 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
ARM and Fujitsu today announced a scalable vector extension (SVE) to the ARMv8-A architecture intended to enhance ARM capabilities in HPC workloads. Fujitsu is the lead silicon partner in the effort (so far) and will use ARM with SVE technology in its post K computer, Japan’s next flagship supercomputer planned for the 2020 timeframe. This is an important incremental step for ARM, which seeks to push more aggressively into mainstream and HPC server markets.
Fujitsu first announced plans to adopt ARM for the post K machine – a switch from SPARC processor technology used in the K computer – at ISC2016 and said at the time that it would reveal more at Hot Chips about the ARM development effort needed. Bull Atos is also developing an ARM-based supercomputer.
The SVE is focused on addressing “next generation high performance computing challenges and by that we mean workloads typically found in scientific computing environment where they are very parallelizable,” said Ian Smythe, director of marketing programs, ARM Compute Products Group, in a pre-briefing. SVE is scalable from 128-bits to 2048-bits in 128-bit increments and, among other things, should enhance ARM’s ability to exploit fine grain parallelism.
 Nigel Stephens, lead ISA architect and ARM Fellow, provided more technical detail in his blog (Technology Update: The Scalable Vector Extension (SVE) for the ARMv8-A Architecture, link below) coinciding with his Hot Chips presentation. It’s worth reading for a fast but substantial summary.
Nigel Stephens, lead ISA architect and ARM Fellow, provided more technical detail in his blog (Technology Update: The Scalable Vector Extension (SVE) for the ARMv8-A Architecture, link below) coinciding with his Hot Chips presentation. It’s worth reading for a fast but substantial summary.
“Rather than specifying a specific vector length, SVE allows CPU designers to choose the most appropriate vector length for their application and market, from 128 bits up to 2048 bits per vector register,” wrote Stephens. “SVE also supports a vector-length agnostic (VLA) programming model that can adapt to the available vector length. Adoption of the VLA paradigm allows you to compile or hand-code your program for SVE once, and then run it at different implementation performance points, while avoiding the need to recompile or rewrite it when longer vectors appear in the future. This reduces deployment costs over the lifetime of the architecture; a program just works and executes wider and faster.
“Scientific workloads, mentioned earlier, have traditionally been carefully written to exploit as much data-level parallelism as possible with careful use of OpenMP pragmas and other source code annotations. It’s therefore relatively straightforward for a compiler to vectorize such code and make good use of a wider vector unit. Supercomputers are also built with the wide, high- bandwidth memory systems necessary to feed a longer vector unit,” wrote Stephens.
He notes that scientific workloads have traditionally been written to exploit as much data-level parallelism as possible with careful use of OpenMP pragmas and other source code annotations. “It’s relatively straightforward for a compiler to vectorize such code and make good use of a wider vector unit. Supercomputers are also built with the wide, high- bandwidth memory systems necessary to feed a longer vector unit.”
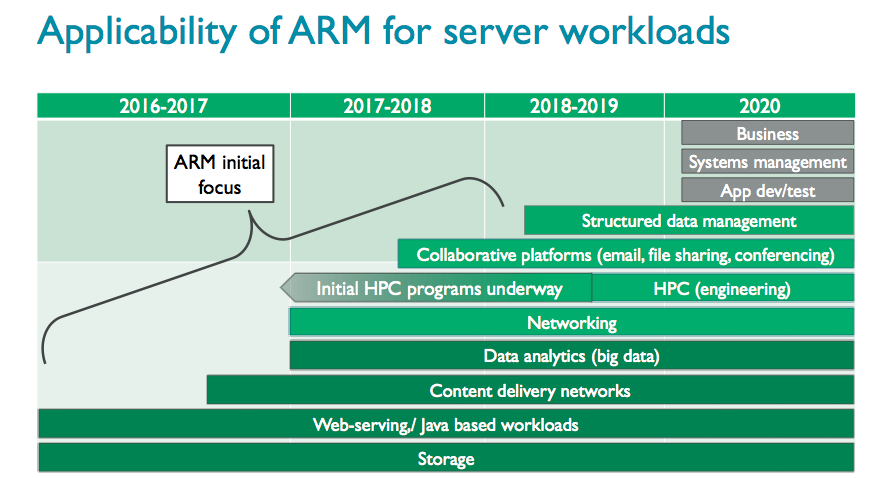 While HPC is a natural fit for SVE’s longer vectors, said Stephens, it also offers an opportunity to improve vectorizing compilers that will be of general benefit over the longer term as other systems scale to support increased data level parallelism.
While HPC is a natural fit for SVE’s longer vectors, said Stephens, it also offers an opportunity to improve vectorizing compilers that will be of general benefit over the longer term as other systems scale to support increased data level parallelism.
Amplifying on the point, he wrote, “It is worth noting at this point that Amdahl’s Law tells us that the theoretical limit of a task’s speedup is governed by the amount of unparallelizable code. If you succeed in vectorizing 10 percent of your execution and make that code run four times faster (e.g. a 256-bit vector allows 4x64b parallel operations), then you reduce 1000 cycles down to 925 cycles and provide a limited speedup for the power and area cost of the extra gates. Even if you could vectorize 50 percent of your execution infinitely (unlikely!) you’ve still only doubled the overall performance. You need to be able to vectorize much more of your program to realize the potential gains from longer vectors.”
