 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Last April, the third and final piece of the CORAL acquisition program clicked into place when the U.S. Department of Energy signed a $200 million supercomputing contract with Intel to supply Argonne National Laboratory with two next-generation Cray supercomputers: an 8.5-petaflop “Theta” system based on Knights Landing (KNL) and a much larger 180-petaflop “Aurora” supercomputer.
The staff at the Argonne Leadership Computing Facility (ALCF), where the machines will be deployed, is looking ahead to the future of these systems and the evolution of computing at the facility. To find out more about their preparations and plans, HPCwire spoke with the project director, ALCF Deputy Division Director Susan Coghlan. Just as she facilitated the deployment of Mira in 2012, Coghlan will oversee the installation of Theta in the second half of 2016 and Aurora in 2018.
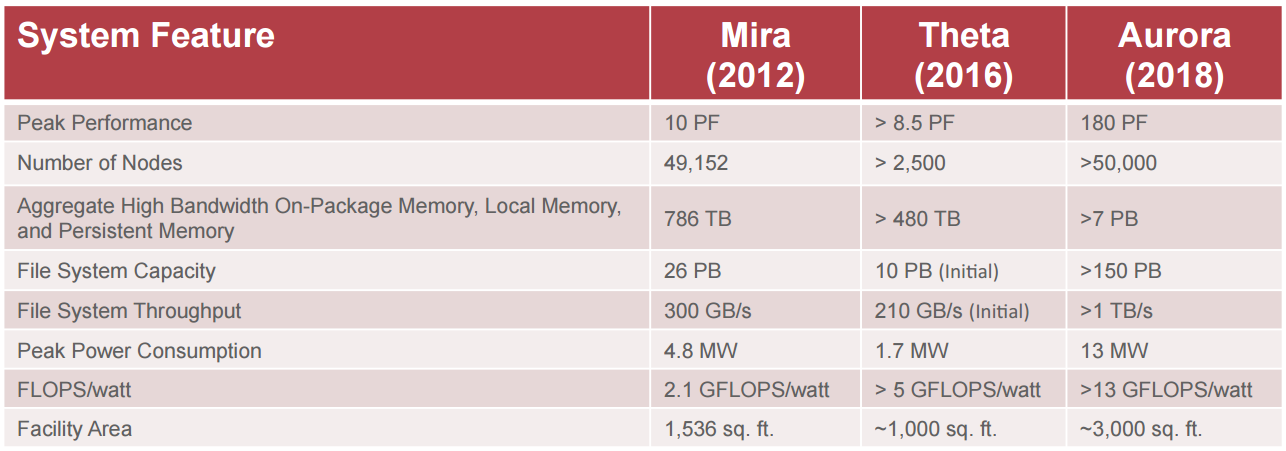
While details of these machines’ feeds and speeds remain unchanged since the debut announcement last April, their slated arrival has kicked off a slurry of activity at Argonne, including the ramping up of the Early Science Program (ESP) projects that ALCF announced in August. The Theta ESP involves 12 projects in all, split into tier one and tier two camps, which you can read more about here. They were selected to represent a wide range of scientific domains and algorithms/numerical methods to enable “science on day one” and offer lessons that would carry over to the larger ALCF code base.
What’s New
The Theta ESP was modeled after the successful Mira ESP but there are some noteworthy elements included in the ALCF-3 ESP (as the current effort is known internally) that reflect dominant trends in research HPC, one of which is the rise of memory hierarchy. The selection criteria for the projects required feedback on how project PIs would address this architectural shift.
“With these new machines that are coming, there is a small amount of super fast memory and a large amount of super slow memory, and more steps between that and the file system,” said Coghlan, noting the development is born of fiscal necessity.
“Due to the cost of having large amounts of super fast memory, we are going to have these hierarchies and we’re working to understand how that impacts the science and how the scientist can leverage them and extract the best performance given these different hierarchies and different APIs for laying out jobs within the memory.”
Application portability was the other big focus for the ESP. Argonne is partnering with the Berkeley and Oak Ridge labs to support this compatibility between the manycore-based systems at ALCF and NERSC and the GPU-based system at OLCF. Each of the labs has its own early science programs (NESAP at NERSC and CARR at OLCF), and they tried not to overlap projects in order to gain broader coverage. As part of this focus, computational time has been allocated across the sites for the early codes to run not just on their home machines, but on the “sister” machines as well.
Getting Ready for Knights Landing
The early science project researchers along with the support staff at ALCF are working with Cray and Intel on porting and optimizing and tuning their codes for Theta’s KNL-based architecture. They’ve been using an open source simulator called Sniper to assess the performance of their applications. The simulator is outfitted with proprietary modules from Intel that provide the details for KNL. While not a cycle accurate simulator, it is much faster, Coghlan noted. It enables the computer scientists and researchers to analyze applications to see how they will behave on the real hardware. “The project participants have been analyzing the codes within the simulator to see how they might tune it, what they need to tweak, and so forth,” said the project director. “We then provide information back to Intel on the issues we saw, optimization possibilities, etc.”
ALCF does not have KNL hardware on site yet, but the team has run its core CORAL application set (not the early science set) on the KNL hardware at Intel. Argonne is expecting to receive early hardware prior to the actual machines being delivered to the floor and the systems themselves will be delivered ahead of general availability.
