 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
ISC’s closing keynote this year was given jointly by a pair of distinguished HPC leaders, Thomas Sterling of Indiana University and Estela Suarez of Jülich Supercomputing Centre (JSC). Ostensibly, Sterling tackled the frothy dynamics of the HPC landscape during the past year while Suarez ably looked ahead, but, of course, there was a bit of overlap as the two topics necessarily intertwine. Both speakers are familiar figures in the HPC community (brief bios at end of this article).
The pairing of two speakers is a bit of a departure from the past. Sterling, perhaps best known as one of the fathers of the Beowulf cluster architecture and for his contribution to parallel computing broadly, has delivered the annual closing keynote alone for the past 19 years. This was his 20th. Suarez is a prominent leader in the DEEP series of EU-funded projects and has driven the development of the cluster-booster and the modular supercomputing architectures. She stepped nicely into the role of co-presenter. Next year’s ISC24 chair, Michaela Taufer was the session moderator.
So much for the prologue. What did they say?
- Déjà vu might have been Sterling’s broad take on last year. Frontier (ORNL) formally marked the start of the exascale epoch, he said, but where are the others. With his usual slightly irreverent manner, he touched on the Top500’s tail of productive smaller systems, praised the EuroHPC JU and AGILE programs, touched on AI’s push into HPC and the rise of LLMs, took issue with ISC opening keynoter Dan Reed’s “follow the money” mantra; and paid tribute to computing pioneer Gordon Moore who passed. There was, of course, more and we’ll get to it.
- Citing recent global challenges (Covid, Ukraine, Climate Change) and their impact on HPC, Suarez ably examined key technology trends – processor diversity; the modular approach to build JUPITER; new ideas in packaging and interconnect; Europe’s planned first exascale system at JSC; EuroHPC’s ambitious quantum initiatives; the Destination Earth project (digital twin); and more. She also explored goals for the post-exaflops era, which, no surprise, includes more attention to efficient energy use.
The closing keynote is a good event, always with too much material to squeeze into a short summary article. Fortunately, ISC has archived the video (for registered attendees). Presented below are a few slides and comments (lightly edited) from each of the speakers.
Sterling Delivers Laurels (Good Work EuroHPC) and Darts (Take That Dan!)

Sterling presented first and opened by emphasizing the rather amazing progress HPC has made in a relatively short time. “Watching the [student] cluster competition is always delightful for me,” said Sterling, “and I learned that the winners [this year] had over 100 teraflops on the Linpack. That’s really cool. The first Beowulf that I and my colleagues, including Don Becker, implemented in 1994 achieved not quite 100 megaflops. For those of you doing the math in your head, I’ll save you the time – that’s a factor of a million. Not bad for 25 years.”
Indeed. Frontier, the top performer on the latest Top500 List, did so with a 1.194 Linpack exaflops. But, as Sterling noted, things have been somewhat static as we wait for more exascale systems to come online.
“This, of course, is the end of the first year of what might be called the exascale epoch, but not a lot happened in that year, advancing the exascale agenda. We still have one machine, Frontier at Oak Ridge National Labs. However, looking forward, we can be a little bit more optimistic. Let me just give a shout out for [planned] Aurora and Mare Nostrum 5 both of which have had challenges getting on the floor, but they are [progressing] and they will be up by the next year [and] I’ll be able to report to you,” said Sterling.

