 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetMay 15, 2023 — “The storage world has changed,” observed Rob Ross (Figure 1), principal investigator of the DataLib project, senior computer scientist, and R&D leader at Argonne National Laboratory. “In recognition of this, the Exascale Computing Project’s (ECP’s) DataLib effort was created to develop software to help scientists use storage and very large volumes of data as part of their activities.”

The impact is significant explained Ross, “The DataLib group members are responsible for some of the most successful storage and I/O software in the [US Department of Energy (DOE)] complex because they decided to think beyond traditional checkpoint and restart and consider storage as a service that extends beyond a traditional file system. Storage is a pillar of [high-performance computing (HPC)]. This new way of thinking is reflected in the many ECP dependencies on DataLib.” DataLib encompasses three groups of users: applications, facilities, and software teams.
The team’s excellent track record includes the Darshan project, which is a lightweight characterization tool for observing application I/O patterns, and the Mochi tool suite, which is a toolkit for building high-performance distributed data services for HPC platforms. Darshan won an R&D 100 award in 2018, and Mochi won an R&D 100 award in 2021. The team also works on Parallel NetCDF (PnetCDF), which is heavily utilized in climate and weather applications.
“The forward-thinking approach taken by the group,” Ross reflected, “had a significant impact on the success of these storage and I/O software projects and the benefits they deliver to the HPC and national security communities.” The impacts include the following:[1]
- Supporting and extending packages that scientists can use to access and share data across all the different platforms on which they work.
- Employing tools that reveal how scientists are using their data, thereby providing information to troubleshoot problems at facilities and to better configure future systems.
- Enabling researchers within the DOE’s Advanced Scientific Computing Research (ASCR) programs through DataLib tools to build entirely new specialized data services to replace tools that are either too difficult to use or too slow.
The Evolution of Storage as a Data Service
“When we were proposing the DataLib work back in 2015,” Ross recalled, “we noticed our work was focused on parallel file systems and I/O middleware, which meant we were mainly acting on user requests about storage and I/O. Our team recognized we could broaden our approach by addressing storage issues as a data service, which an organization can then use to manage a variety of different types of data as desired and often with a particular purpose in mind.”
He continued, “Storage is intimately tied to data utilization and hardware, both of which are becoming increasingly complicated. To meet this need, we realized we had to raise awareness of how applications interact with storage systems and how users can efficiently use existing tools. In the face of rising complexity, we have to make it easier for users to develop new tools that can do a better job meeting their application needs and can better map to hardware. A data service can adapt to meet current and future needs.”
The Community Model for Infrastructure
Consulting and research go hand in hand. Ross noted that the team has been working in this space and tracking applications for a long time, since 2000. He observed, “We are constantly working with research teams, understanding their problems (both to help them and us), and using those interactions to drive future research and software efforts. One example is Mochi, which was motivated by the recognition of a need for new data services and a tool set to help develop those services.” According to Ross, “Traditionally, it has taken too long to create these services. The HPC community cannot wait a decade for the next Lustre.“
Outreach is extremely important. The DataLib team leverages the community model to make all their accumulated knowledge available to vendors, facilities, and users. “The community model complements our efforts” Ross observed. “For our research teams to be effective, they need to have one foot in the deployment and application and the other in the applied research and development. This provides significant benefits to DOE, the Office of Science, and the open HPC community—both academic and commercial. Very simply, you cannot compute fast if you cannot access data from storage.” Ross also pointed out the significant security benefits that can be realized through the community model, a need that is becoming ever more urgent given the ubiquity of global internet access. This approach is reflected in other key infrastructure efforts, as described in the article, “The PETSc Community is the Infrastructure.”
Additionally, the team surveys their users, holds quarterly meetings for Mochi, runs sessions at the ECP Annual Meeting, and organizes full-day events at the Argonne Training Program on Extreme-Scale Computing and at the International Conference for High Performance Computing, Networking, Storage, and Analysis to share their expertise on the DataLib tools and on the broader subject of I/O in HPC. Furthermore, the team also meets one-on-one with users when needed, such as with E3SM.
Understanding DataLib through Exemplar Use Cases
The DataLib forward-thinking projects can be roughly categorized by use case, including file systems, alternative data models, in-situ data analysis, data monitoring to understand workflow performance (e.g., Darshan), and toolkits to build distributed data services (e.g., Mochi). For example, the team methodically assesses the use of HDF5 (Hierarchical Data Format version 5) in ECP and is building new internal HDF5 back ends that target key use cases.
User-Level File Systems
File systems are generally the first thing that most people talk about when thinking about storage. Extraordinary performance benefits are being realized by eliminating POSIX file system bottlenecks that can serialize storage access and user space.
