 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
OpenACC is strutting its stuff at ISC this year touting expanding membership, a jump in downloads, favorable benchmarks across several architectures, new staff members, and new support by key HPC applications providers, ANSYS, for example. It is also holding its third user group meeting at the conference and a number of other activities including a BoF. That seems like significant progress in its rivalry with OpenMP.
Parallel programing models, of course, have become de rigueur to get the most from HPC systems, especially with the rise of manycore, GPU, and other heterogeneous architectures. OpenACC formed in 2011 to support parallel programing on accelerated systems. In its own words, OpenACC “is a directives-based programming approach to parallel computing designed for performance and portability on CPUs and GPUs for HPC.”
There are now roughly 20 core members – Cray, AMD, Oak Ridge National Laboratory, and Indiana University, to name a few. OpenACC reports downloads jumped 86 percent jumped in the last six months, driven in part by a new free community release that also supports Microsoft Windows. Interestingly, support for Windows which is a rarity in core HPC was very important to ANSYS according Michael Wolfe, OpenACC technical lead and a PGI staff member. The current OpenACC version is 2.5 with 2.6 expected to be available for public comment in the next couple of months.
As shown in the slide below, OpenACC has steadily expanded the number of platforms supported. It’s an impressive list although notably absent from this list is ARM. Before it ceased operations PathScale supported ARM and currently the GCC group (GNU Compiler Group) is working on OpenACC support for ARM. Leading compiler provider PGI, owned by NVIDIA, also has plans. “It’s no secret that our plan is to eventually support ARM and we’ll be using the same mechanism we used to support Power and so the compiler part is relatively straight forward. It’s getting the numerical libraries in place [that’s challenging],” says Wolfe.
