 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
HPCers can get painted as a monolithic bunch by outsiders, but internecine disagreements abound over the HPCest of HPC jargon, as was evident at ISC this week.
Ask four HPC leaders about Linpack’s relevance, get four distinct answers — and that’s just what happened at the Monday Top500 panel. During the panel, moderator Horst Simon (Top500 co-author and deputy lab director of Lawrence Berkeley National Lab) asked panelists Yutong Lu, Steve Conway, Thomas Schulthess and Steve Scott about the limitations surrounding Linpack and what needs to be changed at the Top500.
Yutong Lu, National Supercomputing Center in Guangzhou, China, and ISC 2019 Program Chair:
“I think the performance for the supercomputer will be the eternal target because people will always ask and care about how much faster the supercomputer could run, and what’s the highest performance that can be reached. But I think that the metrics could be changed. If you look back 20-or-more years, the computational power was the bottleneck of the full system, so the HPL was a good benchmark at that time and continued to be over the past 20 years. But now we all note that the data access and ability have become the bottleneck of the system, so we obviously need some new benchmarks to measure that part. That will be something we need to change.”
Steve Conway, COO of Hyperion Research:
“The Top500 is great as a census of elements affecting large supercomputers over time, but it’s often been interpreted–as it was never intended to be–as a predictor of performance over a spectrum of HPC code. One thing that could be valuable is a warning like on the cigarette label that says ‘this could be fatal if you use it as a predictor.’ But I was very pleased to see the attention paid to HPCG and the Green500 and the inclusion of those lists. My only recommendation would be to give those equal promotional strength.”
Thomas Schulthess, Director of the Swiss National Supercomputing Centre (

“I have quite a different opinion. The relevance today is clearly from a political point of view and a funding point of view. From an application performance point of view the story is very different. It even comes to the point where the Top500 may actually be a distraction if you have certain goals on the application side. And let me give you an example: there is the TaihuLight system in Wuxi, and the Piz Daint system that I have a lot of authority over. When you look at the flops, TaihuLight is on top with a factor of five difference. When you look at how the benchmark from the weather and climate community performs–the baroclinic instability test–then the order is reversed and the performance of Piz Daint is about two to three times faster.
“We’ve been thinking about this quite a bit…and it turns out that flops is not a good metric to design systems against. It may be good to track and look back retroactively, but not looking into the future. The conclusion is that we need a metric that relates to a scientific goal: so simulated years per day for the given size of the problem. And it is very important that the size of the problem factors in. Remember in the Top500 the HPL we do the size of the problem to maximize this metric of flops. We can do the same with HPCG. It turns out from an engineering point of view that this is not good. If you’re paid to do something, you’re not going to change your target just to maximize some number. That’s a really bad idea.
“We need to set goals. In weather and climate I think we have very clear goals that everybody can relate to, and I wish that the scientific community could come together behind a few goals rather than everybody wanting their own goal to be the metric. So not just some performance metric, but the size of the problem needs to be set, and can be varied over time. But we need to compare apples to apples, and not apples to oranges. And the last point that is really missing in the Top500 is the algorithmic or the method side. Changing algorithms in the history of computing is just as important as changing architectures.”
Steve Scott, Cray SVP and Chief Technology Officer:
“From a scientific perspective I couldn’t agree with you more. From a practical perspective I can’t agree with you at all.
“I would love to see simulated years per day as a much more interesting and useful metric, but there’s no way that you could do that. And you can’t really change the metric that the list uses because it sort of invalidates that historical record aspect. So we have to count on people that are actually doing these procurements and fielding these big systems to be sophisticated people who understand what’s really important and that Linpack is not that thing; and I absolutely think that the Top500–despite all of the good that it’s done–has caused some bad behavior. People have made decisions to get to a higher ranking on that list. And then there’ve been other people who have said ‘I’m going to buy a supercomputer and I’m not even going to put it on the list, because I don’t endorse the metric.’ I think the reality is that you’re not going to be able to change the Top500 benchmark. I like the idea of augmenting it with some things, and there’ve been some attempts with HPCG and the HPCC benchmarks. So we can augment it; I don’t think we can change it.
