 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In this bimonthly feature, HPCwire will highlight newly published research in the high-performance computing community and related domains. From exascale to quantum computing, the details are here. Check back on the first and third Mondays of each month for more!
Using Thrill to process scientific data on HPC
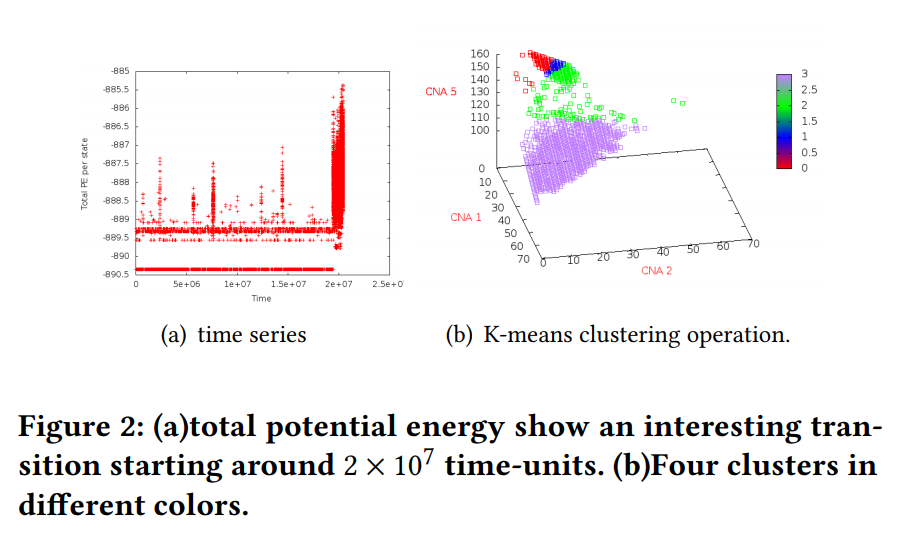
Researchers are asking HPC systems to process larger and larger datasets. In this research, conducted by a team from Clemson University, University of Wyoming, University of New Mexico, University of California – Santa Cruz, and Los Alamos National Laboratory, the authors examined “Thrill,” a framework for big data computation on HPC clusters. The authors successfully implemented several big data operations with less programming effort than hand-crafted data processing programs.
Authors: Mariia Karabin, Supreeth Suresh, Xinyu Chen, Ivo Jimenez, Li-Ta Lo, and Pascal Grosset
Improving power efficiency through fine-grain performance monitoring in HPC clusters
Energy consumption is a major (and growing) consideration for HPC systems as they approach the exascale era. This paper, written by Mathieu Stoffel and Abdelhafid Mazouz, describes how the authors developed a tool that sampled CPU performance metrics and applied that data to achieve up to 16 percent energy savings at a performance degradation under 3 percent.
Authors: Mathieu Stoffel and Abdelhafid Mazouz
Integrating HPC systems and public web-based geospatial data tools
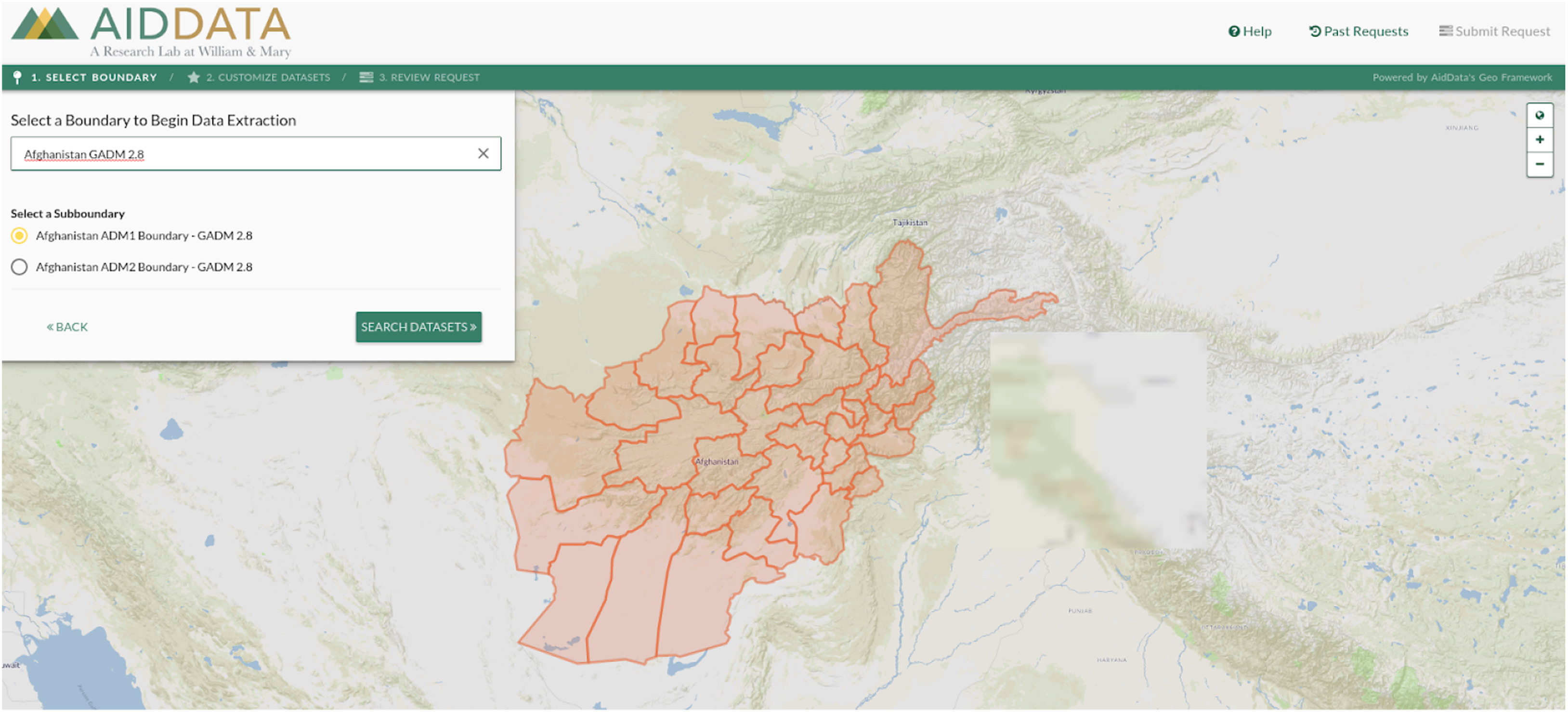
Utilizing geospatial data often involves reconciling data from a variety of disparate sources, which can be hindered by geocomputational challenges. This paper, written by a team from the College of William and Mary, discusses GeoQuery – a dynamic web application utilizing an HPC cluster and parallel geospatial data processing. The authors discuss how GeoQuery reduces the barriers to geospatial data processing in geocomputation.