Significantly, OpenACC is reporting rough parity with OpenMP for application acceleration on a pair of Intel systems and an IBM Minsky when compared with a single core Haswell system. (Reported systems specs: Intel dual Haswell – 2×16 core server, four K80s; dual Intel Broadwell – 2×20 core server, eight P100s; IBM dual Minsky – Power8+ NVLINK, four P100s; host systems for GPUs not listed. The application was AWE Hydrodynamics CloverLeaf mini-app.)
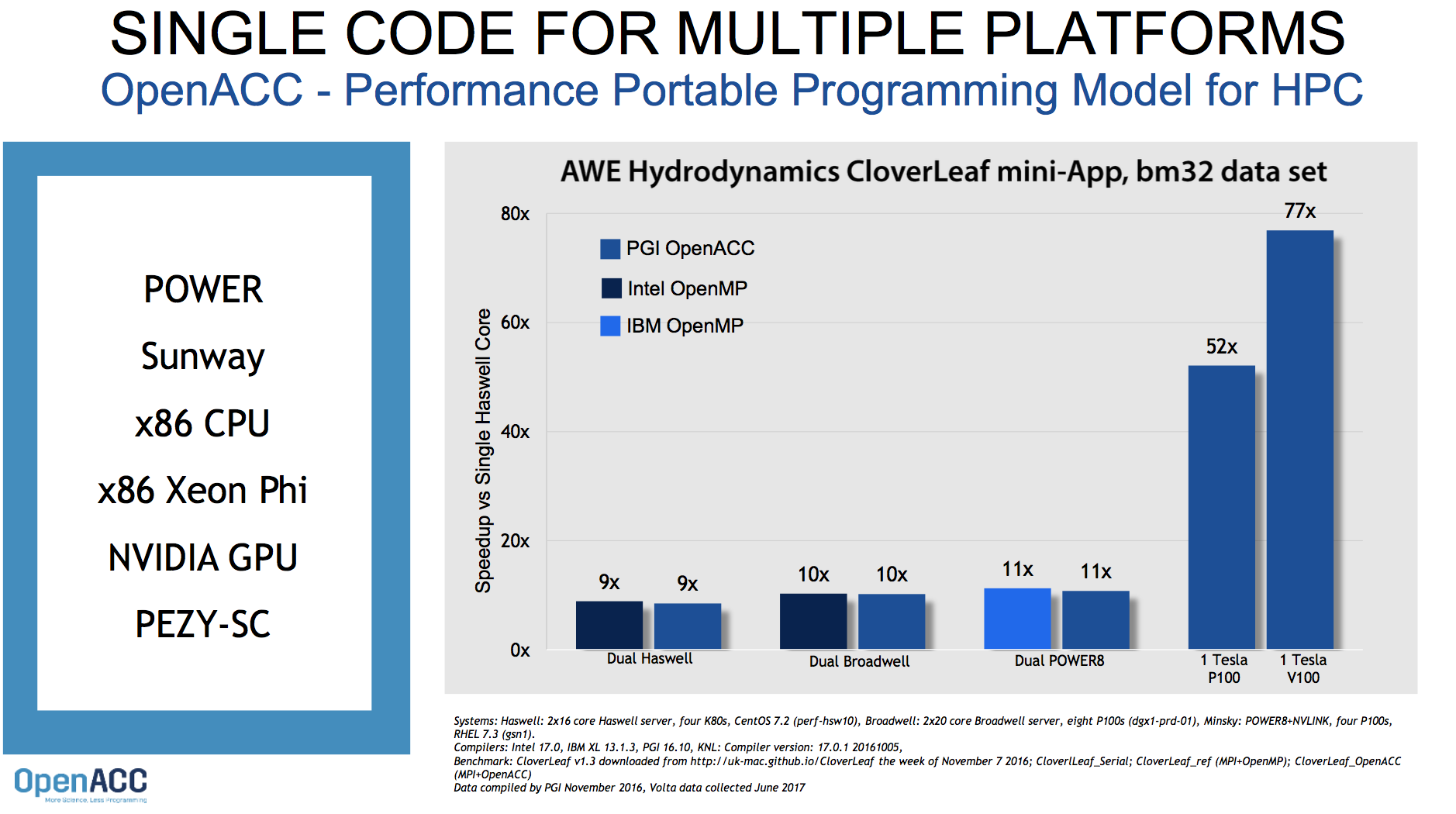
“You get almost no performance decrement on a multicore on the various systems,” notes Wolfe. OpenACC hasn’t yet benchmarked against Intel’s forthcoming Skylake. “We’re waiting on it. Obviously we need to re-optimize our code generator.”
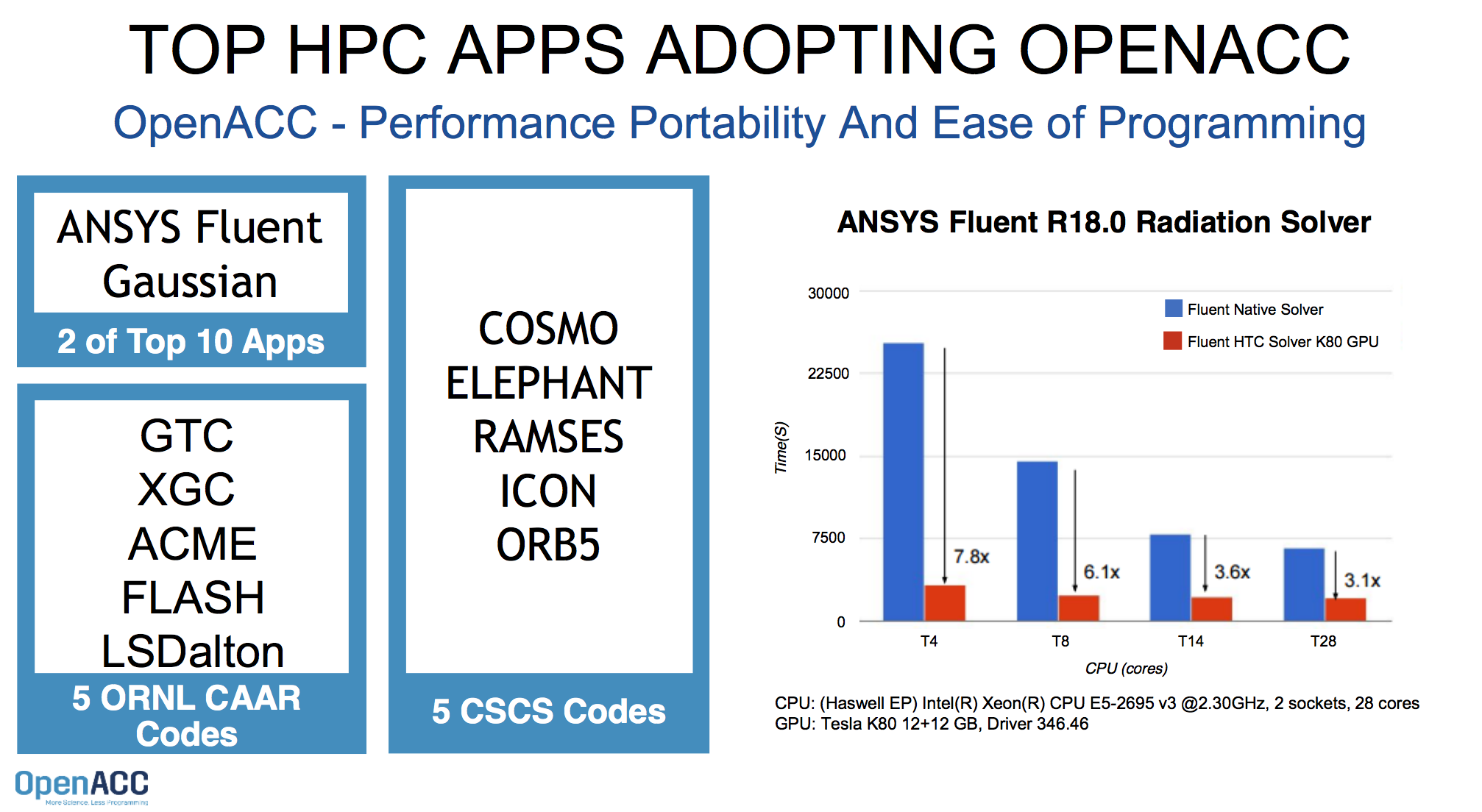
Perhaps most telling, say OpenACC proponents, is the uptick in support from HPC application community. In its ISC new release, OpenACC reported it now accelerates ANSYS Fluent (CFD) and Gaussian (Quantum Chemistry) and VASP (Material Science), which are among the top 10 HPC applications, as well as selected ORNL Center for Accelerated Application Readiness (CAAR) codes to be run on the future CORAL Supercomputer: GTC (Physics), XGC (Physics), LSDalton (Quantum Chemistry), ACME(CWO), and FLASH (Astrophysics).
“Early indications are that we can nearly match the performance of CUDA using OpenACC on GPUs. This will enable our domain scientists to work on a uniform GPU accelerated Fortran source code base,” says Martijn Marsman, Computational Materials Physics at the University of Vienna in the official press release.
“We’ve effectively used OpenACC for heterogeneous computing in ANSYS Fluent with impressive performance. We’re now applying this work to more of our models and new platforms,” says Sunil Sathe, lead software developer, ANSYS.
OpenACC also reports the recently upgraded CSCS Piz Daint supercomputer will be running five codes implemented with OpenACC in the near term: COSMO (CWO), ELEPHANT (Astrophysics), RAMSES (Astrophysics), ICON (CWO), ORB5 (Plasma Physics).
