 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Gordon Moore’s 1965 article on the economics driving the increase of semiconductor functionality has turned out to be wildly prophetic in terms of the effect on transistor scaling. Nearly 40 years later, in 2004, Intel was building microprocessors on the 90 nanometer process with 150 million transistors in a single chip. Today, we’re putting as many as 1.35 billion transistors in a processor with features as small as 14 nm. That’s approaching 10x the number of transistors with 6x finer features in only eleven years of technology development. And that’s not even the highest density part Intel makes; that award, at the time of this writing, goes to the 18-core Intel Xeon processor E7-8890 v3 with 5.5 billion transistors built on the 22 nm process, all packaged into 52 mm x 45 mm. Even more impressive is the fact that this is only counting transistors—there are many other components that occupy that 52 mm x 45 mm die. Moore’s observation continues to stand the test of time after 50 years of technology advancement.
Seeing Moore’s Law through an Engineer’s Eyes
Many who quote Moore’s Law—often interpreted as ~2X more transistors every technology generation—may not fully appreciate what Gordon Moore’s observation means to those who actually design the transistors that live up to it. Outside technology development, the challenges that shrinking transistors present are not seen, yet, they are enormous. And it’s not just the reduction in size. To deliver on Moore’s Law, engineers drive increasing complexity in the transistor design itself, including changing the internal structures, materials, and even the overall device architecture. These changes are necessary to create devices that can continue to be high performing and power efficient at smaller and smaller dimensions.
Until about ten years ago, transistor engineering was conceptually simpler: scale down essentially every aspect of the previous generation transistor, whose design features could all be represented in a simple 2D diagram (see below). Numerical simulation of the transistor, an important part of process development, could be readily achieved by breaking down the device into small silicon blocks and applying classical semiconductor physics. The computation could be run on a desk side workstation, which would crunch through the equations in minutes to hours. But as feature sizes have scaled down, we have had to use novel architectures, such as 3D transistors, and new materials with nanoscale dimensions to continue delivering device performance. These add a third dimension to the transistor representation and require more complicated physics, greatly increasing the complexity of the simulation.
See the figures below comparing the complexity of 2D planar transistors ten years ago (left) to 3D architectures today (right).
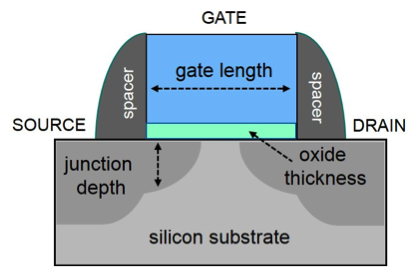

Challenges of Dimension, Architecture, and Materials
Looking far into the future, we’re examining and simulating beyond just the next few generations of transistors. We’re looking at the technologies we need to continue to develop components at these dimensions with the performance and reliability that our customers have come to expect. At these smaller and smaller dimensions, physical effects we used to approximate or overlook can no longer be ignored. For example, the following figure shows a futuristic device, a transistor made out of a silicon “wire” surrounded by a metal gate, with the red and green spheres representing individual silicon and metal atoms. At this dimension, a single atom of an element other than silicon within the wire (represented by the yellow dot in the corner of the cross section) can impact transistor behavior. As visualized after numerical simulation, this single stray atom distorts the uniformity of the electronic current traveling through the cross-section, disrupting the desired electrical behavior. Years ago, because the cross section was large, we would have ignored this effect. For devices of the future, we can’t, because its impact can be significant.
This simulation of a nanowire transistor shown below demonstrates how a single stray atom can distort electronic behavior.
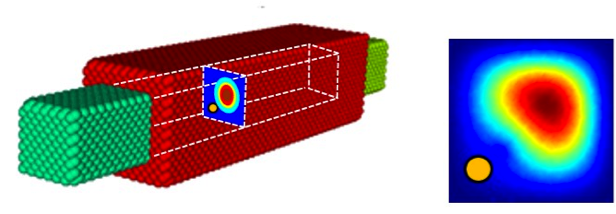
At these nanoscale dimensions, it becomes important to simulate every atom including each atom’s electronic orbitals. Classical physics is left far behind and we enter the realm of quantum physics—much more complex and computationally demanding to simulate.
These kinds of problems are not possible to run on workstations—at least in a timeframe that allows Intel to introduce innovative electronic products every year or two. For example, calculating current to voltage relationships (I-V characteristics) with at least 10 points on a curve is a central part of simulation and transistor analysis. The table below shows the amount of memory and the wall clock time to calculate a single I-V point for a range of devices using a single processor core.

At the dimensions of these simulations, the wave nature of electrons becomes important and it is necessary to solve Schrodinger’s equation. These simulations were conducted using NEMO5, a code developed at Purdue University by Professor Gerhard Klimeck’s group.