“I think that the HPL performance is becoming more and more disjointed from real application performance as we go forward, and memory bandwidth and interconnects and other things matter a lot more. Architectural aspects matter. As we get closer to the end of the CMOS era and we may change the way we do computing or go to completely different architectures, it may become even more strained to the point where we have to do something. But in the meantime I’m not sure there’s a whole lot we can do other that continue on the current path.”
Is it Exascale?
At ISC and on #HPC Twitter, discussion has also turned to the “true meaning” of exascale; take this tweet thread for example:
.@ORNL Summit ~120 PF #Supercomputer Is Officially Here – by @TiffanyTrader in @HPCwire
If Summit achieves the Linpack score that we’ve heard projected, roughly 120-petaflops, the US could retake the #Top500 crown from China, pending no surprises.https://t.co/vaRx4mbDze #HPC
— HPC Guru (@HPC_Guru) June 8, 2018
@HPC_Guru @hpcnotes I confess I’m fairly persuaded this constitutes “exascale.” For the science teams that are at 1+ exaop and people/societies that will benefit over time from this work, the details of precision level seem fairly trivial. Disagree?
— Evan Burness (@evanburness) June 9, 2018
I think for the purposes of the #HPC community, we should stick to the usual definitions of #Exascale – ie aggregate double precision floating point performance (peak or HPL) of a single system. Data processing, non-HPC-cloud or ML folk are welcome to their own definitions 🙂
— Andrew Jones (@hpcnotes) June 10, 2018
The discussion was further unpacked in this fun exchange from the ISC Analyst Crossfire put on by Intersect360 Research CEO Addison Snell with panelists Depei Qian (Sun Yat-Sen University & Beihang University), Stephan Schenk (BASF SE), Alex Bouzari (DDN), and Ian Colle (HPC at Amazon Web Services).
“Exascale is a term that’s driving me nuts because it has no exact definition,” said Snell, who proceeded to proffer variations of potential exascale definitions to get panelists’ quick takes.
The panelists all agreed that “exa-levels of something non-computational, like an exabyte of storage under one namespace or if you could magically have an exabit/sec of bandwidth” were not exascale, with one panelist offering that “exascale is whatever gets politicians to fund industry.”
The concept of whether 10 to the 18th flops per second at reduced/mixed precision should be called exascale drew one yes, another reference to funding, and consensus from the other panelists, the moderator and yours truly that that was moving the goalposts.
As for whether 10 to the 18th flops theoretical peak with no Linpack or other benchmark or application gets you to exascale, the panelists were unanimous in that it does not, with a comment that “the only thing Linpack does is it gets funding from politicians,” and another that “if our focus is on doing real work, no.”
In the final scenario, Snell asked whether exaflops for a loosely coupled non-HPC application like SETI@home counts as exascale. That drew three no’s and another nod to the market opportunity.
HPC Secrets
The open secrets of HPC are in the crosshairs this week, as illustrated by Andrew Jones’ article published by our friends at the Top500 News.
The increased prevalence of IT/Web-scale systems (close to half the list now) means it’s not in verity a list of 500 supercomputers or HPC clusters. But it was so-called list stuffing via duplicate systems (or large deployments parceled so as to optimize system share) that came to wider attention this week when Lenovo claimed 117 of the 500 machines, becoming the largest Top500 provider as measured by number of systems. It needs to be said that Lenovo didn’t invent the practice–but they have mastered it (the company lists 56 duplicate entries). It should also be said that they have not, to our knowledge, broken any rules.
A search through the annals of the list shows duplicate serial entries exist going back to at least 2010. The practice slowed down after Lenovo purchased IBM’s x86 business in 2014 and ramped up again a year later as Lenovo (and other vendors) figured out how to amplify their list presence, both through system slicing or increased benchmarking of Web/IT machines. The effect shows up as a dip in 10G Ethernet (rise in InfiniBand) and the subsequent climb of 10G Ethernet in that timeframe.
