 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetMarch 28, 2023 — Hugging Face today shared performance results that demonstrate Intel’s AI hardware accelerators run inference faster than any GPU currently available on the market, with Habana Gaudi2 running inference 20% faster on a 176 billion parameter model than Nvidia’s A100. In addition, it has also demonstrated power efficiency when running a popular computer vision workload on a Gaudi2 server, showing a 1.8x advantage in throughput-per-watt over a comparable A100 server.
 Today’s generative AI tools like ChatGPT have created excitement throughout the industry over new possibilities, but the compute required for its models have put a spotlight on performance, cost and energy efficiency as top concerns for enterprises today. As generative AI models get bigger, power efficiency becomes a critical factor in driving productivity with a wide range of complex AI workload functions from data pre-processing to training and inference. Developers need a build-once-and-deploy-everywhere approach with flexible, open, energy efficient and more sustainable solutions that allow all forms of AI, including generative AI, to reach their full potential.
Today’s generative AI tools like ChatGPT have created excitement throughout the industry over new possibilities, but the compute required for its models have put a spotlight on performance, cost and energy efficiency as top concerns for enterprises today. As generative AI models get bigger, power efficiency becomes a critical factor in driving productivity with a wide range of complex AI workload functions from data pre-processing to training and inference. Developers need a build-once-and-deploy-everywhere approach with flexible, open, energy efficient and more sustainable solutions that allow all forms of AI, including generative AI, to reach their full potential.
AI has come a long way, but there is still more to be discovered. Intel’s commitment to true democratization of AI and sustainability will enable broader access to the benefits of the technology, including generative AI, through an open ecosystem.
An open ecosystem allows developers to build and deploy AI everywhere with Intel’s optimization of popular open source frameworks, libraries and tools. Intel’s AI hardware accelerators and inclusion of built-in accelerators to 4th Gen Intel Xeon Scalable processors provide performance and performance per watt gains to address the performance, price and sustainability needs for generative AI.
Intel is heavily invested in a future where everyone has access to this technology and can deploy it at scale with ease. Company leaders are collaborating with partners across the industry to support an open AI ecosystem that is built on trust, transparency and choice.
Embracing Open Source Generative AI with Superior Performance
Generative AI has been around for some time with language models like GPT-3 and DALL-E, but the excitement over ChatGPT – a generative AI chatbot that can have human-like conversations – shines a spotlight on the bottlenecks of traditional data center architectures. It also accelerates the need for hardware and software solutions that allow artificial intelligence to reach its full potential. Generative AI based on an open approach and heterogeneous compute makes it more broadly accessible and cost-effective to deploy the best possible solutions. An open ecosystem unlocks the power of generative AI by allowing developers to build and deploy AI everywhere while prioritizing power, price and performance.
Intel is taking steps to ensure it is the obvious choice for enabling generative AI with Intel’s optimization of popular open source frameworks, libraries and tools to extract the best hardware performance while removing complexity. Today, Hugging Face, the top open source library for machine learning, published results that show inference runs faster on Intel’s AI hardware accelerators than any GPU currently available on the market. Inference on the 176 billion parameter BLOOMZ model – a transformer-based multilingual large language model (LLM) – runs 20 percent faster on Intel’s Habana Gaudi than Nvidia’s A100-80G. BLOOM is designed to handle 46 languages and 13 programming languages and was created in complete transparency. All resources behind the model training are available and documented by researchers and engineers worldwide.
For the smaller 7 billion parameter BLOOMZ model, Gaudi2 is 3 times faster than A100-80G, while first-generation Habana Gaudi delivers a clear price-performance advantage over A100-80G. The Hugging Face Optimum Habana library makes it simple to deploy these large LLMs with minimal code changes on Gaudi accelerators.