It doesn’t take long for the problem to outgrow the compute capabilities at a typical engineer’s desk—even with today’s powerful workstations. For case 3, a typical 10-point curve would take nearly 15 years to complete. Wall times of these magnitudes are not realistic for maintaining the types of development schedules any company must follow to stay competitive—and in business.
Moore’s Law and HPC
So, how do we, as process designers, keep up with the changes that drive Moore’s Law? How do we deal with shrinking technologies, novel architectures, and new materials at the center of our simulations? We turn to some of the very computers for which Moore’s Law helps provide increasing performance—enormously large High Performance Computing (HPC) clusters. The figure below maps how computational demand has grown over the course of years of technology advancements and marks the major inflection points that have shaped that demand. Today’s problems are solved by very large systems, the kind of machines that make the Top500.org list of the fastest supercomputers in the world.
To illustrate what these HPC systems mean to design times, refer back to case 3 above: using 20,000 cores, calculating 10 I-V points for case 3 can be done in about a day.
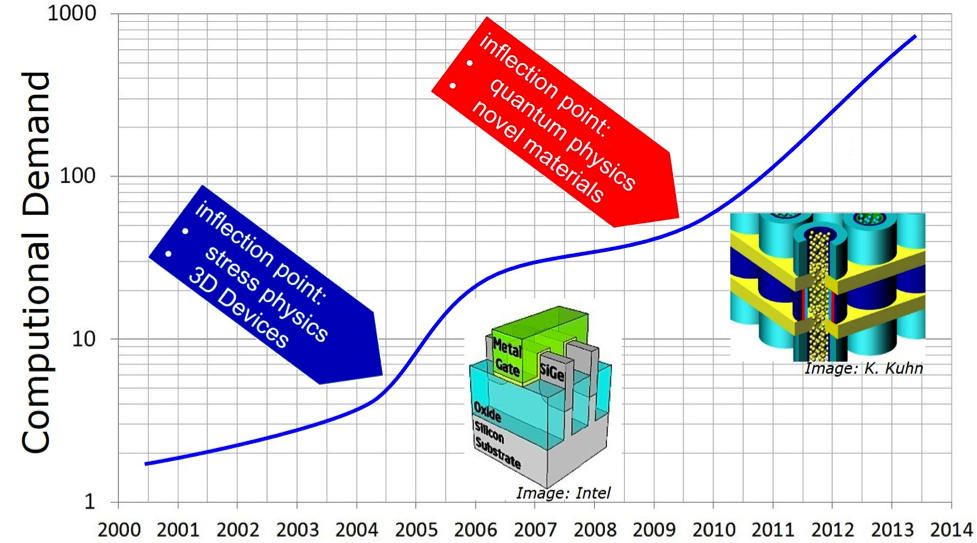
So, Moore’s Law drives an increasingly larger demand for HPC, which allows us to continue to design devices that live up to Moore’s Law, which supports the creation of more powerful HPC, so that we can carry on the expressions of Moore’s Law in smaller and more complex devices. If it weren’t for these supercomputers, living up to Moore’s Law would become impossible. It’s a symbiotic relationship expressed in silicon with a never ending cycle—at least into the foreseeable future.
Delivering HPC for Transistor Design
Technical supercomputing in electronic design and simulation is an absolute necessity for Intel to stay competitive and retain its leadership position for the products it offers. From 2004 until today, Intel’s computing capacity for chip design has increased 4,600 percent (46X), for the reasons stated above. To serve Intel’s chip design computing needs, we have approximately 130,000 servers powered by Intel Xeon processors adding up to a million cores.
When Intel’s process simulation team (aka TCAD) approached Intel’s IT department with the computational demand needed for future-generation device simulations, IT designed a solution comprised of 1,296 nodes with 2,592 Intel Xeon processors E5-2680 v3, totaling 31,104 cores and 324 TB of memory. The system, identified as SCD2P4 (named for its location, the Santa Clara D2-P4 Data Center), occupies 15 extra-tall, 60 rack units (60U) compared to industry standard 42U, and it consumes 0.6 MW of power.
There are several aspects that are unique to this supercomputer: 1) it was designed from Commodity hardware/COTS (Common Off-the Shelf) components instead of custom components, as is the case in most world-class supercomputers; 2) it utilizes blade servers rather than traditional rack servers or specialized servers, which offers 1.6X better density—15 racks vs 26 racks for the entire system; 3) components were selected based on real-world benchmarking, which showed a 31% performance difference between competing InfiniBand Architecture solutions; 4) we developed a unique multi-tier check-pointing architecture, which utilizes Intel SSDs in each server, improving the reliability of the check-pointing and restore process, and removing the need for a complicated parallel storage solution.