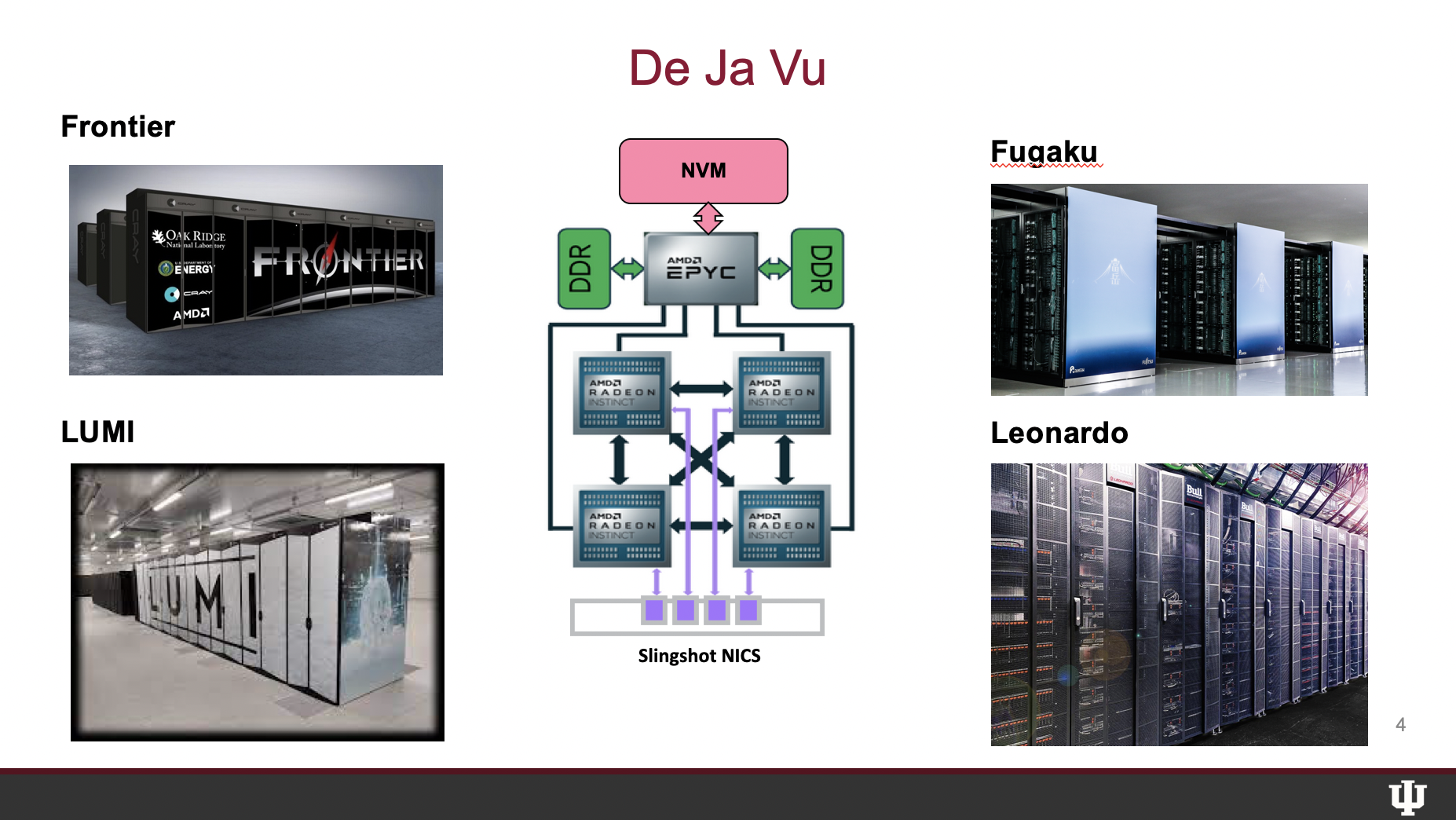
Sterling said “there’s a sense of the graying of HPC community” in that top systems have not changed much but he also emphasized there is increasing variety of architecture. “Frontier, Fugaku – “wonderful machine” – Lumi, and Leonardo “are not just copies of each other, each one has its own special case.”
The surprise this year, said Sterling, was the sudden avalanche of AI via LLMs into the world. Clearly AI technologies, including machine learning and deep learning, have been steadily infusing HPC for a few years, but the buzz caused this year by ChatGPT and its ilk has many wondering if LLMs will be transformative.
