 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Lustre is a popular open source parallel file system with many years of development behind it. People trying to roll their own HPC scratch storage with Lustre may find a number of inherent problems. If there isn’t in-house Lustre expertise to deploy and keep it optimally running, the work may need to be outsourced. But the total cost of ownership most likely goes up, which is counter to why companies and universities roll their own in the first place. Lustre is just one part of the HPC storage software stack that needs to be compatible and tuned for performance; the stack also includes a patched Linux kernel, firmware, and drivers.
Paper architectures and expected performance for Lustre-based storage are theoretical, until the software and hardware are working together and rigorously tested. Otherwise the time spent diagnosing incompatibilities or performance mismatched components could be significant. There are many potential points of contention or bottlenecks in an HPC solution. It’s not just the choices for the hardware—servers, controllers, network fabric, and disks—but also how well the software/firmware executes on the hardware. Be wary of the “kit” approach that requires assembly and considerable knowhow.
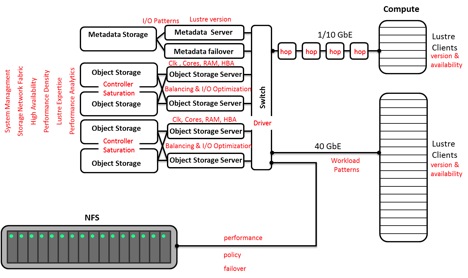
Figure 1: RYO Lustre File System with Potential Hotspots Highlighted
With the Lustre kit approach, two metadata servers (MDS) would likely be purchased, where one is active and the other is for failover. One or more pairs of active object storage servers (OSS) would be in the bill of materials, depending on the performance required. A small storage array is necessary for the metadata (MDT) and a pair of large storage arrays with controllers (RBODs for object storage) matching up with each pair of OSSes (see Figure 1). Note the cross coupling for High Availability (HA). Now it gets a bit more challenging. How many drives are needed to saturate the controllers to get the highest throughput? It’s likely in the range of 60-120 drives. If a storage array with a fast controller is purchased (e.g. NetApp E series with a Soyuz controller) it may be necessary to put a JBOD array behind each RBOD array to saturate the controllers or be left with a slow Lustre file system. If the controllers are saturated and more capacity is required, just stack JBODs behind the RBODs.
The network fabric used to connect up the aforementioned servers and storage can have a profound effect on performance. If 40 Gbps Ethernet (40 GbE) is used, up to 40% of the system throughput could be lost compared to 56 Gbps Ethernet or Infiniband. Bonding the 40 GbE ports may sound like a good idea, but there may be no real gains in throughput. Are the connections between the OSSes and object storage 6 Gbps or 12 Gbps SAS? Depending on the architecture and components selected, 12 Gbps SAS may be overkill. With some guidance from the hardware vendors, the right hardware choices can be made. The software side is a bit trickier.
Downloading open source Luster or purchasing Intel’s version (IEEL) only provides part of the software stack required. A patched Linux kernel (readily available) and a strategy to monitor the hardware are required. The various hardware components have their own API and/or supplied command line utilities, but there aren’t any sensors provided with the Lustre distribution to call them and collect metrics. The sensors would report through a scalable monitoring framework to a management application, but they are missing in the case of open source Lustre and sorely lacking in third party versions. It’s a real headache to diagnose, fix, and tune Lustre-based storage without comprehensive hardware monitoring and management software to analyze the metrics collected, correlate events, and create reports. Support also suffers without hardware monitoring to raise alerts on failures or pending failures.
Tuning Lustre, the hardware, and clients can be perplexing. There is literature on tuning Lustre, but be careful as turning one knob may have a positive effect on one area of the system and a negative effect on another. For the drivers and firmware, the hardware vendor can help, but don’t be surprised if it takes multiple calls and remote access to the system. Outside the Lustre-based storage, the clients also have their own parameters, which can affect performance. Be prepared to become knowledgeable, outsource the required expertise, or buy a service contract to get the end-to-end solution tuned up.
