 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
It’s not quite homeostasis, but it’s close. There was little movement in the latest Top500, released today from the International Supercomputing Conference (ISC) in Hamburg, Germany. The 61st list saw few changes: no new systems in the top 10 and only three new systems within the top 50 cohort (including one from Microsoft Azure and one from Nvidia at numbers 11 and 14, respectively). We’ll look more closely at those, detail two interesting system speedups (Frontier and LUMI) and discuss other list trends, including the Green500 rankings.
At the top of the list – for the third time – is Frontier, the first “official” exascale system, hosted by the DOE’s Oak Ridge National Laboratory. The HPE-AMD system is 8.35% percent flopsier, going from 1.102 Linpack exaflops on the November 2022 list to 1.194 Linpack exaflops on the new list. That is a gain of 92 petaflops. Interestingly, the Rpeak for the machine’s Top500 configuration actually dropped marginally, from 1.686 exaflops to 1.680 exaflops, a 0.6% decrease. This makes the Linpack improvement all the more impressive.
ORNL’s optimizations to Frontier resulted in a not-insignificant boost to Linpack efficiency: now 71.1%, up from 65.3% previously. The new, tuned-up configuration only uses slightly more power, too (22.7 MW versus 21.1 MW on the previous list), and it improved its Green500 metric (52.59 gigaflops-per-watt versus 52.23 gigaflops-per-watt) – more on the Green500 below. Frontier also aced the HPL-MxP benchmark (formally known as HPL-AI) with a score of 9.95 exaflops, topping its previous result of 7.9 exaflops.
Not on the list (as many had already surmised) is the Aurora supercomputer, a collaboration of Intel, HPE and Argonne National Laboratory. We have speculated that even if the Argonne Lab system had achieved a “decent” Linpack run for the new machine in time to submit results (and, to be clear, we have no inside knowledge as to whether they did or not), Argonne would not want to submit the system to the list if it didn’t surpass Frontier’s run, given that Aurora – which promises “more than 2 exaflops peak” – is intended to be 25-50% larger than Frontier. (Further, Aurora has had a long runway and was at one point slated to be the first U.S. exascale system.) Some clues as to the relative size difference of the two machines came via a recent presentation from Argonne’s Rick Stevens, delivered as part of the Dell HPC Community webinar series. Stevens said Frontier would provide about ~78 million quad-GPU node hours per year while Aurora would provide ~118 million quad-GPU node hours per year. Ceteris paribus, that suggests that Aurora will be about 50% bigger than its Tennessee cousin. We may have more to report on Aurora after the keynote from Intel HPC chief Jeff McVeigh later today.
The other lingering question about Frontier is whether it’s passed its formal acceptance. There were rumors that acceptance was somewhat delayed on account of the complexity of an exascale shake-out and break-in; now we’re hearing that it might have passed acceptance. We’ve reached out to Oak Ridge and hope to have confirmation soon. (And here it is.)
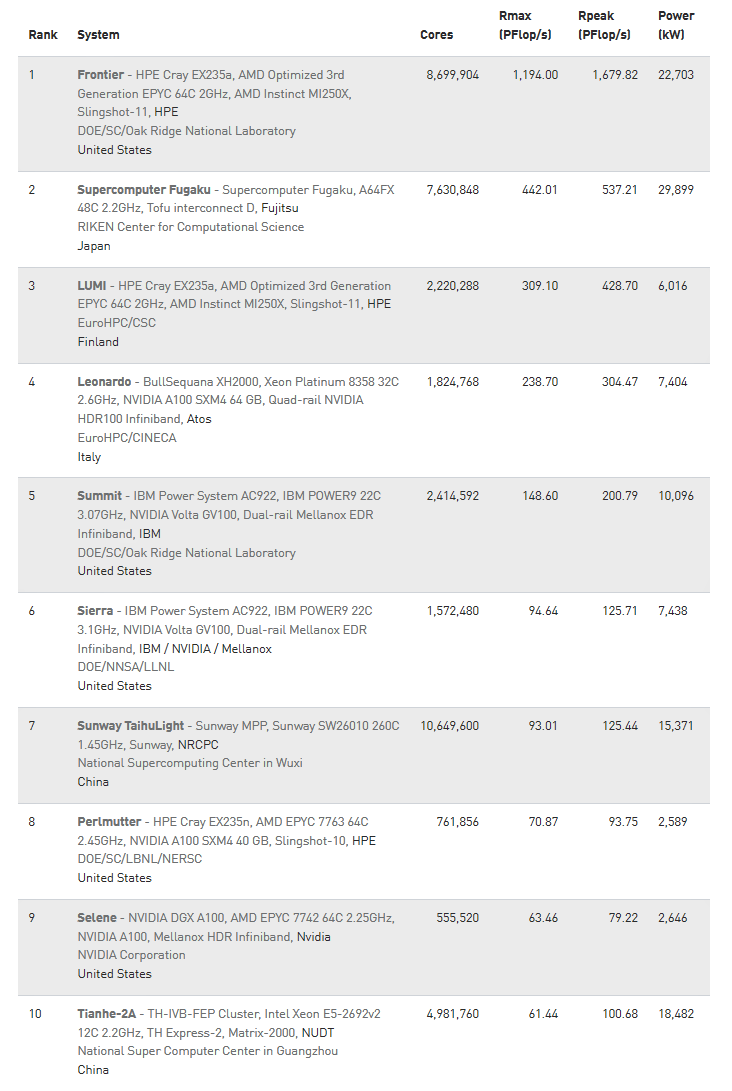
Moving on to the other system amplification: we turn our attention to the EuroHPC-backed Leonardo system, hosted by CINECA in Bologna, Italy. This Atos (Eviden) BullSequana XH2000 system, powered by 32-core Intel CPUs and Nvidia A100 GPUs, now delivers 238.7 Linpack petaflops, up from 174.7 Linpack petaflops six months ago. Despite the growth spurt that added an additional 36.6% computing mass and brought Leonardo to its full configuration, the system maintains its fourth-place ranking. It did not eclipse CSC’s LUMI, which is still in third place with 309.1 Linpack petaflops.