Sterling called it the killer app. “I don’t think I had heard the phrase large language models a year ago or LLM. In fact, when I first heard LLM, I really thought they were saying LGM, which stands for little green men,” he jested. “But in fact, looking at this, it’s a significant and almost constructively disruptive step in using neural nets, which are trained on very large amounts of data. But they’re unlabeled. And let’s face it, the you know, the worst part of machine learning is that you have to already tell it the answer, right, the approximate answer.”
“I know people don’t like to hear [that] supervised machine learning is interpolation. Now, two major components to this are self-supervised learning, which is sort of someplace in between, supervised and unsupervised. The issue is the ability to absorb [and] assimilate very large amounts of data, which are not purely accurate or not precise. This opened up a whole wealth of alternative environments,” he said.

Sterling had high praise for the EuroHPC JU. “It is really great to see an initiative that is, in my view, well planned, especially when you’re dealing with you, know two, dozen or so nations all of which love each other and recognize that there are multiple challenges which are distinct in many respects, but nonetheless, are mutually in their own [interest]. EuroHPC has been doing that,” he said. “The thing is that EuroHPC JU is now well-established, well-funded, well-organized and well-managed initiative. And my congratulations.”
He also singled out the lesser known AGILE (Advanced Graphic Intelligence Logical Computing Environment) initiative in the U.S. being run by IARPA which undertakes high-risk, high-reward programs. (See HPCwire coverage here.)
“Agile, it’s a terrible acronym and I don’t even remember what it means. But what’s really cool about this, and it’s the best program I’ve ever been able to participate in. There are six different performing teams – Qualcomm, Intel and AMD from industry and University of Chicago, Georgia Tech, and Indiana University on the academic side. Each of them are partnered with others to devise very complicated designs. I’m not going to read the blue print (slide below) but if you quickly scan it, you’ll realize that the foundation principles that are assumed to be component ideas and implementations in these in these designs. They’re already sufficiently radical that they do not overlap significantly with conventional computing,” he said.


ISC itself provided one of Sterling’s more interesting set of comments. In the ISC23 opening keynote, Dan Reed, longtime HPC figure and the chair of the U.S. National Science Board, advised that HPC was no longer the primary driver of advancing computer technology. He stated the giant cloud-providers and financial incentive, i.e. profits, are guiding development. Follow the money he advised. (see HPCwire coverage, ISC Keynote: To Reinvent HPC After Moore’s Law, Follow the Money)
Not so fast, argued Sterling.
“Dan Reed’s keynote was great. I hung on every word. In an overly simplistic way, [Reed] said, “If you want to change the future, follow the money.” Now, he’ll disagree that I’ve adequately captured it, I’ll accept that. But to do that suggests… limits it to the exploitation of knowledge, which includes some from the future, the expectations that we ourselves are driven by; and it’s limited by the market of the present, not of the future. It assumes that the future will be the present with some incremental changes.
“But evolution doesn’t work that way. And I hate to break it to you, but we’re all a product of evolution. Evolution is actually not about the winners. You know what happens to the winners in evolution? They go extinct when something – a moment – occurs. It’s the losers, the outliers, the drifters of each species, that are sufficiently generalized, although not terribly optimized, that are able to then fit into new ecological niches. [Just ask] the mammals,” said Sterling. “In my view, a true evolution of our field occurs from inspired motivation, challenge and opportunity – or recognized opportunity – vision, and imagination, and creativity and innovation, and yet, risk. Sometimes it takes revolution to create a new, real world. Now, I know I’m out of time.”


Sterling also delivered a nice tribute to Gordon Moore who needs no introduction here and for whom Moore’s law named.

Suarez Reminds HPC of its Responsibility and Describes Paths for Technical Advance

After acknowledging HPC’s steady rise – “For the last 14 to 15 years, the whole HPC community had the common goal of getting to the exaflops mark. This was achieved last year with Frontier, which is a huge achievement.” – Suarez reminded the audience to take a step back and “realize the world in which we are living, in which HPC is embedded, has been kind of hassled with a number of events,” including the Covid crisis, the geopolitical situation in the Ukraine, and climate change.