Authors: Seth Goodman, Ariel BenYishay, Zhonghui Lv, and Daniel Runfola
Analyzing three case studies from the Titan supercomputer log
Reliability, availability and serviceability (RAS) logs of HPC systems can provide valuable information about system performance, but their sheer volume makes them difficult to analyze and many subsystems can produce many different logs. In this paper, a team from ORNL developed a multi-user big data analytics framework for HPC log data. They tested the framework on three in-progress data analytics projects and detail their workflows.
Authors: Byung H. Park, Yawei Hui, Swen Boehm, Rizwan A. Ashraf, Christopher Layton, and Christian Engelmann
Detecting anomalies using autoencoders in HPC systems
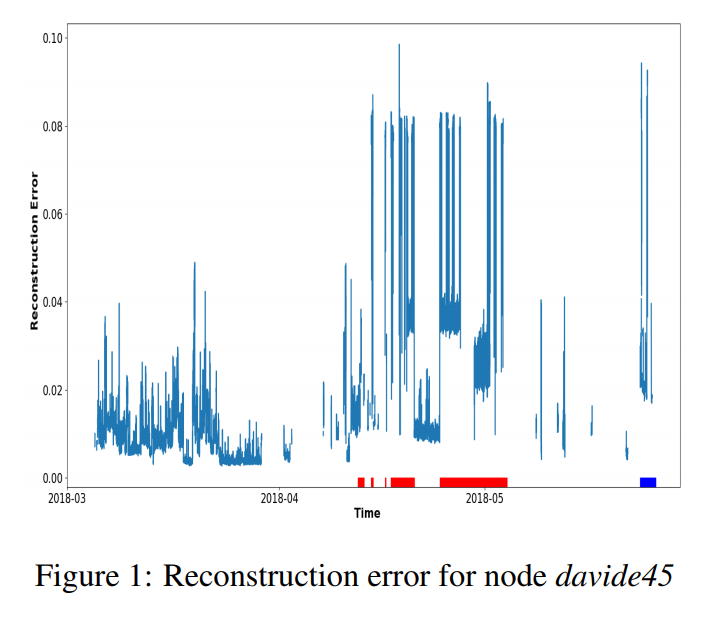
It can be difficult to detect anomalies in HPC systems due to their scale and disparate components. In this paper, written by a research team from the University of Bologna, the authors propose a machine learning technique for anomaly detection – a type of neural network called an “autoencoder.” The authors teach the model the behavior of a normal supercomputer and then use it to identify abnormal conditions on a real supercomputer, citing promising results.
Authors: Andrea Borghesi, Andrea Bartolini, Michele Lombardi, Michela Milano, and Luca Benini
Scaling and resilience in numerical algorithms for exascale computing
Scaling applications to petascale machines can result in low parallel efficiency due to an absence of applications that scale to the machines’ full capacity. In this thesis, written by Allan Svejstrup Nielsen of the École Polytechnique Fédérale de Lausanne, the author argues that those issues are likely to worsen in the exascale era. He goes on to outline modifications to numerical algorithms to make them better-suited for future exascale machines, then suggests new ways to mitigate the impact of hardware failures.
Author: Allan Svejstrup Nielsen
Using HPC for simulating flows in industrial devices
Turbulent flow equations are solved through large eddy simulation and direct numerical simulation. Owing to the size of the grid and finer timescales, both simulation types are extremely complex, necessitating parallel computing resources. This paper, written by Somnath Roy of the Indian Institute of Technology, reviews computational efforts to handle these flow simulations for industrial devices, including distributing computing, GPU accelerated computing, and others.
Author: Somnath Roy
Do you know about research that should be included in next month’s list? If so, send us an email at [email protected]. We look forward to hearing from you.























