Two new OpenACC officers have been appointed:
-

Guido Juckeland Guido Juckeland is the new secretary for OpenACC. He founded the Computational Science Group at Helmholtz-Zentrum Dresden-Rossendorf (HZDR), Germany. His research focuses on better usability and programmability for hardware accelerators and application performance monitoring as well as optimization. He is also vice-chair of the SPEC High Performance Group (HPG) and an active member of the OpenACC technical.
-

Sunita Chandrasekaran Sunita Chandrasekaran is the new director of user adoption. Her mission is to grow the OpenACC organization and user community. She is currently an assistant professor at the University of Delaware. Her research interest spans HPC, parallel algorithms, programming models, compiler and runtime methodologies and reconfigurable computing. She was one of the recipients of the 2016 IEEE TCHPC Award for Excellence for Early Career Researchers in HPC.

Wolfe says the forthcoming 2.6 release is mostly a matter of tweaks. One change in the works which is substantive is Deep Copy capability.
“Many of these programs have very complex data structures. If you think about supercomputing you think about arrays, vectors, and matrices. [But] that’s so 1970s. Now these applications will have an array of structures and each structure element has a subarray which is a different. On today’s devices, in order to get most performance on the GPU, you need to move the data onto the GPU memory which is higher bandwidth, closer to the device,” says Wolfe.
“Deep copy doesn’t just copy the array but copies that and all the subarrays and all the subarrays. There is a mechanism to support this today but it is clunky [and] requires a lot of code. We are trying to automate that but we are afraid we are going to get it wrong. So what we are doing now in the PGI compiler, we are working on a prototype application before we standardize something in the classification,” says Wolfe.























































