 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In the article “Super-Connecting the Supercomputers” published on June 10, 2019 in HPCwire, we discussed the different interconnect pillars, namely the connectivity pillar, the network pillar and the communication pillar. The ‘connectivity pillar’ refers to the elements around the interconnect infrastructure, such as network topologies. The ‘network pillar’ refers to the network transport and routing for example. And the ‘communication pillar’ refers to co-design elements related to communication frameworks, such as MPI, SHMEM/PGAS and more. This article focuses on the first pillar, and in particular, on the network topologies.
It may be one of the great secrets, that supercomputing innovations actually begin in the structure of the supercomputer; that is, in the way we connect the compute elements together. There are many network topology options, and InfiniBand, as it is specified and designed as the ultimate software-defined network, can support any thinkable option.
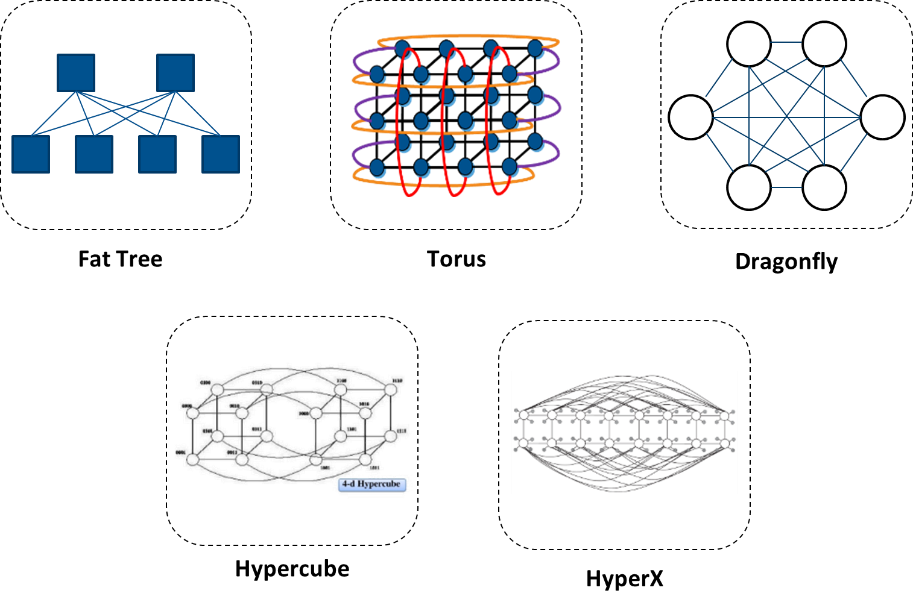
Fat-Tree (folded CLOS) is one of the most widely used topologies. It is a good option for a variety of applications as it provides low latency and enables a variety of throughput options – from non-blocking connectivity to oversubscriptions. This topology type maximizes data throughput for a variety of traffic patterns; however, it is relatively costly at large scale due to the large number of switches and links it requires. Torus topologies directly interconnect a host to several of its neighbors in a k-dimensional lattice. Tori topologies are inexpensive but provide low network throughput for adversary traffic patterns. A torus is a great topology for stencil applications, such as lattice QCD applications, but due to its blocking nature and higher latency, it is not a preferred option for supercomputers that need to support a variety of applications. Examples of other options used today or being developed for future use are Hypercube and HyperX.
The Dragonfly topology was introduced by Kim John et al. and is described in the paper entitled “Technology-driven, highly-scalable dragonfly topology.” Dragonfly provides good performance for a variety of applications (or communication patterns), like Fat-Tree; specifically, it reduces network costs compared to other topologies, by reducing the number of long links.
As seen in Figure 2, Dragonfly is based on groups of connected compute elements, where all the groups are connected in a full graph. One can create any inner-group structure, such as a full graph (Dragonfly), a generalized hypercube (GHC), or a Fat-Tree, as seen in Figure 3.


The full graph option has been used in the traditional Dragonfly topology deployed with proprietary networks over the years. The Fat-Tree option is being used by the new innovative Dragonfly+ (DF+) topology, supported by InfiniBand. Compared to the traditional Dragonfly, Dragonfly+ is more scalable since it allows connecting larger number of hosts to the network (when comparing the same switch radix), it provides better-known worst-case throughput for the same number of global inter-group links, and it enables better switch buffer utilization.
Multiple papers such as “Performance implications of remote-only load balancing under adversarial traffic in Dragonflies,” by Bogdan Prisacari, German Rodriguez, Marina Garcia, Cyriel Minkenberg (IBM Research – Zurich), and Enrique Vallejo, Ramon Beivide (University of Cantabria, Spain); or “Modeling UGAL on the Dragonfly Topology,” by Scott Pakin, Michael Lang (Los Alamos National Laboratory) and Atiqul Mollah, Peyman Faizian, Shafayat Rahman, Xin Yuan (Florida State University), indicated several of the traditional Dragonfly performance limitations, such as performance degradation of adversarial traffic, and how network bandwidth can be negatively impacted when using higher switch radix.
On the other hand, the innovative Dragonfly+ supports multiple routes from ingress switch to egress switch, and, therefore, delivers the highest data throughput (without any dependency on the switch radix) due to the Fat Tree topology within the group. This delivers a superior option over the traditional Dragonfly topology for large-scale supercomputing platforms.
The University of Toronto was the first to deploy a large-scale InfiniBand Dragonfly+ supercomputer, which has been in production for nearly 1.5 years now. The Niagara supercomputer appearing in Figure 4, is Canada’s most powerful research supercomputer.

Another advantage of Dragonfly+ is the ability to scale the cluster overtime without re-cabling any of the long cables, allowing the addition of new groups, whether compute or storage. This is an advantage which neither the Fat-Tree nor the traditional Dragonfly topologies support, that provides great benefit for multi-phase supercomputers, and supports growing computer or storage demands over time.
The advantages of Dragonfly+ makes it the preferred topology for the new generation of large-scale supercomputing. For example, CSC, the Finnish IT Center for Science, a national HPC center providing supercomputing and networking services for Finnish academia, research institutes, the public sector and industry, have selected the Dragonfly+ InfiniBand topology for its next-generation supercomputer. We expect to hear more announcements of new large-scale supercomputers around the world adopting the innovative Dragonfly+ topology. For more information, contact [email protected].























