In the number two spot for Linpack rankings, Fugaku, Riken’s Arm-based machine, is still the HPCG (High Performance Conjugate Gradients) champ, an honor it has held since it joined the list three years ago in June 2020. In November, Frontier turned in an impressive (for the notably “challenging” HPCG) 14.05 petaflops result. But Fugaku maintains the lead, achieving 16.00 petaflops on this benchmark. The fraction-of-Rpeak efficiencies here are 0.08% (for Frontier) and 2.98% (for Fugaku). The next highest HPCG score, turned in by LUMI, is 3.4 petaflops, which is 0.08% percent of peak. (Kudos to all who submit to this benchmark despite its low-scoring nature. According to its backers, as a companion benchmark to Linpack, the HPCG is “designed to exercise computational and data access patterns that more closely match a different and broad set of important applications.”)
Other than these two noteworthy enhancements, the top 10 lineup itself hasn’t changed (see inset above, right). Represented countries include the United States, Japan, Finland, Italy and China. Manufacturers include HPE, Fujitsu, HPE, Atos (Eviden), Nvidia and IBM, as well as Chinese government organizations NRCPC and NUDT. Speaking of China, there have been no new large system announcements from the nation since the its two exascale machines were made public via the Gordon Bell Prize proceedings but withheld from the Top500 list.
New systems
There are 43 new systems on the list. Only three appear in the top 50 grouping. Explorer-WUS3 from Microsoft Azure debuts at number 11. And Nvidia’s Eos – or rather the “Pre-Eos 128 Node DGX SuperPOD” – comes in at number 14. The next two highest-ranked new systems are a pair of unnamed Fujitsu machines in 50th and 51st positions. Out of this inaugural cohort, some of the notable systems we’ve been watching are NCAR’s Derecho CPU partition (#59, 10.3 Linpack petaflops), Petrobras’ Gaia (#93, 7.0 Linpack petaflops), NCAR’s Derecho GPU partition (#130, 4.7 petaflops), Atos’ Berzelius2 (#147, 4.2 petaflops), and the University of Tsukuba’s Pegasus (#190, 3.5 petaflops).
Microsoft Azure’s new system – Explorer-WUS3 – runs on the cloud provider’s ND96_amsr_MI200_v4 virtual machines (the MI200 variant of Azure’s NDv4-series virtual machine), powered by AMD second-generation (Rome) Epyc 7V12 48-core CPUs and AMD Instinct MI250X GPUs. The hardware is Frontier-esque in its design, except Azure’s servers leverage the OAM (OCP Accelerator Module) form factor, while Frontier employs a custom board. The cluster was spun up in Azure’s West US3 datacenter, and Microsoft has confirmed it is a permanent system that has or will run real HPC and AI workloads. Explorer-WUS3 delivers 53.96 Linpack petaflops out of a potential theoretical peak of 86.99 petaflops, giving it a Linpack efficiency of 62%. This is the second time that Microsoft has provided the highest new entry on a Top500 list; the last time was in November 2021 with a #10 ranked system.
Nvidia’s new “Pre-Eos 128 Node DGX SuperPOD” is another one we’ve been waiting to hear word on, as Nvidia was notably quiet about Eos during their latest GTC proceedings. The apparent precursor to the full Eos system, Pre-Eos aggregates 40.66 Linpack petaflops out of a potential Rpeak of 58.05 (for a Linpack efficiency of 70.0%), using SuperPod-integrated Nvidia DGX H100 systems, equipped with Intel CPUs and Nvidia H100 GPUs, networked with Nvidia’s ConnectX-7 NDR 400G InfiniBand fabric.

Nvidia announced the Eos system, named for the Greek goddess of the dawn, 14 months ago at its spring GTC 2022, noting at the time the system would be “online in a few months.” Eos is based on the fourth-generation DGX system – the DGX H100 – which hooks together eight GPUs using Nvidia’s proprietary high-speed NVLink interconnects. In its full configuration, Eos will span 18 32-DGX H100 Pods, for a total of 576 DGX H100 systems, 4,608 H100 GPUs, 500 Quantum-2 InfiniBand switches, and 360 NVLink switches. According to Nvidia, the full system will provide 18 exaflops of FP8 performance, 9 exaflops of FP16 performance or 275 petaflops of FP64 performance (all peak numbers). We did the math and came up with 156 petaflops FP64 peak when we plugged in 34 teraflops of traditional FP64 per H100 SXM (reference) and multiplied it by the machine’s planned 4,608x GPUs.