The User Experience
Going from the IBM BlueGene/Q Mira to the Cray/Intel x86 ecosystem is a shift for the users and there are some software differences, but Coghlan said she expects a smooth transition to the Cray and Intel compilers due to their high quality and wide deployment. A lot of the other software tools will stay the same as they are supported in both environments. The machines also share the same programming environment, in most cases MPI with OpenMP.
A more significant change, to Coghlan’s mind, is on the networking side, going from a 5-dimensional Torus to a Dragonfly topology.
“It’s very expensive to implement these Torus interconnects, especially in five dimensions. While the Dragonfly is a less expensive solution, it does come with costs to the user.” she explained. “Some of the benefits that we have with the 5D Torus, especially with the way it’s implemented on the BlueGene, we won’t have. For example, on Mira, when you run a job, you are guaranteed that your compute interconnect is conflict-free from anyone else’s job on the machine. It’s electrically isolated. The Dragonfly doesn’t have that capability. We are exploring what to do here and what the impact will be on the user.”
One expected benefit of the architectural shift, according to Coghlan, is that the second and third-generation Xeon Phi processors, KNL and KNH (Knights Hill), will have vectorization, which “should help users get better performance improvements without going to extreme measures.”
Accommodating Data Science
Another key area of focus at Argonne is the move to support more data-intensive science, a segment that is increasingly able to take advantage of leadership-class facility scale resources. “In the past, there were some projects that benefited from this level of compute, but in general many could get by at a smaller scale than what the leadership-class sites provide,” said Coghlan. “Now, there’s more and more science that can take advantage of the resources at the super large scale and we have a number of projects underway that we’ve worked with.”
One of these projects was carried out on Argonne’s Cray data analytics cluster, called Cooley. The work involved big data processing for HPC analytics, specifically using Apache Spark. They didn’t achieve the scale of Mira or the upcoming systems, Coghlan noted, but they had good results getting it to scale better. She sees this as something that’s important to work on for HPC in general, adding that “applications such as Spark and others don’t yet run well at large-scale and the related software is not optimized to run at these scales, but there is a need on the science side to do it.”
When it comes to enabling real-time versus batch processing, Coghlan said that her team is very interested in this area — her colleague Pete Beckman even developed a successful token system to enable “urgent computing” on Teragrid. It’s largely a matter of policy she said: “When you do real-time, there is an assumption of availability — one way to do this is to have preemptions such that a certain amount of resources are guaranteed to be available for the real-time job and when they start running you kill everything that is running on the resources so that the priority job can run. There is also some work that needs to happen on the tech side, notably involving the resource manager.”
The machine learning space is another area that Argonne is pursuing. Coghlan cited the research of James Kermode who used the Mira system to do molecular dynamics on-the-fly incorporating machine learning techniques. She said they are still looking at how best to support those kinds of workloads, given that they can have some unique requirements.
Another project was carried out by Tom LeCompte, the physics coordinator for the ATLAS experiment, to simulate LHC events. Using adaptive grid workflows combined with improvements to I/O and memory usage, the team was able to complete such a large number of ATLAS cycles that if they were a country, they would be the seventh largest provider to the experiment.
“Those are some of the types of things we are seeing the need for — connection to the experimental facilities, the real-time aspect, the machine learning, and the data-intensive technologies that need to work on the machines that don’t yet,” said Coghlan. To this end, Argonne is gearing up to launch a new science program, which for now they are calling “data science program.”
The ALCF leadership team is in the process of drafting up a call for the program, which they hope to announce in the next month or two. The plan is to support an on-going program consisting of four projects debuting each year, two that are technology-based, i.e., focused on improving the performance of certain workflows or technologies (like Spark), and two that are science-focused. The program will benefit from the coming big iron as Theta and Aurora have more data-intensive type resources in terms of larger memory, more interesting memory hierarchies, and vector I/O bandwidth. The projects will also have access to the ALCF staff and potentially the Cray-Intel folks as well. Argonne is getting this effort off the ground despite not receiving any dedicated funding for it.
Towards a Unified Platform
Is the ideal of a modern platform that can straddle the traditional and emerging data-centric workloads achievable? “That’s been something that people have been talking about for quite a while and it wasn’t really clear if you could do it,” Coghlan observed. “I think it can be done — it is a matter of priorities for the machine and the stakeholders. This will be an opportunity for us to explore that space and find out whether it really is doable and whether it makes sense. But right now, most facilities have a compute-focused machine and a data analytics-focused machine, and they don’t tend to mix. At Argonne, starting with the KNL parts and additional memory and storage elements to support data-intensive science, it makes sense to explore doing both on the same hardware.
“Ultimately, we really would prefer to have machines that are more flexible that are able to do and support both types of science especially as the data-heavy science, much of it is supporting compute-intensive and vice versa. We have a lot of coupled things — the cosmology code called HACC (for Hardware/Hybrid Accelerated Cosmology Code), that is looking at dark matter, dark energy, and the origins of the universe. It pulls in the SLOAN sky survey data and does data-analysis work on it but they are also running simulations and comparing the observed data with what they see in their simulations and they want to be able to do those in a coupled fashion and being able to do that in the same machine makes it that much easier.”






















































