 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
NERSC is beginning to tell the world how to optimize applications to run on the new Intel Xeon Phi processors, code name Knights Landing (KNL), that will boot in self-hosted mode to power over 9,300 nodes of the Cori supercomputer by the summer of 2016. Indeed, general availability of KNL is expected before the end of Q2 making early guidance all the more useful. The recent NERSC presentation at SC15, Early Experiences Optimizing Applications for the CORI Supercomputer, covers tools, techniques, and sources of information that developers can use now to optimize codes for Cori, Intel Xeon, and the new Intel Xeon Phi processors.
This panel presentation provides insights by Katie Antypas (NERSC Scientific Computing and Data Services department head) plus a NERSC panel comprised of Richard Gerber (senior science advisor and group lead of the User Services Group), Doug Doerfler (computer systems engineer), and Brian Austin (staff member Advanced Technologies Group). In particular, Antypas pointed out that, “Cori is a pre-exascale system that will showcase a number of the technologies that we are going to see in eventual exascale systems in the 2020 timeframe,” which means these optimizations have a high likelihood of carrying over to future exascale supercomputers as well.
The NERSC Edison supercomputer is currently the largest system on the NERSC floor. It is a Cray XC30 powered by Intel Xeon processors (formerly code-named Ivy Bridge). Antypas pointed out that, “This system is incredibly popular with users. What NERSC needs to do now is move that workload over to more advanced energy efficient architectures,” meaning the new Intel Xeon Phi processor nodes.

Adapting codes to run efficiently on the Cori Intel Xeon Phi processor nodes isn’t a trivial task; NERSC users must ensure their codes can fully exploit the many lightweight cores, the longer vector length AVX-512 instructions, and the deeper memory architecture of the new Intel Xeon Phi processors. For power, heat, and thermal reasons, the many cores on a single KNL chip are based on the Intel Silvermont microarchitecture rather than a high-clock rate Intel Xeon core. Instead, dual-vector units per-core are provided to deliver very high Intel Xeon Phi processor floating-point performance.
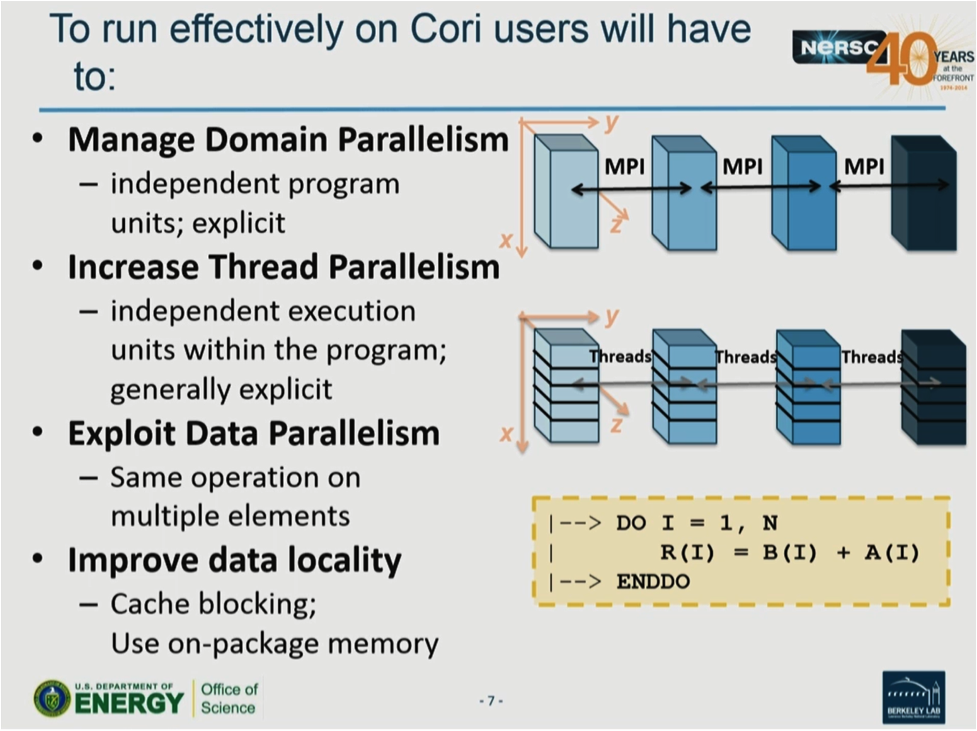
The scope of the transition is daunting as over 5,000 users and 700 projects need to be transitioned from the Edison Intel Xeon processors to the new Intel Xeon Phi processors. To run well means that applications must exhibit good MPI scaling, exploit vectorization, and utilize OpenMP or another threading model to increase thread parallelism by an order of magnitude to over 240 threads per processor. Antypas stressed that, “Vectorization is no longer something users can ignore”. She backed this up with the observation that, “Before, vectorization provided a speed increase of 2x – 4x. Now it will be 8x.” In short, users need to focus on (1) exploiting 10x more threads, (2) achieving a possible 8x vectorization speedup, plus (3) efficiently utilizing the deeper memory hierarchy that will be present on the Cori Intel Xeon Phi processor nodes.
