 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Organizations migrate their high performance computing (HPC) workloads from on-premises infrastructure to Amazon Web Services (AWS) for advantages such as high availability, elastic capacity, latest processors, storage, and networking technologies; all of this at a pay-as-you go pricing. These benefits empower engineering teams to scale compute- and memory-intensive workloads such as Finite Element Analyses (FEA) effectively in order to reduce costs and achieve faster time-to-results.
As the major portion of the costs incurred for running FEA workloads on AWS comes from the usage of Amazon EC2 instances, Amazon EC2 Spot Instances offer a cost-effective architectural choice. Spot Instances allow you to take advantage of unused EC2 capacity, and are available at up to a 90% discount compared to On-Demand Instance prices.
In this post, we describe how engineers can run fault-tolerant FEA workloads on Spot Instances using Ansys LS-DYNA’s checkpointing and auto-restart utility, and continue to leverage the cost benefits of Amazon EC2 Spot Instances.
How Spot Instances work
Spot Instances are spare EC2 compute capacity in the AWS Cloud available for steep discounts off On-Demand Instance prices. In exchange for the discount, Spot Instances come with a simple rule – they are interruptible and must be returned when EC2 needs the capacity back. The spare EC2 capacity comes from the excess capacity due to unpredictable demand at any given time for all the 375+ instance types across 77 Availability Zones (AZ) and 24 Regions. Rather than let that spare capacity sit idle and unused, it is made available to be purchased as Spot Instances.
The location and amount of spare capacity available at any given moment is dynamic and continually changes in real time. This is why it is important for Spot Instance customers to only run workloads that are truly interruption tolerant. Additionally, Spot Instance workloads should be flexible, meaning they can be shifted in real time to where the spare capacity currently is (or otherwise be paused until spare capacity is available again). For more information on how Spot Instances work, refer to this whitepaper.
Solution overview
Ansys LS-DYNA checkpointing utility, known as the lsdyna-spotless toolkit, uses the mechanism for monitoring the simulation jobs on Spot Instances as shown in the following architecture diagram (Figure 1).
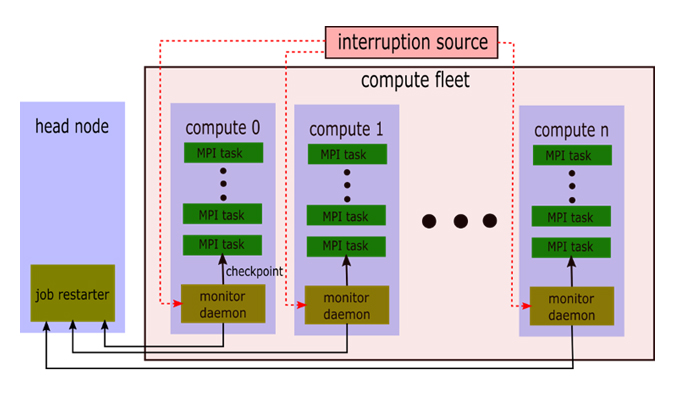
Figure 1: Architecture for monitoring spot interruptions and restarting jobs.
The flow represented in the above architecture is explained in the high-level steps below:
- User submits a single (or a set of) Ansys LS-DYNA jobs on the cluster head node.
- Each job is split in multiple Message Passing Interface (MPI) tasks based on the user input.
- The monitor daemon, poll, is dispatched to each compute node to poll for instance interruption signal from the EC2 metadata for all the MPI tasks.
- On receiving the interruption signal, a checkpoint of the running simulation is created and saved on /shared drive accessible by both the head and compute nodes.
- The job restarter daemon, job-restarter, resubmits the job to the cluster queue when the desired capacity is back again.
Now that you have an overview of the utility and the commands involved, let us now review the detailed steps involved in setting up Ansys LS-DYNA simulation environment with the lsdyna-spotless utility. This will help you understand its impact on overall instance costs.
Simulation environment setup
The LS-DYNA simulation environment can be set up on the cluster head node using the following steps:
- Download and install the latest Ansys LS-DYNA version on the head node. Version R12 is used for this blog. Download the toolkit from this GitHub repository, and unzip the downloaded package.
- Some customization options are provided in the env-vars.sh
- Set the MPPDYNA variable to the path of the Ansys LS-DYNA executable.
- Variables for license server and SLURM queue are updated with the appropriate path and queue name, respectively.
Read the full blog to learn how Ansys LS-DYNA’s new checkpointing utility allows engineers to run their FEA workloads on Spot Instances by accounting for any instance interruptions.
Reminder: You can learn a lot from AWS HPC engineers by subscribing to the HPC Tech Short YouTube channel, and following the AWS HPC Blog channel.























































