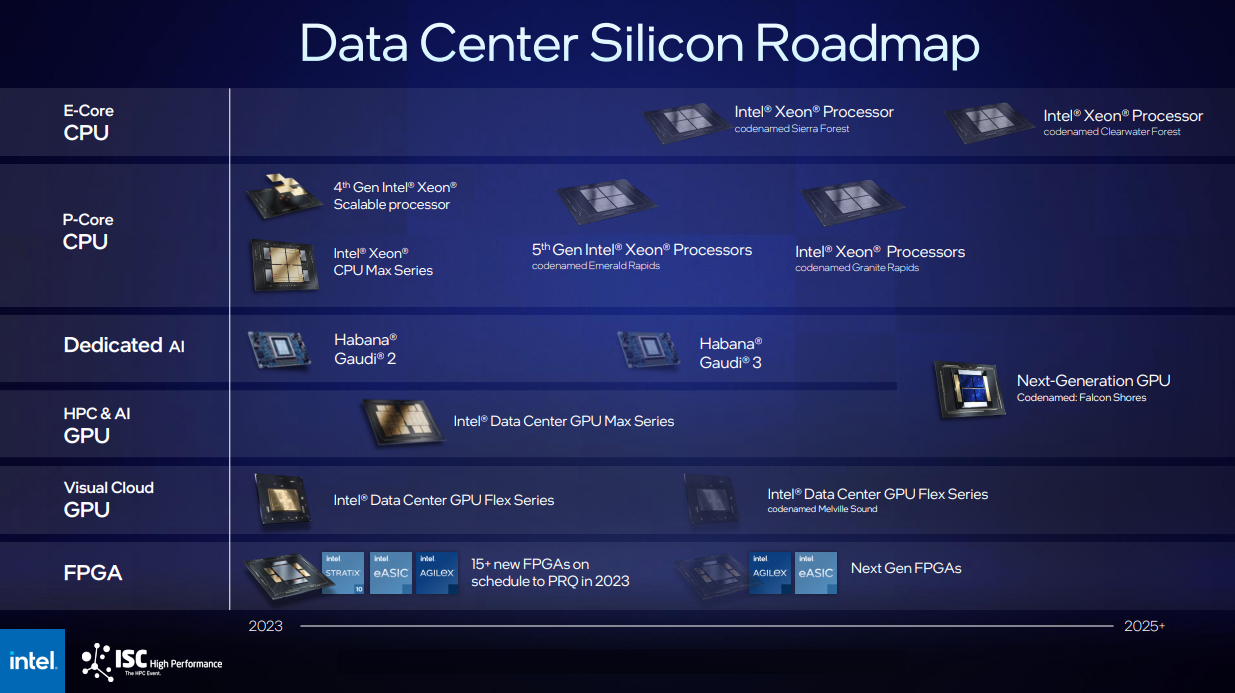
The chipmaker shared more details of an upcoming chip called Falcon Shores, which was originally pegged to be an XPU (a unified CPU and GPU). Falcon Shores is now a GPU-only product, and has been reconfigured for scientific and AI computing.

“My prior push, and emphasis around integrating CPU and GPU into an XPU was premature. And the reason is, we feel like we are in a much more dynamic market than we thought even just a year ago,” said Jeff McVeigh, corporate vice president and general manager of the Super Compute Group at Intel, during a press briefing.
The new Falcon Shores chip is a next-generation discrete GPU targeted at both high-performance computing and AI. It includes the AI processors from the Gaudi family (which will be in version 3 by the time Falcon Shores is released), and also includes standard Ethernet switching, HBM3 memory, and IO at scale.
“This provides the flexibility across vendors to marry Falcon Shores GPU with other CPUs as well as the CPU to GPU ratio, while still providing a very common GPU-based programming interface and sharing across the CXL from CPU and GPU to improve the productivity and performance for those codes,” McVeigh said.
The Falcon Shores GPU, which is the successor to the Max Series GPU codenamed Ponte Vecchio, is now due in 2025. Intel in March scrapped a supercomputer GPU codenamed Rialto Bridge, which had been the anointed follow-on to Ponte Vecchio.