An alternative is the HPC storage appliance model. Like the name indicates, the appliance rolls-in, plugs-in, and runs like enterprise storage with little assembly required. It is rack based and will need to be connected to the network and clients given access. The number of racks depends on the performance and capacity required. The highest performing appliance with 4 TB drives that I have seen has a total capacity of 2 PB (raw) running at 20 GB/s in a single 42U rack and scaling linearly in performance and capacity for each additional rack. 6 TB and 8 TB drives are on the near horizon, so appliance performance density should double over the next year.
Appliances are highly available, meaning if there is a component failure, the system keeps on running and raises an alert. There is no loss of data or downtime. With an appliance, the software stack is certified and optimized on the target hardware before it gets to the customer site. The hardware components are carefully selected to get the most performance density. The software stack includes system management software to monitor data, performance, and reliability. A complete working system is delivered, not a kit to be assembled. This allows the system to be up and running acceptance tests in hours. Purpose built sensors and near real-time monitoring (e.g. every 5s) are included. The software will raise an alert if there is likely to be a component problem (pre-emptive alert) or failure and indicate what needs to be fixed. If the system isn’t running at peak performance for a particular workload, there are built-in performance analytics to help spot the bottlenecks, such as overloaded servers, poor data striping, client access patterns, or unbalanced application codes.
The monitoring software metrics include performance, network, server, storage (controller, drives, and utilization), temperature, online/offline, physical connections, and power. The amount of performance metrics collected per year are substantial, but require less than 1% of the raw storage. The sensors and monitoring software are on their own private network as to not interfere with the application codes that are running and this separation provides a layer of reliability. The private network can be 1 GbE, until somewhere in the range of 50-75 petabytes, then 10 GbE is needed to handle the amount of traffic on the management network. (see Table 1).
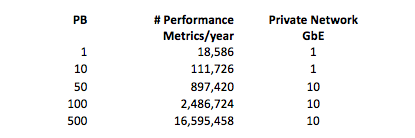
Table 1: Performance Metric Collected and Private Network Requirements
HPC vendors and customers usually focus on the combination of cost, performance, and capacity. Lifecycle considerations should be just as important to a purchasing decision. Selection on broader considerations lowers total cost of ownership, keep scratch storage running fast for different types of workloads, and make the system highly available 24x7x365. The cost of downtime can be considerable.
Considerations should include:
- System manufactured before delivery
- Installation in hours
- Hardware components matched—no built-in bottlenecks
- Certified software stack on target hardware
- System-level high availability—redundancy and failover
- Purpose built sensors
- Near real-time hardware monitoring
- Tools to tune workload performance
- Diagnostics w/ correlation engine
- Performance analytics
- Turnkey appliance—no Lustre expertise required
- One-stop system-wide customer support
- Phone-home support
- Scalable management architecture
- Fast Lustre escalation path
If the purchasing decision is optimized along these vectors, then the chances of long term success go up and TCO goes down. Below (Figure 2) is an example of a fully vetted storage appliance in an HPC environment. Compare this to the system in Figure 1.
In summary, the appliance model has a number of advantages to consider before rolling your own Lustre-based storage.
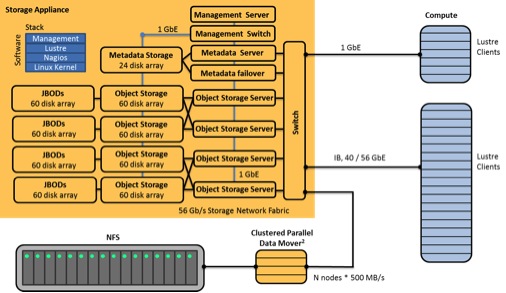
Figure 2: Storage Appliance Model
About Alan Swahn, Vice President of Marketing, Terascala
Prior to joining Terascala, Alan was vice president of marketing and business development at ManageSoft that was acquired by Flexera Software in FY2010. He also co-founded LightSpeed Semiconductor, where he was instrumental in defining a new market category for single mask programmable ASICs. Alan was part of two startups that had successful IPOs—Viewlogic Systems and Daisy Systems. Swahn holds a Bachelor of Science in Electrical Engineering with High Honors from Rochester Institute of Technology and an AEET with Highest Distinction from Penn State University. Alan also holds two patents (8,838,736, 8,015,259). Read more about Alan on LinkedIn.
























































