 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In 1994, two NASA employees connected 16 commodity workstations together using a standard Ethernet LAN and installed open-source message passing software that allowed their number-crunching scientific application to run on the whole “cluster” of machines as if it were a single entity. Their do-it-yourself, McGyver-like efforts were motivated by a frustration with the pricing, availability and maturity of then existing massively parallel processors, e.g., nCube, Thinking Machines, Convex and Cray. They named their machine Beowulf. Thomas Sterling and Donald Becker may not have known it at the time but their ungainly machine would usher in an era of commodity parallel computing that persists today and 1994 would prove to be a pivotal year in the history of high-performance computing (HPC). I believe that 2016 will be another such pivotal year. This year sees the launch of both NVIDIA’s Pascal P100 GPU, the latest in its Tesla compute line, and Knights Landing, the next manycore chip in the Intel Phi family.
NVIDIA
With its modest introduction in 2007 of the Tesla compute family of GPUs and CUDA, a compiler that made it much easier to do general programming on its products, NVIDIA introduced the HPC community to general purpose GPU computing (GPGPU). Since that time adoption has been brisk with many HPC codes ported in part or whole to GPUs to achieve better performance. When compared on a chip-to-chip basis against CPUs, GPUs have significantly better capability on both speed of calculation (FLOPS) and speed of data movement (bandwidth) (GB/s). Figure 1 tells this story.
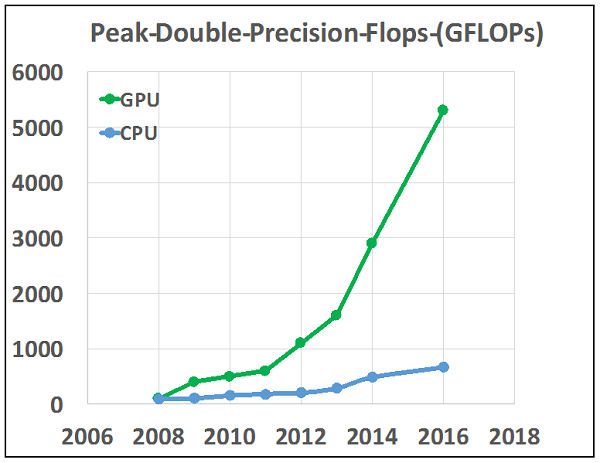
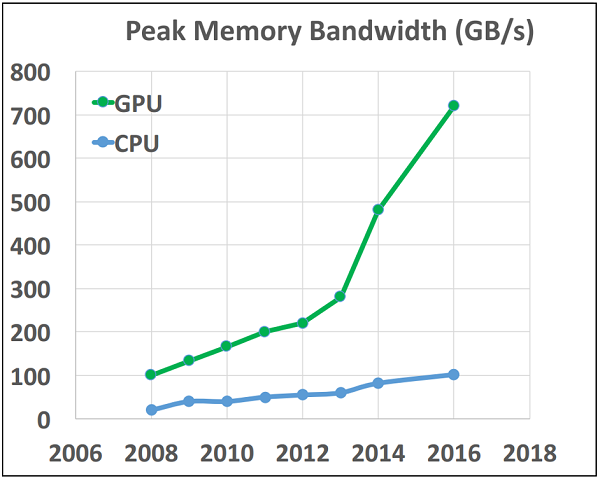
Over the last decade GPUs have made significant inroads in many HPC applications important to industry and in the past three years there has been a resurgence of interest in machine intelligence, deep learning and AI that has largely been enabled by the compact, high-performance of NVIDIA GPUs and massive training sets now available on the internet. The challenge for NVIDIA is to change the perception of GPUs from accelerators to full computing platforms. When the community sees GPUs as accelerators it chooses to use them to offload the most time consuming kernels. For complex applications this may only be 50 percent of the total runtime and consequently, limited by Amdahl’s law, they will achieve at most a factor of 2. To make broader advances in HPC with gains proportionate to improvements in hardware specifications users need to develop full complex applications for the platform. The resulting gains can be very impressive. I will use ECHELON, the high performance reservoir simulator that my company, Stone Ridge Technology (SRT), markets to the oil and gas community as an example.
ECHELON is unique in that it is a complex full featured engineering application that runs every computational kernel on GPU; and while reservoir simulation targets a very specific domain it is representative of any engineering application that requires the solution of coupled non-linear partial differential equations on a grid. In that sense it is similar to codes for computational fluid dynamics, structural mechanics, weather modeling and many others. Our experience at SRT with multiple generations of GPU technology is that we are taking full advantage of additional hardware resources provided by NVIDIA. Performance is almost directly proportional to the additional bandwidth/flops available. ECHELON, like most scientific codes, is bandwidth bound; double the bandwidth and runtimes go down by about a factor of two. Why is this exciting? It means that those linear gains we experienced pre-2004, when clock speed scaled up every two years, are once again attainable. ECHELON is back on the Moore’s law curve and any code, similarly constructed, can be as well.
