 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The shift from single core to multicore hardware has made finding parallelism in codes more important than ever, but that hasn’t made the task of parallel programming any easier. In fact with the various programming standards, like OpenMP and OpenACC, evolving at a rapid pace, keeping up with the latest and best practices can be daunting, especially for domain scientists or others whose primary expertise is outside HPC programming. Auto-parallelization tools aim to ease this programming burden by automatically converting sequential code into parallel code. It’s one of the holy grails of computing, and while there are a handful of projects and products that support some degree of auto-parallelization, they are limited in what they can do.
HPC startup Appentra believes it has a unique approach to a classic HPC problem. The company’s Parallware technology is an LLVM-based source-to-source parallelizing compiler that assists in the parallelization of scientific codes with the OpenMP and OpenACC standards. CEO Manuel Arenaz refers to the process as guided parallelization.
Appentra was formed in 2012 by a team of researchers from the the University of A Coruña in Spain under the leadership of Arenaz, a professor at the university. 2016 brought some notable recognition. Last April, Appentra was selected as a 2016 Red Herring Top 100 Europe Winner, signifying the promising nature of the technology and its market-impact potential. And in November, the startup participated in the Emerging Technologies Showcase at SC16.
We recently spoke with the company’s CEO and co-founder to learn more about the technology and commercialization plans.
 “Parallelization has remained an open problem since the 80s,” says Arenaz. “Nowadays there is still not a product that can really help users to parallelize their code — not just simple [benchmark] codes, but mini apps or fragments or snippets of codes of large applications running on supercomputers. The parallelization stage [of the five-stage HPC programming workflow — see graphic] is where we provide value to the HPC community and what we do is try to make it easier to automatize some of the parts of this manual process that is converting the code from sequential to parallel.”
“Parallelization has remained an open problem since the 80s,” says Arenaz. “Nowadays there is still not a product that can really help users to parallelize their code — not just simple [benchmark] codes, but mini apps or fragments or snippets of codes of large applications running on supercomputers. The parallelization stage [of the five-stage HPC programming workflow — see graphic] is where we provide value to the HPC community and what we do is try to make it easier to automatize some of the parts of this manual process that is converting the code from sequential to parallel.”
Appentra’s product roadmap currently includes two tools, Parallware Trainer and Parallware Assistant, with the former due out later this year. Both will be sold under a subscription software licensing model, initially targeting academic and research centers.
Parallware Trainer will be the first product to market. It is billed as an “interactive real-time desktop tool that facilitates learning, implementation, and usage of parallel programming.” The purpose of the tool is to train the user, test the environment, and provide insights on the how the sequential code can be improved.
The key features of Parallware Trainer are summarized as follows:
- Interactive real-time editor GUI
- Assisted code parallelization using OpenMP & OpenACC
- Programming language C
- Detailed report of the parallelism discovered in the code
- Support for multiple compilers
 “You can conceive the Parallware Trainer tool as Google Translator but instead of going from English to Spanish, it goes from sequential code to parallel code annotated with OpenMP or OpenACC pragmas,” says Arenaz.
“You can conceive the Parallware Trainer tool as Google Translator but instead of going from English to Spanish, it goes from sequential code to parallel code annotated with OpenMP or OpenACC pragmas,” says Arenaz.
“It enables learning by doing, is student-centric, and allows the student to play with more complex codes even during the training. It enables playing not only with lab codes prepared by the teacher, but also with codes students are writing at their office, so they can really begin to apply the concepts to their own codes, facilitating a smooth transition back to the office.”
Appentra is finishing work on the Parallware Trainer package now and plans to release it in an early access program during Q1 of this year with a general launch slated for Q2 or Q3 of this year.
With the training tool, users are not provided access to the information that the technology considered in order to discover the parallelism and implement the parallelization strategy. In the learning environment, the black box nature of the tool is warranted because having access to that information creates unnecessary complexity for someone that is learning parallel programming. Experts of course want to have full drilldown into the decisions that were made; they want full control. So in Parallware Assistant, which targets HPC developers, Appentra will provide complete details of all the analysis conducted on the program.