“All those things have an impact on HPC,” she said. “We are all well aware what happened in 2020, with the microprocessor shortage, higher prices in technology. With the Ukrainian war, we experienced a huge rise in energy costs, and in some centers, it actually led to reduced operations. With climate change, there is a new focus in society that makes us basically justify the use of energy and the use of resources of natural resources. In the face of such challenges, HPC has always replied, and I hope it continues to do so, through innovation. What I’m going to go through in the next few slides is just some highlights some cherry picking on research and trends that I think are interesting.”


First up was processor diversity and how to effectively incorporate it into system architecture.
“We see a growing diversity in processing units, from the many core and multi-core CPUs we are all familiar with to a huge number of accelerators, graphic cards, vector processing accelerators, FPGAs, and even custom ASIC implementations that aim at accelerating a specific instruction. Why does this happen? Because we are trying to achieve performance and we are trying to achieve efficiency through a specialization.
“The question is, with all these diversity, how do we put them in our HPC systems? How do we put them at the service of our users? There are different approaches. I will speak first from what I know most that is the model our supercomputing architecture we use, or we developed in Jülich, and that is the basis for the first exascale system that will be deployed in Europe. We call it JUPITER,” she said.
“The idea is we will have a CPU cluster where the focus is on achieving high memory bandwidth attach to our, Yes, GPU based boosters – so [that’s the] accelerated system and it’s the part that we [need] to scale up to the exaflops. This is of course, then complemented with a high current Hierarchical Storage. The target is that an application that today runs on our last largest system will run 20 times faster will be half or 20 times more performance when running on the full up their machine.”

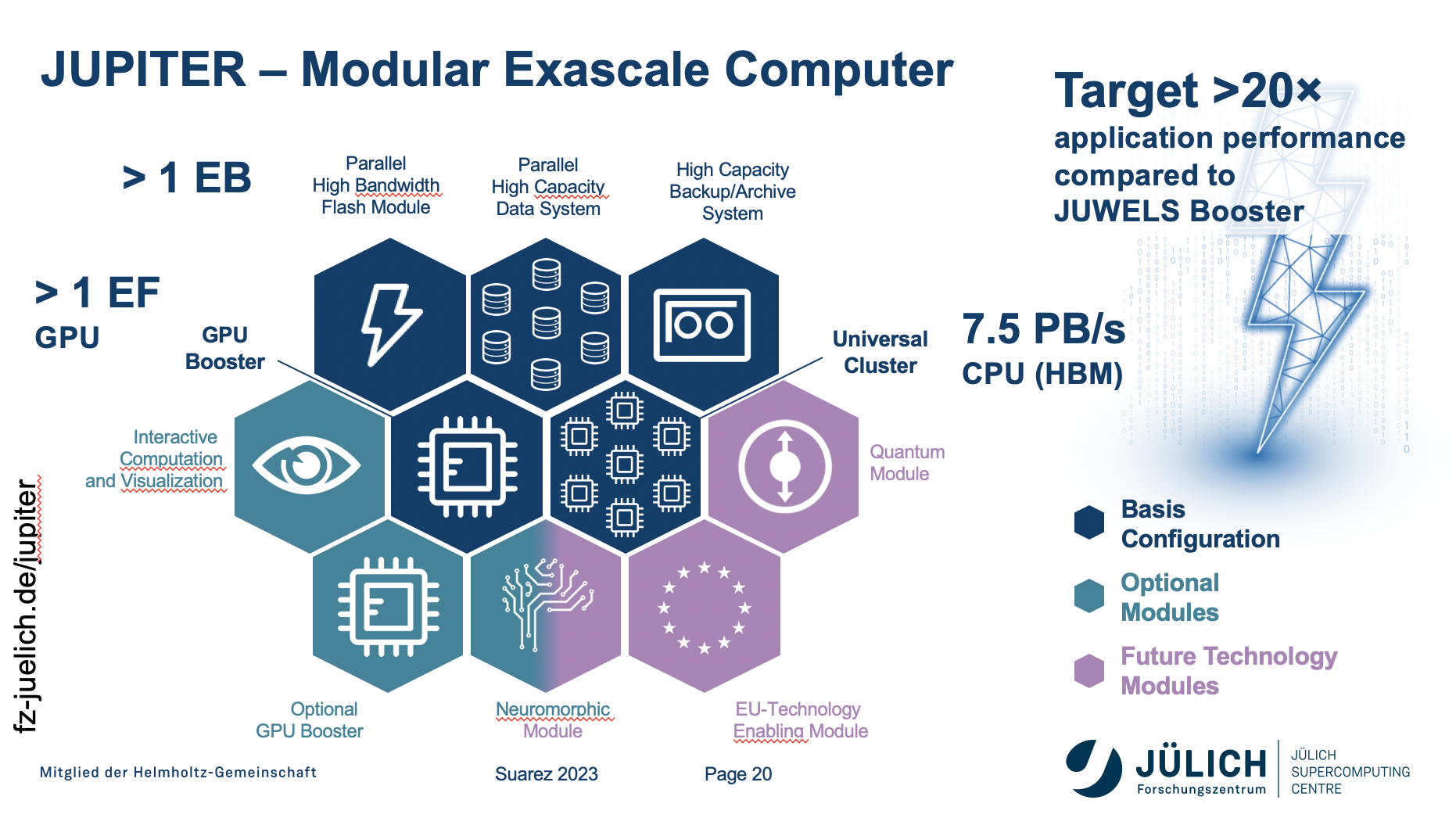
While Suarez knows JUPITER best, she recognized there are many approaches to scaling up these big HPC systems.
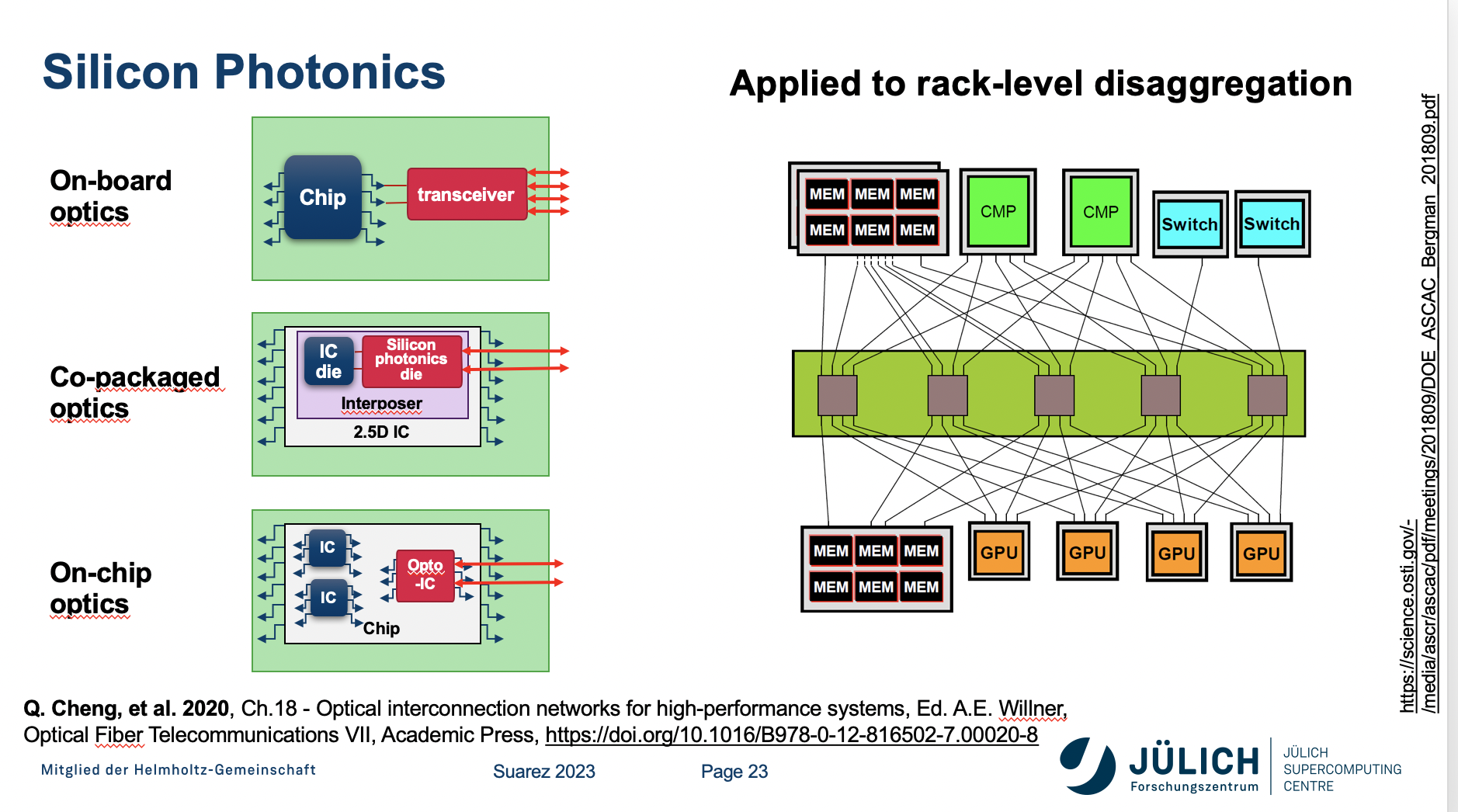
“I was speaking generally about this modular idea [at JSC]. Other places are doing this differently. Some are looking at things like rack-level disaggregation. Currently, you have a server configured in some ways, and CPUs and GPUs or memory, and you build