 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Abstract
Reservoir characterization in the Oil and Gas industry is a process of building a mathematical model of the earth’s subsurface. The model is used to develop a better understanding of the subsurface, improve production profitability, and manage development and exploration risks. Application of a sophisticated geostatistical Markov Chain Monte Carlo algorithm allows for the integration of disparate sources of geological and geophysical data that is critical for successful reservoir characterization. The statistical nature of the algorithm requires generating many independent realizations from the geostatistical model. These realizations can be computed in parallel, but often require extensive amount of compute and storage resources resulting in a substantial upfront investment in capital expense.
The AWS cloud offers a viable, cost-efficient option for deploying a massively scalable HPC architecture.
In this article, we discuss how geoscientists benefit from the cloud elasticity to optimize their workflows when working with models that are getting larger in size and complexity.
The AWS cloud elasticity helps geoscientists to work with geostatistical models of increasing size and complexity.
Introduction
Reservoir characterization in the Oil and Gas industry is a process of building a mathematical model of the earth’s subsurface. This model is used to develop a better understanding of the subsurface, improve production profitability, and manage development and exploration risks. A reservoir characterization that achieves the study objectives is produced by a confluence of factors. These factors rely on sophisticated modeling techniques. The modeling process requires an integrated approach that incorporates multi-disciplinary empirical observations of geological and geophysical nature. The observations typically come with a degree of uncertainty that could be due to measurement noise, poor data quality, data scarcity, and many other factors that complicate empirical data collection in the field. Geoscientists recognize the importance of uncertainty estimation and quantification for mitigating reservoir exploration and development risks. For this reason, geostatistical methods that are based on Bayesian inference are particularly suitable for reservoir characterization. A geostatistical model of the earth’s subsurface is probabilistic in nature and is represented by a probability distribution. The practitioner studies the distribution by obtaining realizations from the model. The procedure is conceptually similar to tossing a coin multiple times to estimate its fairness. While conceptually simple, obtaining a realization from a geostatistical model is far from trivial. The procedure may call for developing a Markov Chain Monte Carlo (MCMC) algorithm[1] that invariably raises the topic of a significant investment in computing power if the results are to be delivered on time. Figure 1 shows examples of highly detailed geostatistical models.
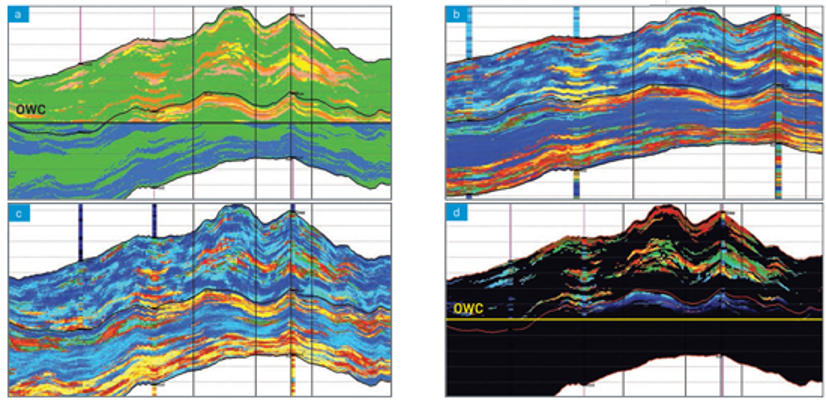
Figure 1 Highly detailed geostatistical models honoring Oil Water Contact: (a) Facies – Green: Shale; Blue: Brine Sand; Yellow: Low Quality Oil Sand; Pink: Mid Quality Oil Sand; Brown: High Quality Oil Sand. (b) Porosity – Gold: 0.28; Blue: 0.01. (c) Volume of Clay – Gold: 0.0; Blue: 0.7. (d) Water Saturation– Gold: 0.0; Black: 1.0.
Computational Challenges
Generating a geostatistical realization is a very compute-intensive process. To begin with, the dimensionality of the model is a challenge. Geoscientists work with datasets that include billions of empirical observations. The amount of input data is only expected to grow over time due to technological advances in data acquisition and storage solutions. In addition to that, there is a clear trend to utilize models with increasing structural complexity. The requirement to produce predictive sub-surface reservoir characterizations at higher levels of resolution is also on the rise. To satisfy these trends and influence business outcomes in a timely fashion, geoscientists need access to virtually unlimited infrastructure (compute, storage) to run their simulations on a pay-as-you-go model.
Another computational challenge is related to the storage solution. A geostatistical study relies on multiple realizations to infer statistically meaningful information. The realizations are independent of each other, thereby by making the problem inherently computationally scalable. At the same time, multiple realizations are also the reason why a geostatistical study produces an order of magnitude more output data than input data. Therefore, parallel computations easily create a bottleneck in the underlying storage solution. Parallel file systems can alleviate this challenge, but it requires an additional overhead to install and manage them locally. There is yet another storage-related factor that comes into play, namely a paradigm shift that is often referred to as “bringing compute to the data”. Cloud-based storage solutions have progressively gained their market share due to their advantageous price, performance, and security characteristics. One important implication of this trend is that the accompanying compute infrastructure needs to migrate with the data to the cloud.