Appentra’s goal with both products is to move up the complexity chain from microbenchmarks to mini-apps to snippets of real applications.
“From the point of view of the Parallware Trainer tool, the level of complexity at the microbenchmark is enough for learning parallel programming, but looking at the Assistant and looking at using the Parallware Trainer even with more complex codes, like mini-apps or snippets of real applications, we need to increase the matureness of the Parallware technology,” says Arenaz.
“So we are also working toward providing a more robust implementation of the technology with the complexity of the mini-app. We are looking at inter-procedural discovery of parallelism through a procedural fashion in code that uses structs and classes not only plain arrays. These are some of the features that are not usually present in microbenchmarks but are present in mini-apps and of course real applications.”
Appentra is developing its technology in collaboration with a number of academic partners. The startup has worked most closely with Oak Ridge National Lab (HPC researchers Fernanda Foertter and Oscar Hernandez have been instrumental in developing tools based on the company’s core tech), but also has industrial partnerships lined up at the Texas Advanced Computing Center and Lawrence Berkeley National Lab. In the European Union, the Parallware Trainer has been used as part of training courses offered at the Barcelona Supercomputing Center, which Appentra cites as another close partner.
Appentra has also been accepted as a member of OpenPower and sees an opportunity to connect with the other academic members.
“Our research has told us that universities should be interested in using this tool for teaching parallel programming – and not only computer science faculties, but also mathematicians, physicists, chemists – they also really need parallel programming but it is too complex for them,” says Arenaz. “They want to focus on their science not on the complexity of parallel programming, but they need to learn the basics of it.”
Arenaz acknowledges that there are other tools in the market that provide some level of auto-parallelization but claims they don’t offer as much functionality or value as Parallware.
“The Cray Reveal is only available on Cray systems and is very limited. It cannot guarantee correctness when it adds OpenMP pragmas for instance,” the CEO says. “It doesn’t support OpenACC. It only supports a very small subset of the pragmas of OpenMP. It doesn’t support atomic. It doesn’t support sparse computations. It has many technical limitations, apart from only being available in Cray supercomputers. And the other [familiar] one, the Intel Parallel Advisor, is mainly a tool that enables the user to add parallelism, but again it doesn’t guarantee correctness.
“In both tools, it is the user that is responsible for guaranteeing that the pragmas that are noted in the code are correct and are performant. That is something that our Parallware technology overcomes and solves. This is from the point of view of the technology itself among similar products in the market. If we focus on training from the point of view of the Parallware Trainer, there is no similar product on the market. No tool we are aware of — and we have talked with all these big labs and supercomputer centers — enables interactive HPC training as the Parallware Trainer tool does.”
One of the chief aims of Parallware technology is helping users stay current on standards from OpenMP and OpenACC. With standards evolving quickly, Appentra says this is where users will find a lot of value.
“OpenMP and OpenACC are evolving very fast. Each year they are more and more complex because 3-4 years ago they only supported one programming paradigm, the data parallel paradigm. But they have incorporated the tasking paradigm and the offloading paradigm to support GPUs, Xeon Phis, and any type of accelerator that can come into the market in the future pre-exascale and exascale supercomputing systems. So the hardware is evolving very fast and all of the labs and all of the vendors are working at the level of OpenMP and OpenACC to provide features in the standard that support the new features in the hardware, but this is making the standards very big and opening up many possibilities for the user to program in parallel the same piece of code, so this is opening up another range of complexity to the user.
“So we keep track of these standards, we keep track of the features of the code because every single source code is unique. It has some slightly different features that makes it different from other very similar code even in the same computational field. That is our job mainly at the Parallware development team, to keep track of these features, select the most important features, select the most important features in the OpenMP and OpenACC standards and connect them through Parallware technology, through this magic component that is the converter from sequential to parallel. That’s our work and that’s where the high-added value of our tools derives.”