your rack by multiplying these several times,” said Suarez. “Disaggregating this would allow that you have the components, let’s say individually, and you can then pull on compose them depending on the needs of the users. Depending on the specific applications, you might have many CPUs for one, many GPUs for others. This is possible with some new network technologies such with CXL that allows for memory coherency across this larger machine. And in the near or farther future, this might be even more interesting if you include their silicon photonics.”
Indeed, there’s an abundance of work on composable infrastructure and optical interconnect (on-chip and off-chip) around the world.

There are, of course, plenty of software challenges as well.
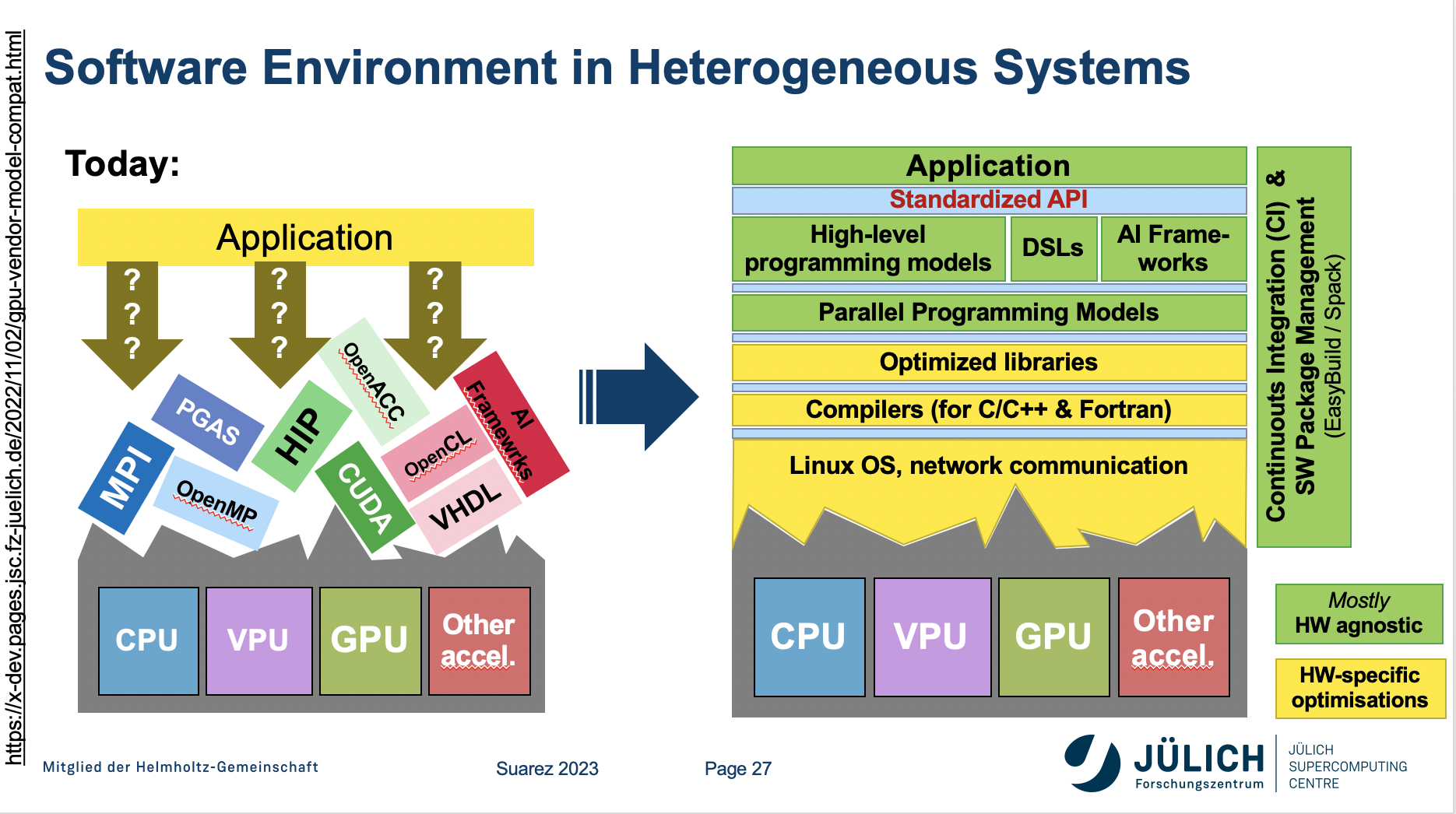
“The consequence of having all this heterogeneous hardware … is a more complex software stack. If you look at it from the perspective of the programming model, if you just look at it from the perspective of the user, it means that you have to decide which programming model you use depending on the device that you want to use and even depending on the vendor that provides this device,” said Suarez.
“There is a lot of development and research going into the direction of trying to decouple these concerns and trying to ensure that only the lower part of this stack that is here in yellow (slide below) needs to be optimized to the specific hardware, while the upper layers can remain as hardware agnostic as possible. There, the layers should have standardized APIs between all of them. Of course, the picture is simplified, you will have things that go from top to bottom, but always trying to decouple the front-end from the back-end to keep things evolving separately,” she said.
Suarez turned briefly to Europe’s rapidly growing quantum computing efforts.
“Thomas (Sterling) mentioned this. There is a huge investment in Europe in the integration of quantum computing and HPC. What you see there (slide below) are some installations that are planned in the near future in different sites in Europe – in seven sites. They will all be federated with each other,” said Suarez. “The different sites are working on different quantum technologies, [because] there are many different approaches for quantum computing. By federating them all together, a user can try different kinds of machines and find out which are more suitable. In parallel to that, there is a research agenda that you see there on the ballot. […] It has very aggressive targets for 2030 – for this timeframe.”
