 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
“Imagine if you’ve got a Titan-size computer (27 PFlops) and it has main memory that’s partially non-volatile memory and you could just leave your data in that memory between executions then just come back and start computing on that data as it sits in memory,” says Jeffrey Vetter, group leader of the Future Technologies Group at Oak Ridge National Labs.
“There are challenges with that in terms of how the systems are allocated, how the systems are organized and scheduled, and so those are the kind of things we’re trying to see before all the users and other folks see them and trying to come up with some solutions.” That in brief is the mission FTG is charged with by its main sponsors, the Department of Energy (DOE) and NSF, as well as collaboration with industry.

Formed roughly 13 years ago as a team focused on emerging technologies for HPC and led by Vetter who joined ORNL from Lawrence Livermore National Lab, FTG results have proven influential. Perhaps most notable is work on GPU architectures in the 2008 timeframe.
“We took those results and shared them with our sponsors (DOE and NSF) and they impacted the timelines and architectures for the systems we have now. We managed to become an XSEDE site running the largest GPU system in NSF and at Oak Ridge our results were very instrumental in Titan becoming a GPU-based system,” says Vetter.
“The idea [behind FTG] is that you’ve got these technologies and there’s a lot of assessment that has to happen in terms of mission applications. It’s not just this new technology is great for one application; it is how do we deploy it widely to our users. How do we make the programming model productive and the tool ecosystem productive around these [architectures] and try to find example of applications that perform well on these architectures.”
GPU-based systems, he notes, have become very effective for molecular dynamics, quantum chemistry dynamics, CFD, and neutron transport. FTG work has played a role helping to bring that about. The constant thread running through FTG projects is work to develop new insight and computational tools that allow emerging technologies to be put to useful work on science or DOE mission applications. The group’s work product, says Vetter, typically includes papers, software, and scientific advance – the perfect “trifecta” when everything works.
The influential GPU work is a good example. “We have several papers on our GPU work with applications,” says Vetter. “Two of the primary efforts [in the 2008 timeframe influencing system direction and timing] were:”
- DCA++: a quantum materials application: Alvarez, M. Summers et al., “New algorithm to enable 400+ TFlop/s sustained performance in simulations of disorder effects in high-T c superconductors (Gordon Bell Prize Winner),” Proc. 2008 ACM/IEEE conference on Supercomputing Conference on High Performance Networking and Computing, 2008; J.S. Meredith, G. Alvarez et al., “Accuracy and performance of graphics processors: A Quantum Monte Carlo application case study,” Parallel Comput., 35(3):151-63, 2009, 10.1016/j.parco.2008.12.004.
- S3D: a combustion application: Spafford, J. Meredith et al., “Accelerating S3D: A GPGPU Case Study,” in Seventh International Workshop on Algorithms, Models, and Tools for Parallel Computing on Heterogeneous Platforms (HeteroPar 2009). Delft, The Netherlands, 2009
 In recent years FTG has started looking a memory architecture. Vetter notes memory cuts across all areas of computing – scientific HPC, traditional enterprise, and mobile. “The Department of Energy funded a project with my group plus some external collaborators at Michigan and Penn state and HP to look at how non-volatile memory could offset this trend of shrinking node memory capacity,” he says.
In recent years FTG has started looking a memory architecture. Vetter notes memory cuts across all areas of computing – scientific HPC, traditional enterprise, and mobile. “The Department of Energy funded a project with my group plus some external collaborators at Michigan and Penn state and HP to look at how non-volatile memory could offset this trend of shrinking node memory capacity,” he says.
One challenge, of course, is that DRAMs don’t scale as they once did. They are also power hungry compared to other technologies. Vetter’s group is tracking various memory technologies (FLASH in terms of NAND and 3D NAND as well as resistive memristors, resistive RAM, phase change, etc.)
“We say, OK this technology looks like it has a nice trajectory and [we] go back to determine how can our applications make use of it and how can it be architected into a system so that users can make use of it. We’ve started looking very carefully at programming models and user scenarios of how non volatile memory could be integrated into a systems and how it would be used and those two are interrelated right,” he says.
“Right now people put an SSD in a system and you’ve got non-volatile memory in a system but it’s usually hidden behind a POSIX IO or some type of IO interface that makes it a little less interesting and lower performing. If you think about moving that memory higher and moving it closer and closer to the processor,” says Vetter, the benefits could be substantial, such as in the Titan scenario mentioned earlier.