AWS Elastic Services for HPC
AWS offers elastic and scalable cloud infrastructure to run your HPC applications. With virtually unlimited capacity, engineers, researchers, and HPC system owners can innovate beyond the limitations of on-premises HPC infrastructure. AWS HPC services include Amazon EC2 (Elastic Compute Cloud), storage (Amazon S3, FSX for Lustre, etc.), networking (Elastic Fabric Adapter), orchestration (AWS Batch), and visualization (NICE DCV). Many services for implementing HPC workflows. AWS Batch[2], Amazon FSx for Lustre[3], S3[4] are building blocks for even the most demanding HPC applications. The services are readily available on a pay-as-you-go basis with no long-term commitments.
Our deployment architecture follows the AWS HPC reference and production architectures which also proved to be effective at solving compute-intensive Machine Learning (ML) problems. (see Figure 2).

Figure 2: The solution architecture
Next, we would like to highlight factors that are key to the robustness and effectiveness of our solution.
Automation and Programmability: HPC as Code
We use the Python SDK [5]for AWS to manage cloud resources. Automation of cloud deployment operations significantly improves the end-user experience. With programmatically implemented workflows, we strive to minimize if not eliminate any manual user interaction with the AWS portal or services.
Automation is also critical for making the solution cost-effective. It starts with optimal resource selection. For example, the geoscientist doesn’t have to decide upfront on the parameters for a batch compute environment. The software configures batch jobs on the fly with the CPU and RAM requirements based on the estimated model complexity (which changes with a simulation scenario). The Batch compute environment uses the job parameters to provision EC2 instances accordingly. For these types of workloads, which require a higher vcpu/mem to core ratio, M5 instance family was chosen to achieve the best price-performance.
Without going into the mathematical details, we just mention some factors that influence the multi-threaded scalability. Firstly, the algorithm includes several mathematical constraints that guarantee geostatistical continuity of computed properties. Secondly, the algorithm is inherently multiscale, which means that it includes iterations over the data at different levels of resolution. Finally, the algorithm applies domain decomposition, when needed, to guarantee that the calculation fits into RAM.
As a consequence, the multi-threaded component scales well if the computational domain is sufficiently large and the domain decomposition is avoided. Hence is the idea to automate the procedure by programmatically choosing an EC2 instance type with a sufficiently large amount of RAM.
As a side note for CGG’s workload, we noticed performance degradation when using non-dedicated compute nodes for our jobs.
The ”scale on-demand” principle also applies to the selection of the storage option. Figure 3 shows the results for a benchmark test that was conducted with a geostatistical model of medium size and complexity. The horizontal axis represents the number of realizations that were executed in parallel. The vertical axis is the benchmark run time in seconds. The benchmark compares two storage options: AWS Elastic File System[6] (EFS) is shown in blue and FSx for Lustre Scratch SSD 3600 GB is in orange. The important observation from this graph is the scalability trend of the benchmark run time. In this test, EFS fails to provide enough I/O throughput when the number of parallel computations increases. This is not to diminish the value of EFS as a storage solution. The point is that EFS turned out to be a suboptimal choice for this HPC workload, even though it is designed to provide massively parallel access to EC2 instances.

Figure 3: Scalability of storage options for a model of medium size and complexity
Figure 3 shows the results for the above benchmark test with a larger model. Here, we compare scalability across FSx for Lustre file systems of different capacities and throughputs. FSx for Lustre provides scale-out performance that increases linearly with a file system’s size. We would like to emphasize the importance of choosing a scalable storage solution for an I/O intensive HPC workload. A serious I/O bottleneck may significantly degrade run time performance, which invariably leads to a substantially higher computational cost, where the user ends up paying for idle CPU time while waiting on the I/O to complete. (As a point of reference, 30 m5.12xlarge instances utilize 1440 vCPU cores).

Figure 4: scalability of storage options for a model of large size and complexity
Another key to managing pay-per-use cost is the automation of the cloud resource lifecycle. Instead of asking the user to manage it manually, we destroy the resource automatically when it is no longer needed. A cloud deployment execution is implemented as a state machine (refer to Figure 4) that is written in the ASL States language[7] The state machine and its components, such as Lambda functions and execution policies, form a CloudFormation stack[8]. The stack is created programmatically when the user starts a deployment on the client machine. Resource management via CloudFormation is key to provisioning HPC infrastructure as code.
The AWS Step Functions[9] service manages executions of the state machine. A state machine can be shared across simultaneous deployments by running parallel executions. Our state machine execution is idempotent, which makes it possible to restart it. With potentially long execution times, the idempotence is critical for working around the state machine execution quotas[10].