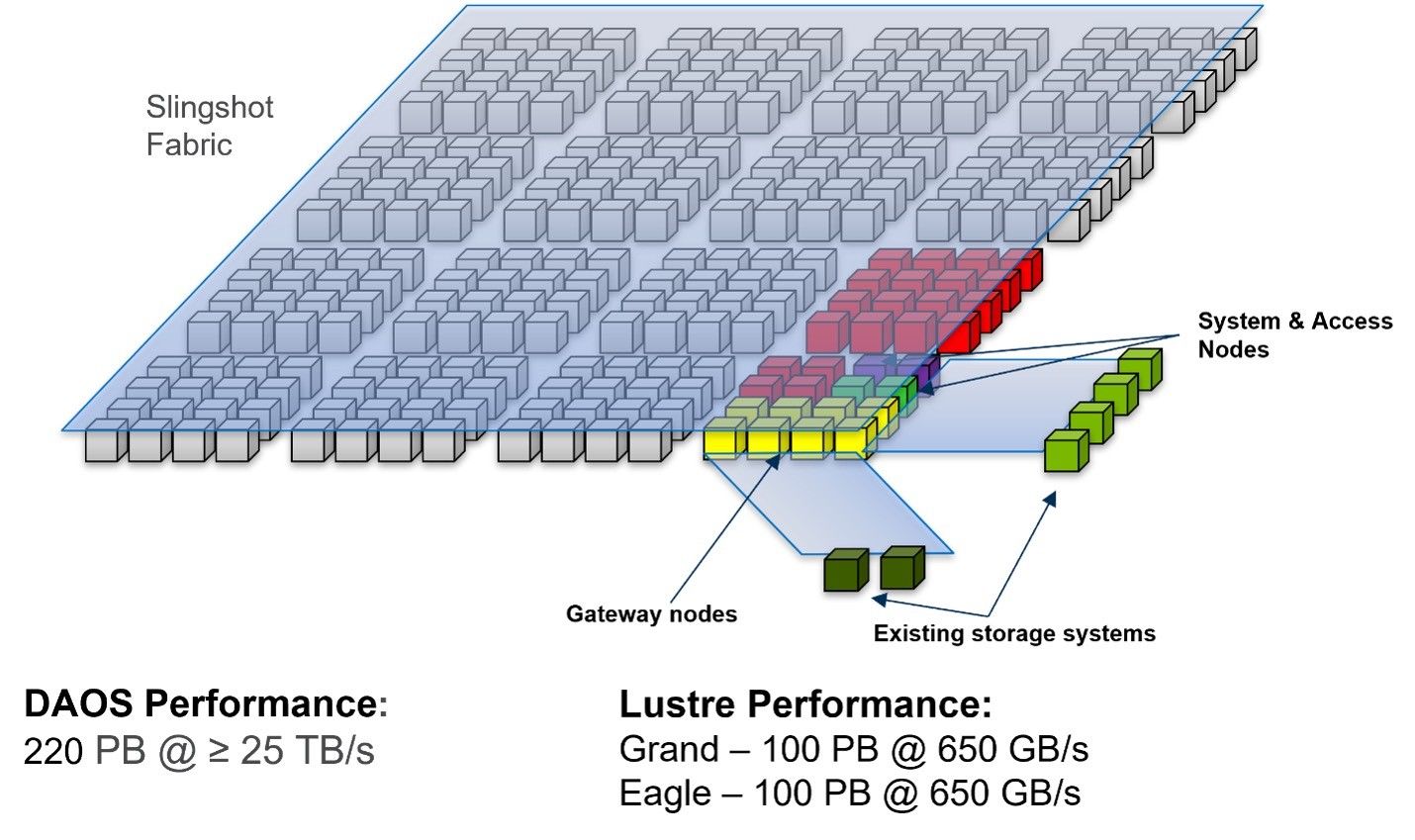
One of the highest profile efforts is the Distributed Asynchronous Object Store (DAOS) software that will be used as the primary storage mechanism on the Aurora exascale supercomputer. While the DataLib team hasn’t played a central role in the development of DAOS, the team is working to integrate and work with DAOS (Figure 2), which is an extensive open-source project with many collaborators.
Owing to the efforts of this open-source project, the DAOS software has already delivered record-setting performance on HPC hardware.
The DataLib team is looking at the DAOS software, which can be accessed in two ways:
- DAOS supports direct access to storage from the application via the (libdfs) user space library. Key HPC tools such as HDF5, MPI-IO, and TensorFlow leverage this capability. Results reported at the 2022 ISC High Performance conference, for example,show that DAOS outperforms Lustre when loading a large AI dataset into TensorFlow.[2]
- DAOS also supports traditional HPC workloads that access data through a user space file system mount point, and this is enabled via an interception library. Running the file system in user space eliminates significant operating system overhead, including the unavoidable context-switch overhead of a kernel system call plus the internal operating system overhead that is required to manage the internal kernel file system and block caches.[3]
Deviating from POSIX, DAOS implements an alternative relaxed consistency model in both data and metadata that permits HPC codes to exploit the available concurrency. This concurrency is implemented in hardware through node-local and embedded storage devices. Internally, DAOS uses a key-value architecture that avoids many POSIX limitations and differentiates DAOS from other storage solutions with its low-latency, built-in data protections, and end-to-end data integrity while delivering increased single-client performance.
Importantly, the key-value architecture makes DAOS fully distributed, with no single-point metadata bottleneck, and gives the node full control per dataset over how the metadata is updated. This highly scalable approach particularly benefits workloads in which small file, small I/O, and/or metadata operations per second (IOP/s) performance is critical. The key-value approach also maps nicely to the cloud, which means application codes can readily move to new platforms—including HPC applications that run in the cloud—and be applied to a wide range of different problems.
The DataLib team also works with other filesystems such as GekkoFS a burst-buffer temporary file system, and UnifyFS as they use DataLib components to build their products. The team is working to make improvements to ROMIO to speed MPI-IO and HDF5 support on the Frontier burst buffer hardware, which uses UnifyFS.
Click here to continue reading this article.
Source: Rob Farber, ECP

























