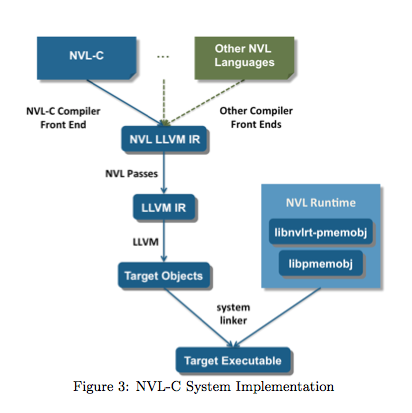
Exposing these new memory hierarchies directly to applications to take advantage of them is a hot topic these days. Along those lines Vetter and his FTG colleagues Joel Denny and Seyong Lee recently published a new paper – NVL-C: Static Analysis Techniques for Efficient, Correct Programming of Non-Volatile Main Memory Systems[i].
Here are two brief excerpts:
- “As the NVM technologies continue to improve, they become more credible for integration at other levels of the storage and memory hierarchy, such as either a peer or replacement for DRAM. In this case, scientists will be forced to redesign the architecture of the memory hierarchy, the software stack, and, possibly, their applications to gain the full advantages of these new capabilities. Simply put, we posit that these new memory systems will need to be exposed to applications as first-class language constructs with full support from the software development tools (e.g., compilers, libraries) to employ them efficiently, correctly, and portably.”
- “[W]e present NVL-C: a novel programming system that facilitates the efficient and correct programming of NVM main memory systems. The NVL-C programming abstraction extends C with a small set of intuitive language features that target NVM main memory, and can be combined directly with traditional C memory model features for DRAM. We have designed these new features to enable compiler analyses and run-time checks that can improve performance and guard against a number of subtle programming errors, which, when left uncorrected, can corrupt NVM-stored data.”
 FTG’s early focus was on heterogeneous computing “because we thought there were going to be several options, things like multicore, early GPUs, and even FPGAs,” says Vetter wryly at what hardly sounds leading edge today. “So we started looking at those in terms of programming models and expected performance and shortcoming and benefits of the architectures.” Among projects showcased today on the FTG website are – Kneeland Project (heterogeneous/GPU computing), Oxbow Program (tools for characterizing of parallel applications), OpenARC (open-sourced, OpenACC compiler).
FTG’s early focus was on heterogeneous computing “because we thought there were going to be several options, things like multicore, early GPUs, and even FPGAs,” says Vetter wryly at what hardly sounds leading edge today. “So we started looking at those in terms of programming models and expected performance and shortcoming and benefits of the architectures.” Among projects showcased today on the FTG website are – Kneeland Project (heterogeneous/GPU computing), Oxbow Program (tools for characterizing of parallel applications), OpenARC (open-sourced, OpenACC compiler).
Currently there are 11 members of FTG comprised of a mix of post-docs and staff scientists etc. The number fluctuates, says Vetter: “Some stay for a few years and some stay for a decade or more. One of the things I’ll say that I really like about the lab is that it’s open. We can collaborate and publish and our software is open so we can work with pretty much everyone we want to work with. The goal is to advance science not just develop another software tool or just write another paper but actually have impact on our applications teams and the DOE mission.”
Vetter notes FTG mission continues to expand, not least because its primary sponsor, DOE, is also changing its perspective.
“DOE right now has started to seriously think what happens after the exascale and what types of computing not only can we use but also how can we even contribute to next generation technologies,” he says. DOE, he notes, has a great deal of materials science research going on – “low level chemistry and other things going on in their nanoscale materials centers” – which may be needed in the post Moore, post exascale era and DOE, he says, is working to become a contributor to solving these problems, not just a downstream consumer.”
As you would expect, the national labs communicate regularly and collaborate. Vetter, for example, has worked with Adolfy Hoise of Pacific Northwest National Laboratory (PNNL) and director of its Center for Advanced Technology Evaluation, and others putting on workshop to “discuss performance analysis and modeling and simulating on these types of architectures.” Vetter was also last year’s Technical Program Chair for SC15.
The FTG has come a long way since its founding. “When I first joined Oak Ridge I think we had a 1Tflops Cray on the floor and now we have a 27Pflops Titan, and hopefully a 200Pflops machine soon. I think this is a great time to be in computer science because we’re entering this space where it’s not a given that we’ll just get a next generation x86. We have to start thinking very carefully about these choices and that puts us in a great mode for science and engineering. FPGAs, ASICS, specialized processors are going top help round out the CMOS but what will be next?”
[i] HPDC ’16 Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing; Pages 125-136; ISBN: 978-1-4503-4314-5 doi>10.1145/2907294.2907303
























































