 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
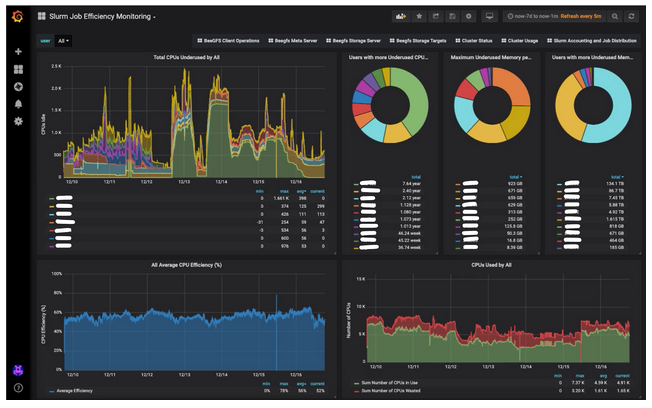
HPC & AI Wall StreetFeb. 9, 2023 — Scientists and engineers at HPCNow! have developed a solution to monitor the status of HPC clusters in real time. The monitoring stack includes open-source solutions such as Grafana, Elasticsearch and Prometheus, for visualization and data storage, and Slurm plugins plus customized scripts to gather all the information needed by the system administrator. The solution is delivered using Docker Compose for single-node monitoring scenarios, or using Docker Swarm if high-availability is requested by the customer.
![]() Additionally, it includes the necessary dashboards to display gathered information such as:
Additionally, it includes the necessary dashboards to display gathered information such as:
- Slurm jobs: accounts for all Slurm jobs over a period of time.
- Job detail: returns the detail of each job (submission, start and end date, CPUs used and their efficiency, memory used and its efficiency, Slurm script, etc.)
- Slurm accounting: general overview of the HPC workload.
- Job efficiency monitoring (CPU and memory): resources asked, used and wasted.
The HPCNow! monitoring solution is flexible, taking into account the needs of the customer in terms of availability, variables to control and visualization. This new technology is a must for those institutions that are facing cluster congestion issues and want to maximize their return on investment, and/or to keep the cloud bursting budget under control. Additionally, it helps HPC centers to draw a line to define what is reasonable regarding resource usage and educate users on proper cluster usage properly, if they are allocating more resources than needed.
To learn more about implementing monitoring tools to improve efficiency in HPC clusters, follow this link.
Source: HPCNow!
























