AWS Step Functions simplify our deployment architecture and contribute significantly to the robustness of its operation. Firstly, the service reduces the operational burden by being serverless. As a general rule of thumb, we want native cloud services to manage the infrastructure for us. Secondly, Step Functions make it easy to orchestrate a multi-stage workflow. Our geostatistical computation includes three major stages of operation: 1) a preparation stage that performs miscellaneous model initialization tasks, 2) a core computational stage that is most time and compute intensive, and 3) a post-processing stage that computes multi-realization statistics and quality control metrics. The stages are executed sequentially. Each stage requires a separate configuration for AWS Batch. In addition to that, a data repository task must be executed after each stage, which is critically important for persisting the results to a permanent S3 storage. Finally, automatic destruction of the Fsx for Lustre file system after completing the stages is also crucial for managing pay-per-use cost. Parts of the flow that involve operations with the file system need to be particularly robust in the presence of run-time errors in other tasks. We rely on the built-in error handling capabilities of AWS Step Functions to guarantee robustness of the state machine execution in that respect.
Figure 5 The deployment state machine graph
Fault-tolerant execution is also key to cost-effectiveness. The geostatistical computation may take tens of hours depending on the model complexity and number of realizations. We implement a batch job as a computational graph of subtasks. A subtask introduces a logical place for a “checkpoint” that captures and stores the intermediate computation results. This mechanism makes it possible to restart a batch job automatically from the most recently saved checkpoint and also opens possibilities for further cost reduction by using Amazon EC2 Spot capacity. EC2 Spot allows you to access spare compute capacity at up to a 90% over On-Demand pricing. This feature works in conjunction with the AWS Batch Job Retries functionality. Figure 6 is a conceptual illustration where the second job attempt restarts a failed job with four subtasks from checkpoint number 3.

Figure 6: Fault-tolerant execution
Elastic and cost-effective services
The main purpose of elastic computing is to quickly adapt to workload demands driven by business needs. AWS Batch autoscaling makes thousands of CPUs available in a matter of minutes. Batch Compute Environment automatically adjusts its capacity based on monitoring of the Job Queue. A variety of EC2 instances are readily available to accommodate batch jobs with the most demanding requirements in terms of memory and the number of CPUs. This is a game changer for CGG and its customers. Geoscientists can now rent a super computer at a fraction of the cost compared to deploying an on-premises cluster and complete these workloads within a few hours as opposed to running for few days to weeks on limited on-premises infrastructure. A quantitative change in the availability of computing power leads to more opportunities for a qualitative change in the results with more scenarios of models with greater complexity to simulate and improve the uncertainty estimation. The same argument applies to the elastic storage solution. As previously stated, the concurrent computations produce a substantial amount of file I/O that quickly becomes a bottleneck on a traditional network file system (NFS). The FSx for Lustre service delivers a fully managed parallel file system that can sustain millions of IOPs and hundreds of gigabytes per second throughput[11].
Interoperability of Cloud Services
Simply put, AWS services work well together. The interoperability of the services is seamless and optimized to avoid potential bottlenecks, which is essential for healthy and robust operation. A notable example would be the integration of EC2, AWS Batch and FSx for Lustre. The services manage a substantial amount of infrastructure, yet getting access to an FSx file system from a Docker container is straightforward and can be summarized in two steps: 1) install Lustre client in the container and 2) mount the file system. The Lustre client can be pre-installed in the Docker image. The mount command can be generated programmatically and added to the batch job script at run time. When implemented this way, the container image does not depend on a pre-existing FSx for Lustre file system. Decoupling the Docker images from specifics of a particular computational job adds an extra layer of flexibility to the architecture.
Data Repository Task is another example of the interoperability that streamlines the design. The task manages data transfer between Amazon FSx for Lustre file system and durable repository on Amazon S3 (refer to Figure 1). We’ve observed backup rates close to 1GB/sec, which is sufficient for our needs. It is important to note that the speed depends on the FSx size and it scales linearly. Data Repository Task significantly simplifies and optimizes the storage component of the architecture to the point where the FSx storage option becomes a deployment implementation detail that does not need to be exposed to the user.
Technical Support by AWS Architects
Last but not least, CGG would like to thank a team of AWS architects for their support and guidance. On a special note, we would like to mention the effectiveness of the AWS Well-Architected review of our solution that they conducted with CGG. Both the review procedure and its outcome provided very valuable insight to the development team.
Conclusion
The AWS cloud is a good choice for deploying HPC workloads. It offers scalable, elastic services at a compelling price/performance ratio. CGG conducted numerous pre-production tests to assess levels of performance and throughput while focusing on the specifics of our problem domain. The tests confirmed that the cloud-based solution is capable of handling the most demanding geostatistical workflows.
[1] https://en.wikipedia.org/wiki/Markov_chain_Monte_Carlo
[4] https://aws.amazon.com/s3/

























