 In June of 2015 the SCD2P4 system ranked 81 on the Top500.org list with 833.92 TFLOPS. In November of this year it remains among the top 100 fastest machines in the world, according to the Top500.
In June of 2015 the SCD2P4 system ranked 81 on the Top500.org list with 833.92 TFLOPS. In November of this year it remains among the top 100 fastest machines in the world, according to the Top500.
Cool HPC Machines
This machine is a very large system, but not the only large cluster dedicated to transistor and circuit design. Intel has at least three other HPC systems with over 4,000 cores that have ranked among the Top500 in the last several years. The problems of design are growing ever larger because of the complexity of devices, shrinking processes, and additional capabilities added to the silicon—all driving the need for larger systems.
With large systems like SCD2P4, one of the chief problems data centers face is managing power and using that power efficiently because electricity is expensive. The cluster runs in Intel’s free-air-cooled, extremely energy efficient D2 data center in Santa Clara with a Power Usage Effectiveness (PUE) of 1.06. The average PUE for the industry is 1.80 PUE. That qualifies SCD2P4 as among the most power efficient supercomputers in operation in the world. We are able to run at such high efficiency largely because we use free-air cooling rather than total refrigeration, and we maintain temperatures in the data center between 60 and 91 degrees Fahrenheit. In 2014, out of the 8,760 hours of operation in the year, the data center required only 39 hours of refrigerated cooling while the outside temperature was over 91 degrees. All told, the Santa Clara data center saves Intel $1.9 million each year in electricity and 44 million gallons of water. Thus, not only does Intel lead in transistor design, the data centers supporting these design efforts are built and managed for optimal utilization and power efficiency.[1]
An Exciting Time for Process Design
With the capabilities of today’s HPC systems, device engineering is a lot more exciting than it was even ten years ago. We get to run incredibly interesting simulations—virtual experiments—at levels of detail we never dreamed of; we now explore new device architectures and novel materials and visualize electronic behavior and process physics with atomistic resolution.
While some naysayers in the industry have sounded the death knell for Moore’s Law—as they have since time immemorial—it is Intel’s business to continue it. It’s an unwritten law in engineering that every generation thinks their challenges are the most difficult. Although new technical challenges continue to emerge, as they have every generation since the first VLSI chips were created, the outlook for Moore’s Law remains the same as it did twenty years ago; the path for the next few generations is visible, and after that, it gets hazy until we move forward.
The HPC industry’s march to Exascale depends upon Moore’s Law. The new Intel Scalable Systems Framework (Intel SSF)—an advanced architectural approach for developing scalable, balanced and efficient HPC systems—was designed with this in mind. Plus, Intel SSF will take advantage of innovations like the Intel Omni-Path Architecture fabric and the 3D XPoint to power the supercomputers that will enable process designers to address the challenges involved with keeping Moore’s Law advancing.
Innovation, by definition, is beset with barriers. Intel’s job is to overcome these barriers by exploration and discovery. In the case of transistor design, this means the creation of new materials, device architectures, manufacturing processes, etc. To bring these advances to the consumer takes a lot of simulation before we even begin chip fabrication (see below). Without supercomputers, we wouldn’t be able to understand what it takes to continue the march of Moore’s Law, and without this understanding, we wouldn’t be able to create more powerful supercomputers. This symbiosis is at the heart of the relationship between Moore’s Law and HPC.
 As shown here, using numerical simulation and HPC, process designers can visualize novel materials and process techniques and their effects on device behavior before running actual experiments. Shown above are simulations of chemical reactions that occur during the fabrication process. The individual particles are atoms.
As shown here, using numerical simulation and HPC, process designers can visualize novel materials and process techniques and their effects on device behavior before running actual experiments. Shown above are simulations of chemical reactions that occur during the fabrication process. The individual particles are atoms.


Authors:
By Mark Stettler, Vice President, Technology and Manufacturing Group, Director of Process Technology Modeling, Intel Corporation and Shesha Krishnapura, Intel IT Chief Technology Officer and Senior Principal Engineer. [1] For more information on SCD2, read Intel Data Center Design Reaches New Heights of Efficiency (http://datacenterfrontier.com/intel-data-center-new-heights-efficiency/) and Intel CIO Building Efficient Data Center to Rival Google, Facebook Efforts (http://blogs.wsj.com/cio/2015/11/09/intel-cio-building-efficient-data-center-to-rival-google-facebook-efforts/).


























