Intel
Intel has not stood still and the success of GPUs in HPC has not escaped its attention. The company has presented a consistent vision of a manycore line of chips that are x86 compatible stretching back to the mid-2000s with the Larrabee project. Larrabee was to be an x86 compatible discrete graphics chip, in other words a chip to compete head-to-head with NVIDIA and ATI (now AMD) in their core business. Product delays and disappointing performance led to the cancellation of Larrabee in May 2010 and its morphing into Knights Ferry, the first of Intel’s manycore HPC chip family, Phi. Perhaps recognizing the early success of NVIDIA in HPC or as part of a strategic vision for x86 capable manycore chips, instead of competing on discrete graphics, Intel was going to compete with NVIDIA for this newly discovered accelerator market.
As the HPC incumbent, Intel had and still has significant advantages, including a huge installed customer base, x86 software compatibility and control of the host system. The Phi line followed Knights Ferry with Knights Corner in 2012 and the latest in the Phi line, released this year at ISC is Knights Landing. The challenge for Intel is to put a product on Figure 1 competitive with GPUs. Knights Landing’s specs indicate peak memory bandwidth of 490 GB/s and 3.46 teraflops peak double-precision FLOPS on the top bin part. Its success will depend largely on how easy it is to achieve that peak performance. The notion that Xeon codes will magically run much faster on the Phi family of chips with little or no modification has proven incorrect. It is a complex chip with a complex cache hierarchy and it will take both time and effort to modify codes to exploit it fully.
While GPUs have gained a strong and dedicated following over the last decade as a next generation HPC platform, many companies, fearing the investment in software development, the scope of the task and limited experience with GPUs have chosen a conservative wait and see posture. As loyal Intel customers, they have waited almost a decade to get a viable manycore computing platform, one optimized for throughput processing of threads. All the while the performance gap between GPU-based codes and their CPU-based equivalents has grown with each processor generation. The Xeon Phi family from Larrabee through Knights Corner has thus far been disappointing. It stands in stark contrast to the near military precision, consistent performance and technical excellence that Intel has exhibited in its main Xeon line since the introduction of the Core 2 architecture in 2004. Knights Landing is Intel’s third try. After almost a decade of waiting and promises, the expectations on Knights Landing are understandably high and a failure to match or exceed the performance of Pascal should trigger heated debate in the cubicles, datacenters and board rooms where HPC matters.
The Battle for HPC
Intel and NVIDIA are battling each other for the massive number crunching and data moving work that is the hallmark of HPC. It’s the kind of work that includes modeling and simulation tasks of everything from airflow over automobiles and aircraft, climate and weather modeling, seismic processing, reservoir simulation and much more. This year that battle is being played out by the matchup between Knights Landing and Pascal. An enormous amount is at stake and the HPC hardware market only scratches the surface. The real cost is in the millions of person-hours that will be invested writing and porting massive, complicated technical codes to one of these two platforms. It’s a huge investment for companies and developers and it will set the HPC course for the next decade. Will Intel’s Knights Landing begin to put the pressure on NVIDIA’s Pascal or will Pascal become Intel’s Knight’s Mare. This year will tell.
About the Author
 Dr. Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 20 years experience in the field of high performance computing. Previous positions include Technical Director at High Performance Technologies (HPTi) and Senior Physicist at ExxonMobil Corporation, where Dr. Natoli worked for 10 years in both its Corporate Research Lab in Clinton, New Jersey and the Upstream Research Center in Houston, Texas. Dr. Natoli holds Bachelor’s and Master’s degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania. Dr. Natoli has worked on a wide variety of applications including reservoir modeling and seismic data processing for the oil and gas industry, molecular dynamics, quantum chemistry, bioinformatics and financial engineering.
Dr. Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 20 years experience in the field of high performance computing. Previous positions include Technical Director at High Performance Technologies (HPTi) and Senior Physicist at ExxonMobil Corporation, where Dr. Natoli worked for 10 years in both its Corporate Research Lab in Clinton, New Jersey and the Upstream Research Center in Houston, Texas. Dr. Natoli holds Bachelor’s and Master’s degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania. Dr. Natoli has worked on a wide variety of applications including reservoir modeling and seismic data processing for the oil and gas industry, molecular dynamics, quantum chemistry, bioinformatics and financial engineering.
























