The computing environment was not ripe to pursue an XPU strategy, McVeigh said, adding that innovations around generative AI and large language models – most of which originates from the commercial space – triggered a change in Intel’s thinking of how to build the next-generation supercomputing chips.
Generative AI and LLMs will be broadly adopted in scientific computing, and decoupling the CPU and GPU will provide more options to customers with diverse workloads.
“When you’re in that dynamic market where the workloads are changing rapidly, you really do not want to force yourself down a path of a fixed CPU to GPU ratio. You do not want to fix the vendors or even the architectures used…x86, Arm.” McVeigh said.
Integration of CPUs and GPUs cuts costs and saves power, but it locks up customers to suppliers and configurations. But that will change with the new Falcon Shores, McVeigh said, adding “we just feel like there’s a reckoning with where the market is today and it’s not time to integrate.”
While the merger of a CPU and GPU for supercomputing is not on the cards for the near future, Intel hasn’t given up on the idea.
“We will at the right time,” McVeigh said, adding “when the window of weather is right, we’ll do that. We just don’t feel like it’s right in this next generation.”
A discrete GPU will also give vendors more flexibility on how to build systems with the GPU with different CPUs beyond x86. Intel has struck a deal that could lead to the production of Arm-based chips in its factories.
Server designs are also expected to change with the CXL (Compute Express Link) interconnect, which encourages the decoupling of components so large pools of storage and memory can be easily accessible to GPUs, AI chips, and other accelerators.
“The question is that’s sort of more typically on the shoulders of our OEM partners of how they want to integrate our GPUs with either other vendors’ CPUs, but we leave the door open for that to happen, and utilizing standard interfaces like PCI Express, and CXL and so forth, allows us to do that very effectively,” McVeigh said.
But Intel faces challenges from AMD’s Instinct MI300, which is expected to ship later this year, and will power El Capitan, a two-exaflops (peak) supercomputer that will be at Lawrence Livermore National Laboratory. Nvidia currently dominates the commercial generative AI marketplace, with the company’s H100 GPUs in operation at datacenters run by Google, Facebook, and Microsoft.
Intel will utilize a GPU programming model with Falcon Shores similar to the one adopted by Nvidia with its CUDA programming framework. Intel’s OneAPI toolkit has a family of compilers, libraries, and programming tools that can execute on the Falcon Shores GPU, Gaudi AI processor, and other accelerators that Intel will put in the supercomputing chip.
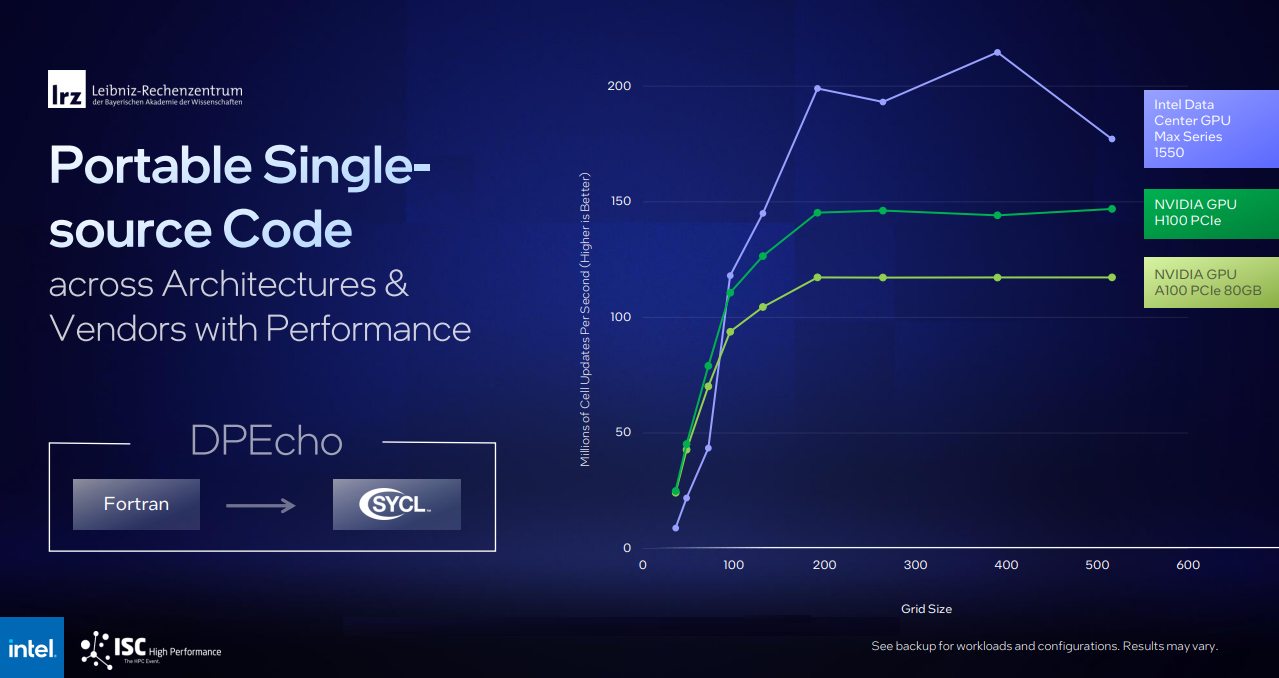
