 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetJune 29, 2022 — Intel today announced that its second-generation Habana Gaudi2 deep learning processors have outperformed Nvidia’s A100 submission for AI time-to-train on the MLPerf industry benchmark. The results highlight leading training times on vision (ResNet-50) and language (BERT) models with the Gaudi2 processor, which was unveiled in May at the Intel Vision event.

“I’m excited about delivering the outstanding MLPerf results with Gaudi 2 and proud of our team’s achievement to do so just one month after launch. Delivering best-in-class performance in both vision and language models will bring value to customers and help accelerate their AI deep learning solutions,” said Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group.
With the Gaudi platform from Habana Labs, Intel’s data center team focused on deep learning processor technologies, enables data scientists and machine learning engineers to accelerate training and build new or migrate existing models with just a few lines of code to enjoy greater productivity, as well as lower operational costs.
What It Shows
Gaudi2 delivers dramatic advancements in time-to-train (TTT) over first-generation Gaudi and enabled Habana’s May 2022 MLPerf submission to outperform Nvidia’s A100-80G for eight accelerators on vision and language models. For ResNet-50, Gaudi2 delivers a 36% reduction in time-to-train as compared to Nvidia’s TTT for A100-80GB and a 45% reduction compared to an A100-40GB 8-accelerator server submission by Dell for both ResNet-50 and BERT.

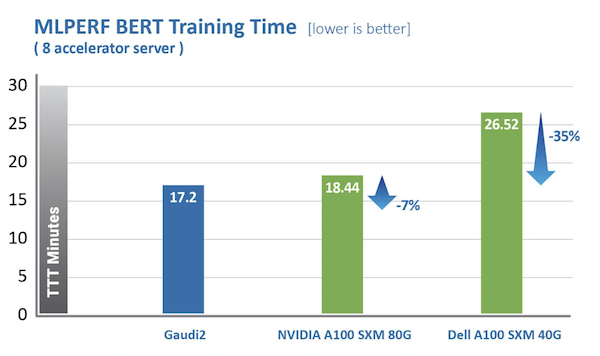
Compared to first-generation Gaudi, Gaudi2 achieves a 3x speed-up in training throughput for ResNet-50 and 4.7x for BERT. These advances can be attributed to the transition to 7-nanometer process from 16 nm, tripling the number of Tensor Processor Cores, increasing the GEMM engine compute capacity, tripling the in-package high bandwidth memory capacity, increasing bandwidth and doubling the SRAM size. For vision models, Gaudi2 has a new feature in the form of an integrated media engine, which operates independently and can handle the entire pre-processing pipe for compressed imaging, including data augmentation required for AI training.
About Out-of-the-Box Customer Performance
The performance of both generations of Gaudi processors is achieved without special software manipulations that differ from the out-of-the-box commercial software stack available to Habana customers.
Comparing out-of-the-box performance attained with commercially available software, the following measurements were produced by Habana on a common 8-GPU server versus the HLS-Gaudi2 reference server. Training throughput was derived with TensorFlow dockers from NGC and from Habana public repositories, employing best parameters for performance as recommended by the vendors (mixed precision used in both). The training time throughput is a key factor affecting the resulting training time convergence:
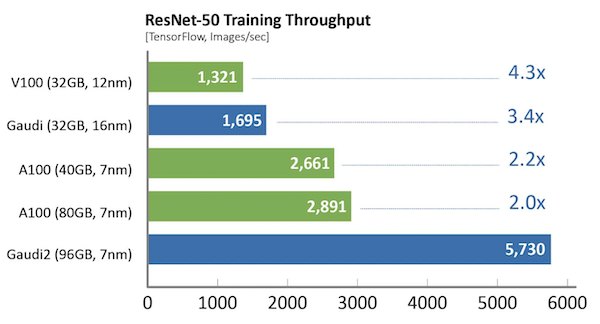

In addition to Gaudi2 achievements noted in MLPerf, the first-generation Gaudi delivered strong performance and impressive near-linear scale on ResNet for 128-accelerator and 256-accelerator Gaudi submissions that support high-efficiency system scaling for customers.
“Gaudi2 delivers clear leadership training performance as proven by our latest MLPerf results,” said Eitan Medina, chief operating officer at Habana Labs. “And we continue to innovate on our deep-learning training architecture and software to deliver the most cost-competitive AI training solutions.”
About MLPerf Benchmarks
The MLPerf community aims to design fair and useful benchmarks that provide “consistent measurements of accuracy, speed, and efficiency” for machine learning solutions. They were created by AI leaders from academia, research labs and the industry who decided on benchmarks and defined a set of strict rules that ensure a fair comparison between all vendors. The MLPerf benchmark is the only reliable benchmark for the AI industry due to its explicit set of rules, which enable fair comparison on end-to-end tasks. Additionally, MLPerf submissions go through a monthlong peer review process, which further validates the reported results.
The Small Print
Test configuration for ResNet-50 Performance Comparison
A100-80GB: Measured in April 2022 by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB using TF docker 22.03-tf2-py3 from NGC (optimizer=sgd, BS=256)
A100-40GB: Measured in April 2022 by Habana on DGX-A100 using single A100-40GB using TF docker 22.03-tf2-py3 from NGC (optimizer=sgd, BS=256)
V100-32GB¬: Measured in April 2022 by Habana on p3dn.24xlarge using single V100-32GB using TF docker 22.03-tf2-py3 from NGC (optimizer=sgd, BS=256)
Gaudi2: Measured in May 2022 by Habana on Gaudi2-HLS system using single Gaudi2 using SynapseAI TF docker 1.5.0 (BS=256)
Results may vary.
Test configuration for BERT Performance Comparison
A100-80GB: Measured in April 2022 by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 22.03-tf2-py3 from NGC (Phase-1: Seq len=128, BS=312, accu steps=256; Phase-2: seq len=512, BS=40, accu steps=768)
A100-40GB: Measured in April 2022 by Habana on DGX-A100 using single A100-40GB with TF docker 22.03-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64,
accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048)
V100-32GB: Measured in April 2022 by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096)
Gaudi2: Measured in May 2022 by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.5.0 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048)
Results may vary.
About Intel
Intel (Nasdaq: INTC) is an industry leader, creating world-changing technology that enables global progress and enriches lives. Inspired by Moore’s Law, we continuously work to advance the design and manufacturing of semiconductors to help address our customers’ greatest challenges. By embedding intelligence in the cloud, network, edge and every kind of computing device, we unleash the potential of data to transform business and society for the better. To learn more about Intel’s innovations, go to newsroom.intel.com and intel.com.
Source: Intel


























