Currently, between 31 and 127 DGX H100 systems can be brought together into a SuperPod (in Nvidia’s parlance) using NVLink switches. (Nvidia addresses the seeming discrepancy between the 127-node number and the 128-node Top500 system in an update note below.) Nvidia’s product specifications doc, dated May 2023, notes that “a pair of NVIDIA Unified Fabric Manager (UFM) appliances displaces one DGX H100 system in the DGX SuperPOD deployment pattern, resulting in a maximum of 127 DGX H100 systems per full DGX SuperPOD.” Fully configured and populated, a 127-node SuperPod provides 3.2 exaflops of peak FP8 computing, 34.5 peak traditional FP64 petaflops, or 68.1 peak FP64 tensor core petaflops.
Eos is the planned successor to Selene, which was named for the Greek goddess of the moon and sister of Eos. Selene debuted in seventh place on the Top500 in June 2020 and is currently ranked ninth. The system, which comprises 280 DGX A100 systems, delivers 63.46 petaflops out of an Rpeak of 79.22 petaflops, which translates to a Linpack efficiency of 80.1%. [Note: Nvidia’s Rpeak is configured differently than its marketing peak.]
Update (May 22): An Nvidia spokesperson followed up in response to our question about the 128-node Pre-Eos versus the standard 127-node SuperPod configuration, stating that the “Pre-Eos Top500 submission is an early preview of our full Eos DGX H100 supercomputer currently being built out. It represents a slice of the final machine, so it has a larger fabric to support the rest of the build out to follow.
“The UFM details are correct for a typical DGX SuperPOD built with DGX H100 systems,” the statement read. “But we don’t have the same port limit in the Eos design. Our Pre-Eos system contains 128 DGX H100 supercomputers, 4 SUs (scalable units), out of the final 576 DGX H100s, 18 SUs.”
Green500 highlights
The Green500 stayed similarly static to the Top500. The Flatiron Institute’s Henri system, built by Lenovo and powered by Nvidia’s H100 GPUs (the system marked the chips’ list debut last November) retained the top spot. Henri’s efficiency grew slightly – 65.40 gigaflops-per-watt, up from 65.09 gigaflops-per-watt – but interestingly, its peak petaflops actually dropped (5.42 peak to 3.58 peak) while its Linpack petaflops rose (2.04 Linpack to 2.89 Linpack). This corresponds to more than a doubling in Linpack efficiency – 37.62% to 80.52%. We expected to see something like this increase in efficiency when Henri first hit the lists.
As mentioned, Frontier also got a tiny bit of a glow-up, going from 52.59 gigaflops-per-watt from 52.23 gigaflops-per-watt.
Outside of those efficiency improvements, the top ten of the Green500 actually did see a couple of new entries. In 8th place is the GPU partition of the amplitUDE system at the University of Duisburg-Essen (UDE – get it?) with 51.34 gigaflops-per-watt. At 1.95 Linpack petaflops, amplitUDE – which is also based on Intel Xeon CPUs and Nvidia H100 GPUs – squeaked onto the Top500 list in 483rd. Just after amplitUDE, in 9th: Goethe-NHR at the University of Frankfurt. Based on AMD Epyc CPUs and AMD Instinct MI210 GPUs, Goethe-NHR delivered 46.52 gigaflops-per-watt and ranked 70th on the Top500 list with 9.09 Linpack petaflops. Previous list-topper system MN-3 has left the top ten, ranking 11th this go-around.
All of the top ten are accelerated, as has been the case for five iterations of the list now. This list sees seven accelerated by AMD and three by Nvidia. Eight of the top ten deliver over 50 gigaflops-per-watt, which extrapolates to an exaflop in 20 megawatts or less – a threshold previously thought unrealistic.
Additional Top500 trends
The entry point to the list is now 1.87 petaflops (up from 1.73 petaflops six months ago), and the current 500th-place system on the list held a 456th place ranking on the previous (November 2022) list, which was detailed at SC in Dallas. The aggregate Linpack performance provided by all 500 systems on the 61st edition of the Top500 list is 5.24 exaflops up from 4.86 exaflops six months ago and 4.40 exaflops 12 months ago.
The entry point for the Top100 segment increased to 6.31 petaflops up from 5.78 petaflops six months ago and 5.39 petaflops a year ago. The aggregate Linpack performance of the top 100 systems is 4.07 exaflops out of 5.66 theoretical exaflops, which comes out to a Linpack efficiency of 71.88%. The Linpack efficiency of the top 10 systems is slightly higher at 73.88%, while the overall Linpack efficiency of the entire list is 66.94%.

























































{kind=link}