Keeping track of Europe’s many quantum efforts can be challenging. Though nascent, they have been quickly gathering speed. The early focus on HPC-QC integration, along with close collaboration with industry, are distinguishing features. (For more on Europe’s quantum development efforts, see HPCwire coverage, ISC BOF: Euro Quantum Community Tackles HPC-QC Integration, Broad User Access.)

There was a good deal more to her presentation. One interesting part was perhaps a slight disagreement with Sterling over Reed’s earlier keynote. Suarez didn’t tackle the idea of industry and profits as drivers of technology, but she agreed with Reed’s observation that the HPC industry was similar to the airplane industry in the following way.
Generally speaking, air speeds have not risen (pun intended) in the commercial airline industry, with cost cited as the major causer. The supersonic Concorde was famously fast and economically unfeasible. As a result, aircraft and airline innovation happened in different areas while the speed has stayed the same. Likewise, said Reed, the way to get faster machines is to build bigger machines and there’s no appetite for that because the costs (dollars and energy) are so high.
Said Suarez, “I want to go back to the one thing that Dan Reed mentioned on Monday that I really liked a lot – the comparison with the aeronautics industry. They are not trying to get any faster. They are trying to optimize their technologies. I think that we are at the point that we need to exactly go in this direction, so how to maximize the output of our HPC systems, how to improve or optimize for performance and at the same time for energy efficiency. That’s a very complex problem, because all these things are, of course, interrelated.”

SPEAKER BIOS
Thomas Sterling
Dr. Thomas Sterling holds the position of Professor of Electrical Engineering at the Indiana University (IU) School of Informatics and Computing Department of Intelligent Systems Engineering (ISE) as well as serves as Director of the IU Artificial Intelligence Computing Systems Laboratory (AICSL). Since receiving his Ph.D. from MIT in 1984 as a Hertz Fellow, Dr. Sterling has engaged in applied research in parallel computing system structures, semantics, and operation in industry, government labs, and academia. Dr. Sterling is best known as the “father of Beowulf” for his pioneering research in commodity/Linux cluster computing for which he shared the Gordon Bell Prize in 1997. He led the HTMT Project sponsored by multiple agencies to explore advanced technologies and their implication for high-end computer system architectures. Other research projects in which he contributed included the DARPA DIVA PIM architecture project with USC-ISI, the DARPA HPCS program sponsored Cray-led Cascade Petaflops architecture, and the Gilgamesh high-density computing project at NASA JPL. Sterling is currently involved in research associated with the innovative ParalleX execution model for extreme scale computing to establish the foundation principles guiding the development of future generation Exascale computing systems. ParalleX is currently the conceptual centerpiece of the proof-of-concept HPX-5 runtime system software. He currently leads a research program in non von Neumann computer architecture for graph processing and Zetascale computing. Thomas Sterling is President and Chief Scientist of Simultac LLC of Indiana developing a new class of graph processing accelerator. Dr. Sterling is the co-author of seven books and holds six patents. He was the recipient of the 2013 Vanguard Award and is a Fellow of the AAAS. Most recently, he co-authored the introductory textbook, “High Performance Computing”, published by Morgan-Kaufmann in December, 2017 with a 2nd edition to be released in 2022.
Estela Suarez
Estela Suarez leads the Novel System Architectures Department at the Jülich Supercomputing Centre, which she joined in 2010. Since 2022 she is also Professor for High Performance Computing at the University of Bonn. Her research focuses on HPC system architectures and codesign. As leader of the DEEP project series she has driven the development of the Modular Supercomputing Architecture, including hardware, software and application implementation and validation. Additionally, she leads the codesign and validation efforts within the European Processor Initiative. She holds a PhD in Physics from the University of Geneva (Switzerland) and a Master degree in Astrophysics from the University Complutense of Madrid (Spain).

























































