 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In high performance computing, the time-honored concept of creating tailored workflows to address complex requirements is nothing new. However, with the advent of new tools to analyze and process data—not to mention store, sort and manage it—traditional ways of thinking about HPC workflows are falling by the wayside in favor of new approaches that might help balance, stabilize and shatter siloed environments.
Moving beyond HPC specifically, there are certainly plenty of options for managing large-scale, diverse workflows that are designed specifically for cloud environments, and increasingly, for “big data” workflows that require orchestration between custom and commercial analytics stacks, involving hops from private or public clouds, into Hadoop and over to other analytics engines. The issue is, while there are dedicated tools for addressing workflow demands of HPC environments specifically (GridEngine, Platform, Adaptive, etc.) , or cloud environments in particular (OpenStack, etc.), some, including Adaptive Computing, argue that there are no tools that tackle HPC, cloud and the new range of big data opportunities all together—and in a way that’s primed for the custom workflow models that are so often found in some of the most complex enterprise and research datacenters.
In their experience with large organizations including NOAA, the Department of Defense and others, Adaptive Computing has had the opportunity to look under the hoods of some complicated engines for doing everything from oil exploration to addressing national security concerns. These users—and around 60% of those they recently surveyed across the public and private sector (beyond HPC exclusively) tended to have custom, homegrown workflows, which often leads to a host of problems, including a lack of flexibility to adopt new tools, time consumption spent on manually handling the complexity, and of course, overall inefficiency across the datacenter.
That 60% is a striking figure when one considers that the advent of new tools being considered to address the growing bevy of “big data” problems means more custom scripting and management of an already top-heavy stack. According to Adaptive Computing’s Jill King, this means the addition of more silos, which is exactly the opposite of what’s needed for mission-critical environments. Adaptive’s answer to this complexity is called Big Workflow, which for now means addressing these homegrown environments with a different type of glue than has been used to bind many of the HPC centers they’ve worked with over the last ten years with Moab.
King says that for many datacenter environments across the HPC and big data spectrum, the logjam happens at the important processing stage for complex data. This is currently very manual, time-consuming and laden with dependencies and, according to conversations they’ve had across multiple organizations, they’re finding a lot of “both over and under-utilized silos with long, complicated cues that simply aren’t efficient. “There’s a great need to unify, optimize and guarantee these environments,” King said.
Adaptive Computing senior architect, Daniel Hardman offered detail on Big Workflow, which is both an approach that requires custom tuning for homegrown environments via dedicated work with customer needs—as well as offering some new hooks for big data analytics tooling.
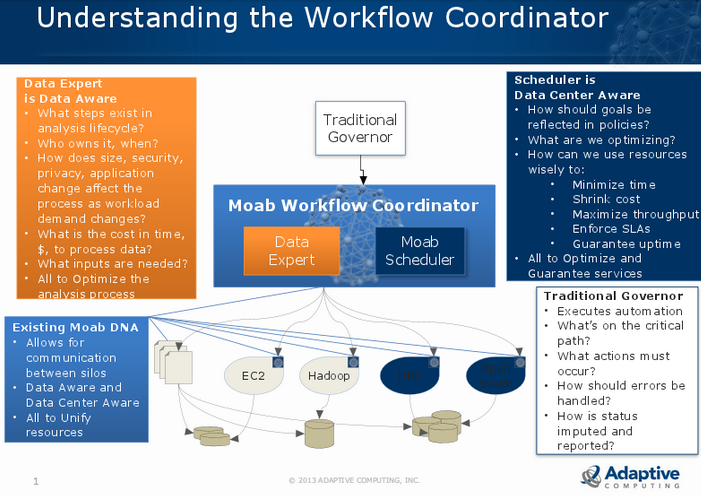
As you can see below, there are several separate silos, all governed at the top by what’s very often either a sophisticated homegrown or off-the-shelf system. Generally, says Hardman, there are not efficient ways of connecting the top level with the many silos below—and further, that top level framework can be connected across many parts of the datacenter and spectrum of needs; for example, that same level might be governing general business operations, a Hadoop cluster, an interface to a cloud pulling data off storage, and an HPC environment on top of all of that. It’s quite possible to do all of this—but it’s hardly efficient or manageable and leads to inflexibility given the processes that need to be worked in manually for custom workflows when new hooks are needed or something changes.

“There a big need for an engine that’s capable of implementing a policy-based engine across these silos,” said Hardman. “We already sell Moab cloud suite, and a comparable product in HPC, and offer an integration with the Intel Hadoop side, and although we’ve not done a lot on public cloud it’s also possible. What’s needed then is something that makes it so a user’s custom glue can tap into some efficiency and automation–a new kind of coordination so that our Big Workflow coordinator can contact these silos and make things happen across those many silo boundaries.”
The goal of Big Workflow (the coordinator is not a product as much as an approach rooted in some new hooks they’ve provided to big data sources via the Intel Hadoop distro and more) is to provide all the logic in hard-coded scripts, which Hardman says can eliminate a lot of the duct tape with management across these silos. They’re still there, but the distinction between them is a lot less painful.
“Most people in IT think about equilibrium—keep things humming-if things get broken, they get fixed. The problem is that big data is not friendly to that; it has an interesting relationship to storage in that it may not be convenient to think about those silo boundaries anymore. For example, I might have the same dataset, which begins its life in a public cloud, then I need to process and massage it in Hadoop, then perform some HPC computation on it after that, but that data may have all sorts of issues (privacy, regulatory, etc) I can’t just move it around or pretend that it’s local when it’s not. It has to be managed with policies that understand data movement, staging, management and more. Big data makes this Big Workflow coordination mandatory.”
For those familiar with Adaptive or using it already, there is the addition of the “data expert” concept, which is the smart part of the engine that has to be able to understand all about the data (lifecycle, forms through that lifecycle and its movement, size, who owns it, where can it be copied or not). This is coupled with some of the new automation for custom workflows found in the coordinator. As King explained, “we’re integrating with these custom workflows for now, then we’ll branch out and make these standards but with so many people having custom workflows, we need to be able to provide something flexible.” In other words, Adaptive is using lessons learned with customers like Digital Globe (see a detailed writeup of how this works in action over at EnterpriseTech) to propel their work for custom environments and implement those lessons as standards to help broaden their APIs and reach into more areas, including tools like Tivoli, for instance.
This approach should resonate for folks in HPC and enterprise circles, according to IDC. “Our 2013 study revealed that a surprising two thirds of HPC sites are now performing big data analysis as part of their HPC workloads, as well as an uptick in combined uses of cloud computing and supercomputing,” said Chirag Dekate, Ph.D., research manager, High-Performance Systems at IDC. “As there is no shortage of big data to analyze and no sign of it slowing down, combined uses of cloud and HPC will occur with greater frequency, creating market opportunities for solutions such as Adaptive’s Big Workflow.”


























































