 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Artificial Intelligence (AI) is now mainstream and is already a key element of today’s global economics and scientific research. AI systems today are even becoming our colleagues and teachers, and even our trusted co-workers.
Organizations in every industry are adopting AI strategies to out-smart the competition and deliver the best solutions, and these AI strategies depend on data; in-fact the more data the better. Arguably, the network is the most important element within the architecture of systems designed for the modern-day data center that employ the latest advancements in GPU technology, memory and storage. InfiniBand, which is the most widely adopted high-performance network technology in the world for High-Performance Computing (HPC) has grown over the years to become the most widely adopted high-speed network deployed in all areas of AI, including those used for advanced research, development and critical business deployments.
Complex Computations and Fast, Efficient Data Delivery
Machine learning workloads are extremely resource intensive, and typically depend upon hardware acceleration to achieve the performance necessary to solve large, complex problems in a timely manner. Especially where deep learning models are employed, which may contain millions or even billions of parameters and use terabytes of data to train, efficient hardware acceleration is needed to distribute the workload across multiple machines. Training such models will benefit from access to more GPUs, so parallelizing the workload boosts performance by reducing the training time. But keep in mind, a high-bandwidth and low-latency data pipe is required to keep those GPUs busy and prevent them from just stalling while waiting on the data to arrive. This is where InfiniBand becomes the critical enabler for scalable distributed machine learning.
Purpose-Built AI Infrastructure
InfiniBand, like Ethernet, is based on industry standards, but delivers very high throughput, extremely low latency and the highest message rates in the industry. It is also world renown for providing best-in-class network performance, scale and efficiency. The InfiniBand performance and technological advantage over Ethernet, for both compute and storage infrastructures, make it the perfect match for the unprecedented compute density, performance, and flexibility of the latest NVIDIA DGX A100 – the world’s first 5 petaFLOPS AI system. As with previous generations of DGX systems purpose-built with InfiniBand technology, the DGX A100 includes HDR 200Gb/s InfiniBand as the de-facto standard fabric for building large-scale AI infrastructures, including DGX POD and DGX SuperPOD.
SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) is a technology which improves the performance of collective operations by processing the data as it traverses the network, eliminating the need for sending data multiple times between endpoints. This innovative approach not only decreases the amount of data traversing the network, it offers additional benefits including freeing valuable CPU/GPU resources for computation rather than using them to process communication overhead.
SHARP offers even more capabilities specifically designed around the needs for machine learning. Since the introduction of HDR 200Gb/s technology, the NVIDIA Mellanox Quantum InfiniBand switch includes support for large data reductions of up to 2 Gigabytes; along with a ton of additional capabilities.
AI and Deep Learning Get a Significant Boost with SHARP
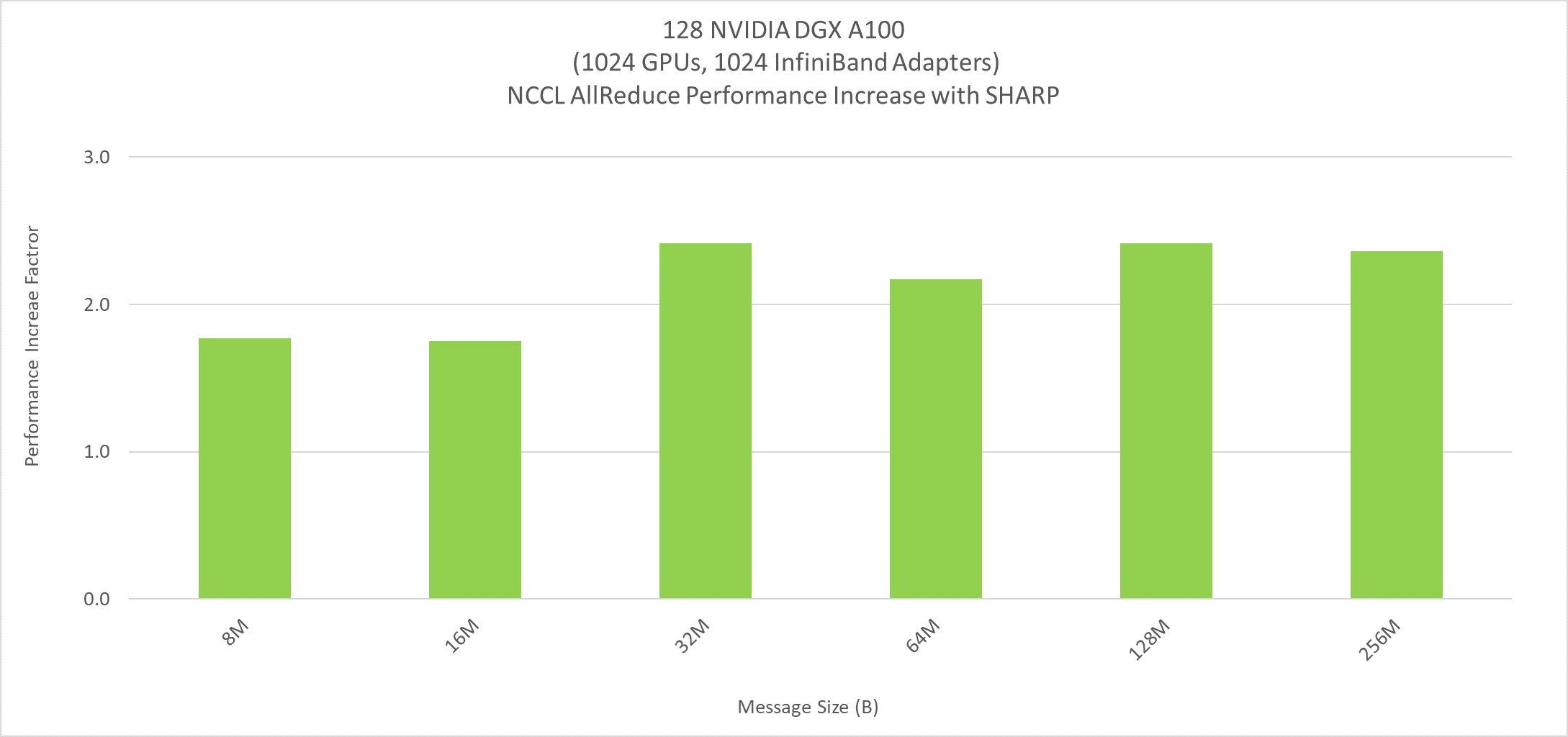
By taking advantage of GPUDirect RDMA with SHARP’s in-network computing and exposing it through NCCL (NVIDIA Collective Communication Library), any ML/DL framework that leverages NCCL can transparently leverage SHARP. SHARP pushes significant performance gains of up to 2.5X when scaling across the spectrum of large message sizes with the latest DGX A100 systems.
Summary
Today’s modern-day machine learning data center requires complex computations and fast and efficient data delivery. NVIDIA Mellanox InfiniBand networking provides smart offloads such as RDMA, GPUDirect®, and SHARP while bolstering the high bandwidth and ultra-low latency of HDR 200Gb/s, delivering the highest performance to enable the most efficient machine learning deployments at any scale. In a future article, we will cover more – including Adaptive Routing, Congestion Control, self-healing capabilities (SHIELD) and more that accelerate performance, improve resiliency and increase scalability for machine learning workloads.
To learn more about NVIDIA Mellanox SHARP and In-Network Computing, visit:
NVIDIA Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™
NVIDIA Mellanox OFED GPUDirect RDMA
NVIDIA Mellanox Quantum™ HDR 200Gb/s InfiniBand Smart Switches
NVIDIA Mellanox ConnectX®-6 Single/Dual-Port Adapter HDR 200Gb/s InfiniBand Adapter























































