 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Energy researchers have been reaching for the stars for decades in their attempt to artificially recreate a stable fusion energy reactor. If successful, such a reactor would revolutionize the world’s energy supply overnight, providing low-radioactivity, zero-carbon, high-yield power – but to date, it has proved extraordinarily challenging to stabilize. Now, scientists are leveraging supercomputing power from two national labs to help fine-tune elements of fusion reactor designs for test runs.
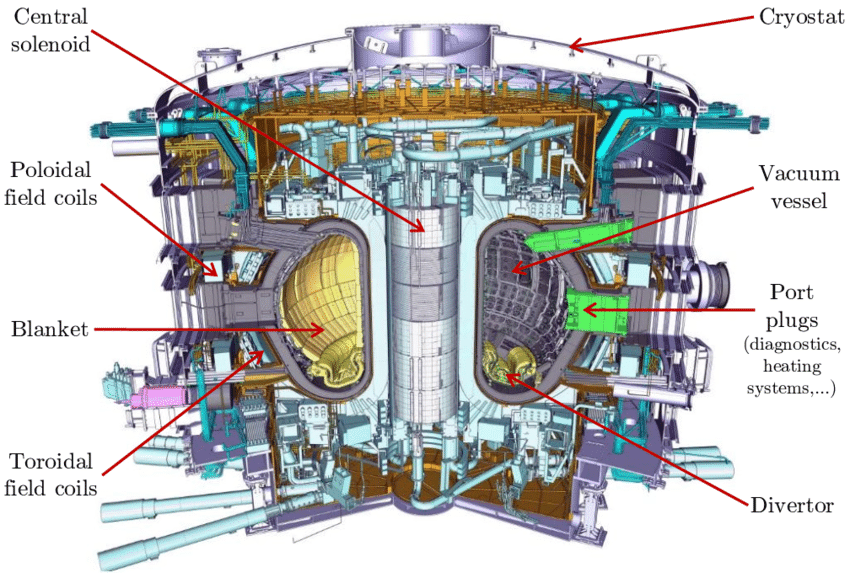
In experimental fusion reactors, magnetic, donut-shaped devices called “tokamaks” are used to keep the plasma contained: in a sort of high-stakes game of Operation, if the plasma touches the sides of the reactor, the reaction falters and the reactor itself could be severely damaged. Meanwhile, a divertor funnels excess heat from the vacuum.
In France, scientists are building the world’s largest fusion reactor: a 500-megawatt experiment called ITER that is scheduled to begin trial operation in 2025. The researchers here were interested in estimating ITER’s heat-load width: that is, the area along the divertor that can withstand extraordinarily hot particles repeatedly bombarding it.
“In building any fusion reactor in the future, predicting the heat-load width is going to be critical to ensuring the divertor material maintains its integrity when faced with this exhaust heat,” explained Choong-Seock Chang, head of the SciDAC Center for Edge Physics Simulation at the Princeton Physics Plasma Laboratory and lead author of the paper, in an interview with Rachel McDowell. “When the divertor material loses its integrity, the sputtered metallic particles contaminate the plasma and stop the burn or even cause sudden instability.”
In 2017, the team had run simulations of ITER’s heat-load width on Oak Ridge’s 17.6-petaflops Titan supercomputer. The results of the work were startling: they projected that ITER’s design would have a heat-load width over six times wider than expected.
But how could ITER’s requirements differ that much from current designs?

To explain the discrepancy, the researchers used a supervised machine learning program called Eureqa, feeding it data from previous tokamak experiments and data from prior simulations. Eureqa was supercharged by two major systems: Summit at Oak Ridge National Laboratory (ORNL), weighing in at 148.6 Linpack petaflops, and Argonne National Laboratory’s Theta, weighing in at 6.9 Linpack petaflops.
The team tasked the supercomputer-charged Eureqa with identifying the hidden variable that differentiated ITER from other experimental designs. Chang suspected that the answer might be related to the radius of the gyromotions that surrounded the plasma.
The supercomputing performed on Summit simulated more than two trillion particles and a thousand time steps per run, with each run generating 200 PB of data. When the dust settled, Chang’s suspicion was validated: the hidden variable was equal to the radius of the gyromotions divided by the size of the machine.
“If this formula is validated experimentally, this will be huge for the fusion community and for ensuring that ITER’s divertor can accommodate the heat exhaust from the plasma without too much complication,” Chang said.
While Summit and Theta did the job this time, the researchers are already looking at head to exascale machines like Frontier and Aurora, which they hope will allow them to incorporate more complex physics in their fusion reactor simulations.
This article relies on reporting from ORNL science writer Rachel McDowell.
























