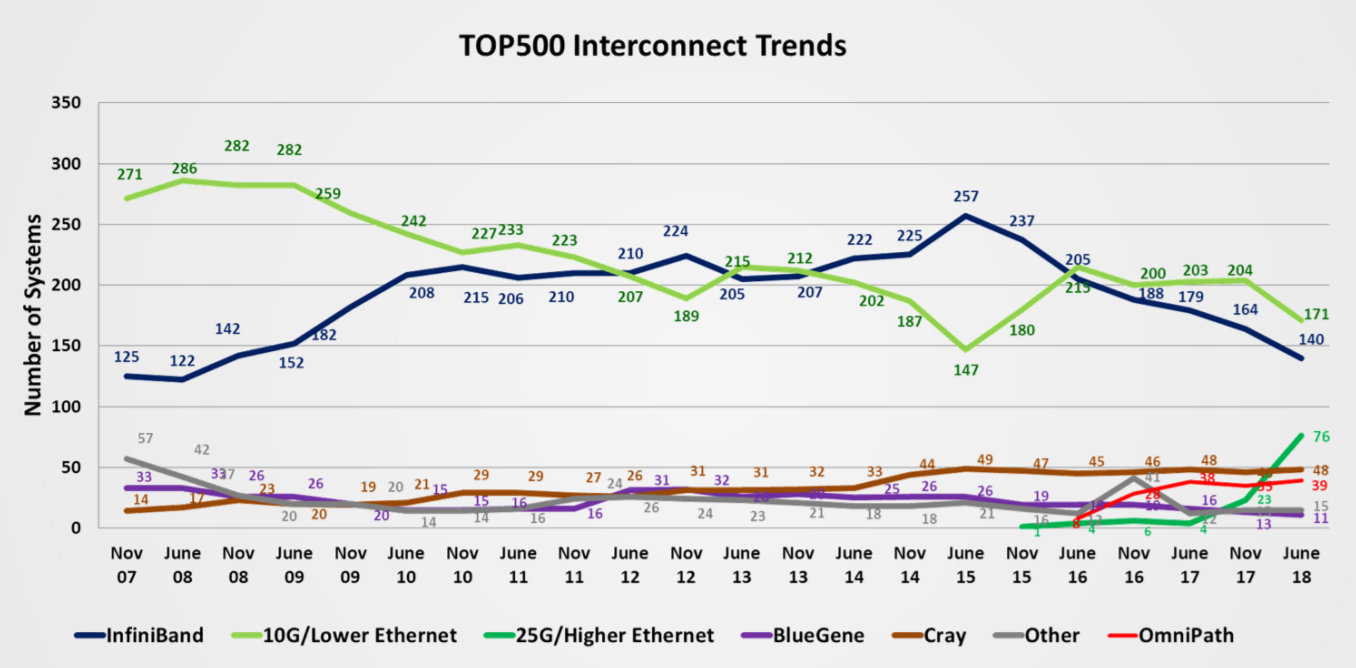
My read is that there was a collectively accepted threshold at which cloud/IT systems and creative system splicing were tolerated, and now that line may be breached. How or whether the problem will be addressed is not clear to me. It’s not as simple as removing anonymous submissions, since anonymity is requisite for industrial representation (as Jones pointed out). Hundreds of NDA site visits obviously aren’t feasible. Top500 Co-author Eric Strohmeier indicated in the Top500 press briefing on Monday that his group knows “reasonably well” who is using the anonymously listed systems; but what is more challenging is tracking down whether a submission is really configured the way it is claimed. Due to some game-playing in the past, system configurations must now be frozen, so that if systems are parceled up into small increments to get a high system count, those systems cannot then be reconfigured into a larger system to keep from falling off.























