The ARMv7 Advanced SIMD (aka the ARM NEON) is now about 12 years old and was originally intended to accelerate media processing tasks on the main processor. With the move to AArch64, NEON gained full IEEE double-precision float, 64-bit integer operations, and grew the register file to thirty-two 128-bit vector registers. These changes, says Stephens, made NEON a better compiler target for general-purpose compute. SVE is a complementary extension that does not replace NEON, and was developed specifically for vectorization of HPC scientific workloads, he says.
Snapshot of new SVE features compared to NEON:
- Scalable vector length (VL)
- VL agnostic (VLA) programming
- Gather-load & Scatter-store
- Per-lane predication
- Predicate-driven loop control and management
- Vector partitioning and SW managed speculation
- Extended integer and floating- point horizontal reductions
- Scalarized intra-vector sub-loops
Smythe emphasized, “If you compile the code for SVE it will run on any implementation of SVE regardless of the width, whether 128 or 1024 or 2048, and the hardware implementation, that code will run on ARM architecture as a binary. That’s important and gives us scalability and compatibility into the future for the compilers and the code that HPC guys are writing.”
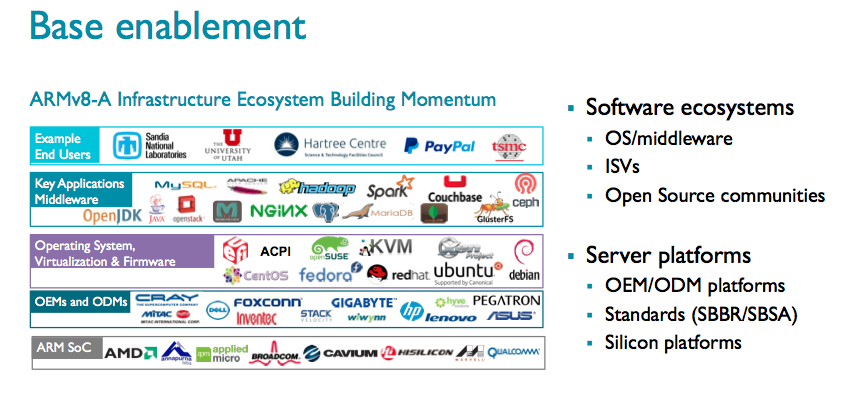 ARM has been steadily working to expand its ecosystem (shown here) with hopes of capturing a chunk of the broader x86 market. It has notable wins in many market segments, although the market traction has been tougher to gauge, and it is only in the past couple of years that server chips started to become available. Many design wins have been niche oriented; one example is an HPE ARM-based storage server (StoreVirtual 3200) announced earlier this month. ARM, of course, is a juggernaut in mobile computing.
ARM has been steadily working to expand its ecosystem (shown here) with hopes of capturing a chunk of the broader x86 market. It has notable wins in many market segments, although the market traction has been tougher to gauge, and it is only in the past couple of years that server chips started to become available. Many design wins have been niche oriented; one example is an HPE ARM-based storage server (StoreVirtual 3200) announced earlier this month. ARM, of course, is a juggernaut in mobile computing.
Prior to the Hot Chips conference, with its distinctly technical focus, ARM was pre-briefing some of the HPC community about SVE and using the opportunity to reinforce its mission of growth, its success in ecosystem building, and to bask in some of the glory of the post K computer win. Given the recent acquisition of ARM by SoftBank, it will be interesting to watch how the marketing and technical activities change, if at all.
Lakshmi Mandyam, senior marketing director, ARM Server Programs, said, “We’ve been focusing on enabling some base market segments to establish some beachheads and enable our partners to get adoption in those key areas. Also we have also been using key end users to drive our approach in terms of ecosystem enablement because clearly we are catching up with x86 in terms of software enablement.”
“The move to open source and consuming applications and workloads through [as-a-service models] is really driving a lot of disruption of the industry. It also presents an opportunity because a lot of those platforms are based on open source and Linux and or intermediate middleware and so the dependency on the legacy (x86) software and architectures is gone. That presents an opportunity to ARM.”
It’s also important, she said, to recognize that many modern workloads, even in HPC, are moving towards the scale out model as opposed to a purely scale up. Many of those applications are driven by IO and memory performance. “This where the ARM partnership can shine because we are able to deliver heterogeneous computing quite easily and we’re able to deliver optimized algorithm processing quite easily. If you look at a lot of these applications, it’s not about spec and benchmark performance; it’s about what can you deliver in my application.”
“When you think about Fujitsu, as they talked about the post K computer, a lot of the folks are looking for this really tuned performance, to take a codesign approach where they are looking at the entire problem, and to deliver an application and service for a given problem. This is where their ability to tune platforms down to the silicon level pays big dividends,” she said.
Here’s a link to Nigel Stephens’ blog on the ARM SVE anouncment: Technology Update: The Scalable Vector Extension (SVE) for the ARMv8-A Architecture
























