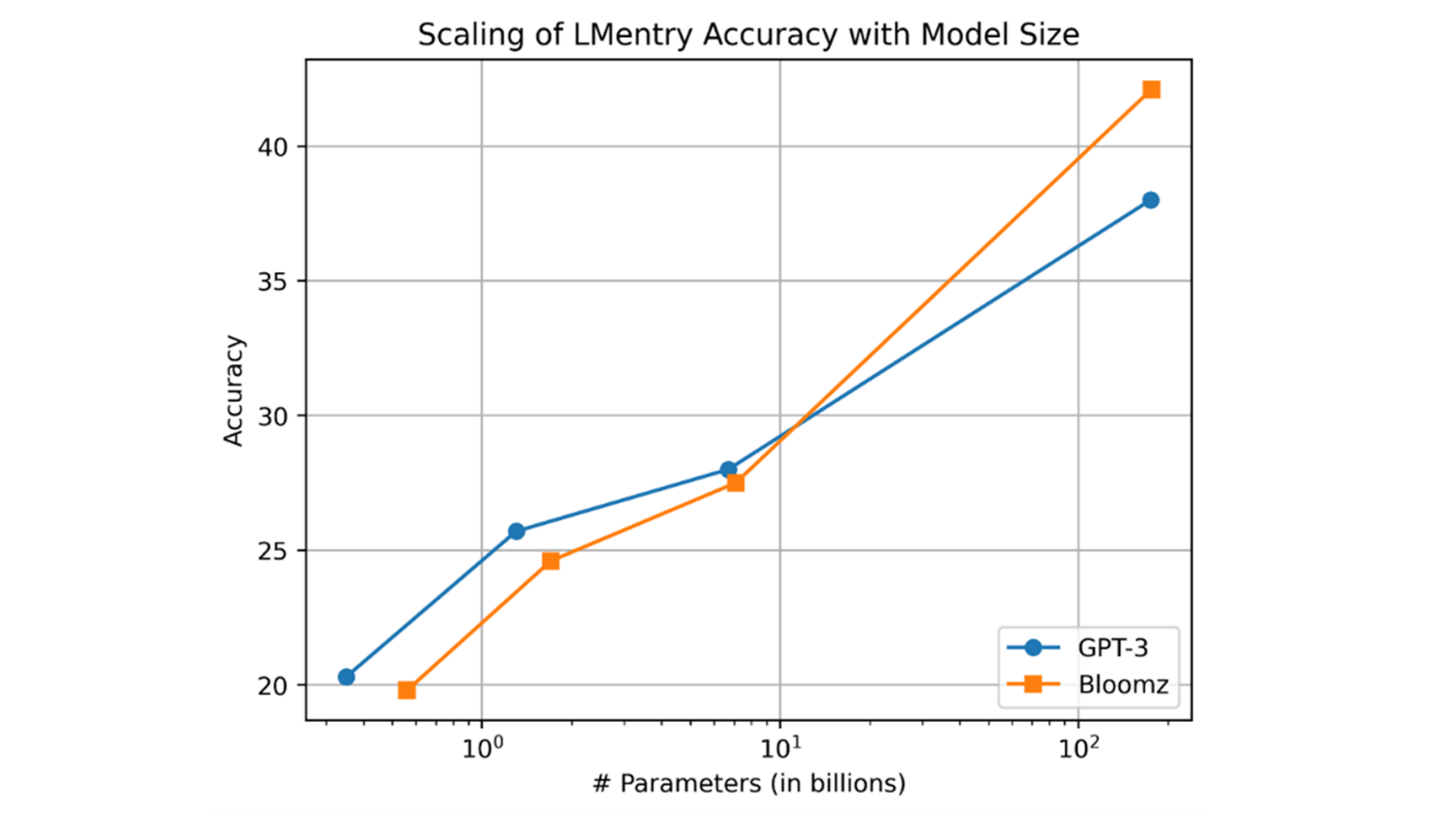
Intel Labs researchers also used Gaudi2 to evaluate BLOOMZ in a zero-shot setting with LMentry, a recently proposed benchmark for language models. The accuracy of BLOOMZ scales with model size similarly to GPT-3, and the largest 176B BLOOMZ model outperforms its similarly sized GPT-3 counterpart as demonstrated by the graphic below.
In addition, Hugging Face shared today that Stability AI’s Stable Diffusion, another generative AI model for state-of-the-art text-to-image generation and an open-access alternative to the popular DALL-E image generator, now runs an average of 3.8 times faster on 4th Gen Intel Xeon Scalable processors with built-in Intel Advanced Matrix Extensions (Intel AMX). This acceleration was achieved without any code changes. Further, by using Intel Extension for PyTorch with Bfloat16, a custom format for machine learning, auto-mixed precision can get another 2 times faster and reduce the latency to just 5 seconds – nearly 6.5x faster than the initial baseline of 32 seconds. You can try out your own prompts on an experimental Stable Diffusion demonstration that runs on an Intel CPU (4th Gen Xeon processors) on the Hugging Face website.
“At Stability, we want to enable everyone to build AI technology for themselves,” said Emad Mostaque, founder and CEO, Stability AI. “Intel has enabled stable diffusion models to run efficiently on their heterogenous offerings from 4th Gen Sapphire Rapids CPUs to accelerators like Gaudi and hence is a great partner to democratize AI. We look forward to collaborating with them on our next-generation language, video and code models and beyond.”
OpenVINO further accelerates Stable Diffusion inference. When combined with a 4th Gen Xeon CPU, it delivers almost 2.7x speedup compared to a 3rd Gen Intel Xeon Scalable CPU. Optimum Intel, a tool supported by OpenVINO to accelerate end-to-end pipelines on Intel architectures, reduces the average latency by an additional 3.5x, or nearly 10x in all.
To continue reading, click here.
Source: Intel


























































