 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Reminder: You can learn a lot from AWS HPC engineers by subscribing to the HPC Tech Short YouTube channel, and following the AWS HPC Blog channel.
AWS provides an elastic and scalable cloud infrastructure to run high performance computing (HPC) applications, so that engineers are no longer constrained to run their job on limited on-premises infrastructure. Every workload can run on its own on-demand cluster with access to virtually unlimited capacity, and HPC can focus in services to meet the infrastructure requirements of almost any application. This mitigates the risk of on-premises HPC clusters becoming obsolete or poorly utilized as needs change over time.
In this blog post, we will explain how to launch HPC clusters across two Availability Zones. The solution is deployed using the AWS Cloud Developer Kit (AWS CDK), a software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation, hiding the complexity of integration between the components.
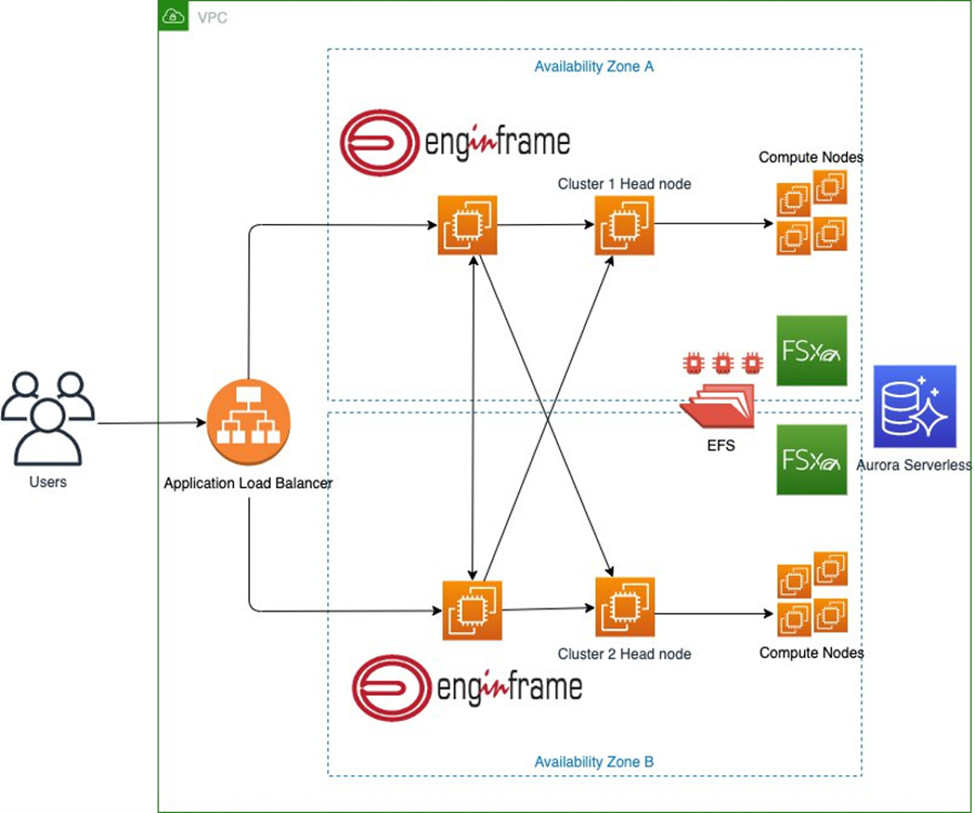
The two clusters are created using AWS ParallelCluster and, the main front end used to access the environment, is managed by EnginFrame in the Enterprise configuration. Amazon Aurora is used by EnginFrame as RDBMS to manage Triggers, Job-Cache, and Applications and Views users’ groups. Amazon Elastic File System is used as shared file system between the two clusters environments. Two Amazon FSx file systems, one per each Availability Zone (AZ), are used as high-performance file system for the HPC jobs.
The configuration covers two different Availability Zones to maintain a fully operational system in case a specific AZ fails. In addition, you can use both Availability Zones for your jobs in case a specific instance type is not available in one of the two Availability Zones.
Figure 1 shows the different components of the HPC solution. The architecture shows how a user interacts with EnginFrame to start an HPC job in the two clusters created by AWS ParallelCluster.
Read the full blog to learn how to deploy a complete highly available Linux HPC environment on AWS.

























