A tool called SYCL in OneAPI can compile supercomputing and AI applications to work on a range of hardware from Intel, Nvidia, and AMD. It can also recompile applications written for Nvidia GPUs by stripping CUDA-specific code. For example, LRZ ported DPEcho astrophysics code from Fortran and was able to run that effectively across both Intel and Nvidia GPUs (benchmarking slide below).
Intel shared other disclosures beyond the GPU course correction.
The chipmaker delivered over 10,624 compute nodes of Xeon Max Series chips with HBM for its Aurora supercomputer, which includes 21,248 CPU nodes, 63,744 GPUs, 10.9PB of DDR memory, and 230PB of storage.
“We have much more work to do for full optimization, delivering on the code and acceptance. But this is a critical, critical milestone that we are … very happy to have accomplished,” McVeigh said.

The milestone is important for Intel because Aurora’s deployment has already been delayed. The supercomputer, which is expected to pass the two exaflops (peak) threshold, will not make this year’s May Top500 list of the world’s fastest supercomputers.
“We’re really focused around bringing out that whole system… stabilizing that and running … getting real workloads, not just the benchmarks running and operational. We would expect that by November for us to have a strong offering in the Top500 system,” McVeigh said.
Recently in a Dell-hosted webinar, Rick Stevens (Argonne Lab) shared that Frontier will contribute approximately 78 million quad-GPU hours per year to critical scientific workloads.
Major HPC players that include Intel, HPE, and Argonne National Labs are joining hands to develop a large-language model for scientific computing called AuroraGPT, which is built on a foundational model of 1 trillion parameters, making it significantly larger than ChatGPT, which is built on the GPT-3 foundational model.
The generative AI technology will be based on available scientific data and texts and code bases, and function like commercial large language models. It’s not clear if the technology will be multimoda, and generate, image and videos. If it is multimodal, one example could be researchers asking questions and the AI providing responses, or using the AI to generate scientific images.
The LLM will be used for the “advancing of science and utilizing Aurora for the training and the inference of that will be a critical part of how the system will be deployed,” McVeigh said.
AuroraGPT could be used for research in materials, cancer and climate science. The foundational models include Megatron and DeepSpeed transformers.
Intel also announced it is bringing out a Universal Baseboard (UBB) system with eight Ponte Vecchio Max Series GPUs (shown in the header graphic) with Supermicro and Inspur based designs initially. The servers are targeted at AI deployments, which McVeigh said favor the 8-GPU configuration. The product was launched earlier this year with expected broader availability in Q3.


























































{kind=link}