Right now, Appentra is focused on adding the higher-complexity features of the OpenMP and OpenACC standards, but MPI is also in their sites.
“When we started the company, we created a prototype that automatically generated MPI code at the microbenchmark and it is something [we do] internally in our group. The problem that we faced is we were claiming that we were able to automatically parallelize codes using OpenMP, OpenACC and MPI but industry labs and supercomputing facilities didn’t even believe that we could do it for OpenMP, so we decided to stay focused on the standards that are easier for us to parallelize because as a startup company we need to focus on the low-hanging fruit.”
Here’s one example of how a Parallware implementation stacks up to hand-parallelized code from the NAS Parallel Benchmarks suite, a small set of programs designed at NASA to help evaluate the performance of parallel supercomputers. The red line shows the speedup gained with the parallel OpenMP implementation provided in the NAS parallel benchmark implementation. The green line is the OpenMP parallel implementation automatically generated by the Parallware technology. You can see that for a given number of threads the execution time is very close.
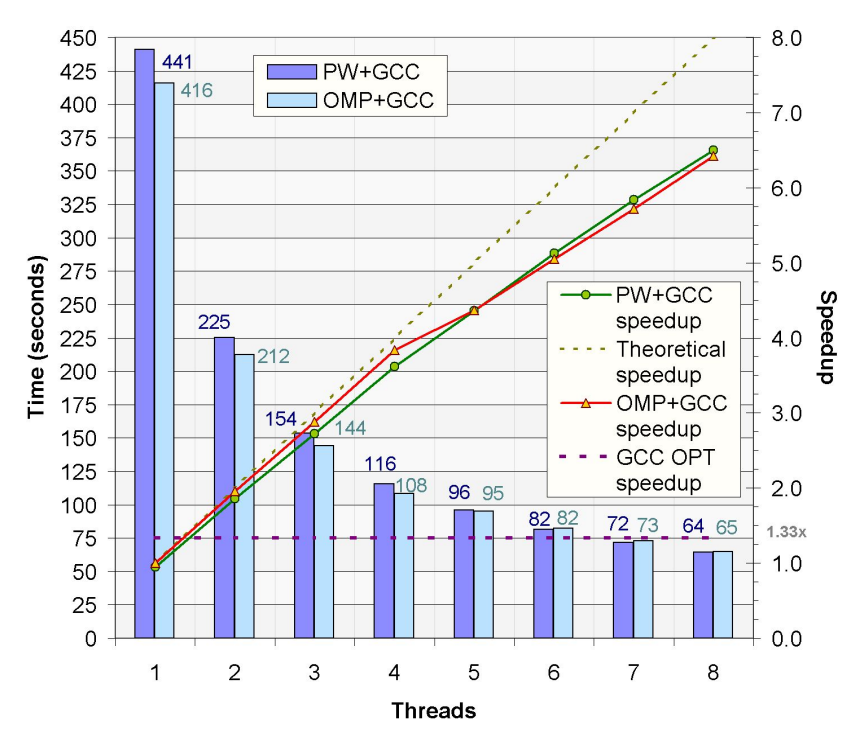
Initially, Appentra supports the C language, but Fortran is on their roadmap. Says Arenaz, “We are aware that 65-70 percent of the HPC market at this moment in big labs is Fortran code and the remaining 30-35 percent is C code. The reason why we are not supporting Fortran at this moment is a technical issue. We are based on the LLVM infrastructure, which only supports C at this time. It doesn’t support Fortran. Support for Fortran is a work in progress by PGI and NVIDIA through a contract with the national labs. We are partners of Nvidia so we will have early access to the first releases with Fortran support for LLVM. So we are working on Fortran support and we expect it might be some of the new features we might announce at Supercomputing next year.”


























