To make the migration process manageable, twenty applications teams were selected for the NERSC Application Readiness Program (NESAP). These teams will to work closely with Intel and Cray to prepare their applications to run efficiently on the Intel Xeon Phi processor nodes. The codes span a wide domain of scientific applications as shown below.
Advanced Scientific Computing Research (ASCR):
- Optimization of the BoxLib Adaptive Mesh Refinement Framework for Scientific Application Codes, PI: Ann Almgren (Lawrence Berkeley National Laboratory)
- High-Resolution CFD and Transport in Complex Geometries Using Chombo-Crunch, David Trebotich (Lawrence Berkeley National Laboratory
Biological and Environmental Research (BER)
- CESM Global Climate Modeling, John Dennis (National Center for Atmospheric Research)
- High-Resolution Global Coupled Climate Simulation Using The Accelerated Climate Model for Energy (ACME), Hans Johansen (Lawrence Berkeley National Laboratory)
- Multi-Scale Ocean Simulation for Studying Global to Regional Climate Change, Todd Ringler (Los Alamos National Laboratory)
- Gromacs Molecular Dynamics (MD) Simulation for Bioenergy and Environmental Biosciences, Jeremy C. Smith (Oak Ridge National Laboratory)
- Meraculous, a Production de novo Genome Assembler for Energy-Related Genomics Problems, Katherine Yelick (Lawrence Berkeley National Laboratory)
Basic Energy Science (BES)
- Large-Scale Molecular Simulations with NWChem, PI: Eric Jon Bylaska (Pacific Northwest National Laboratory)
- Parsec: A Scalable Computational Tool for Discovery and Design of Excited State Phenomena in Energy Materials, James Chelikowsky (University of Texas, Austin)
- BerkeleyGW: Massively Parallel Quasiparticle and Optical Properties Computation for Materials and Nanostructures (Jack Deslippe, NERSC)
- Materials Science using Quantum Espresso, Paul Kent (Oak Ridge National Laboratory)
- Large-Scale 3-D Geophysical Inverse Modeling of the Earth, Greg Newman (Lawrence Berkeley National Laboratory)
Fusion Energy Sciences (FES)
- Understanding Fusion Edge Physics Using the Global Gyrokinetic XGC1 Code, Choong-Seock Chang (Princeton Plasma Physics Laboratory)
- Addressing Non-Ideal Fusion Plasma Magnetohydrodynamics Using M3D-C1, Stephen Jardin (Princeton Plasma Physics Laboratory)
High Energy Physics (HEP)
- HACC (Hardware/Hybrid Accelerated Cosmology Code) for Extreme Scale Cosmology, Salman Habib (Argonne National Laboratory)
- The MILC Code Suite for Quantum Chromodynamics (QCD) Simulation and Analysis, Doug Toussaint (University of Arizona)
- Advanced Modeling of Particle Accelerators, Jean-Luc Vay, Lawrence Berkeley National Laboratory)
Nuclear Physics (NP)
- Domain Wall Fermions and Highly Improved Staggered Quarks for Lattice QCD, Norman Christ (Columbia University) and Frithjof Karsch (Brookhaven National Laboratory)
- Chroma Lattice QCD Code Suite, Balint Joo (Jefferson National Accelerator Facility)
- Weakly Bound and Resonant States in Light Isotope Chains Using MFDn — Many Fermion Dynamics Nuclear Physics, James Vary and Pieter Maris (Iowa State University)
Fifty application teams applied to the NESAP program, and NERSC selected 20 to partner with most closely to prepare for the Cori KNL architecture. Lessons learned from these 20 application teams will be shared more broadly with the NERSC user community. As it turns out, the NERSC workload is highly diverse, but extremely concentrated in about 20-30 application codes. In fact the top 25 applications make up about 2/3rd of the NERSC workload. With the exception of a few emerging applications, the 20 NESAP teams come from this top tier and thus represent the NERSC workload.
Antypas acknowledges that some applications will have an easier time being ported to the Knights Landing architectures than others. Such codes are generally amenable to thread and vector optimizations. She said other codes with very flat execution profiles “Might take years to optimize.” Further, codes with strong serial runtime components can be problematic as the serial section may need to be parallelized over threads and/or vector operations. Such parallelization can be difficult.
Starting the transition now to Intel Xeon Phi code name Knights Landing
An excellent discussion occurred amongst the panel members about how to transition applications to the Cori Intel Xeon Phi processor nodes – even though the Intel Xeon Phi processor nodes are not scheduled to be operational until summer 2016.
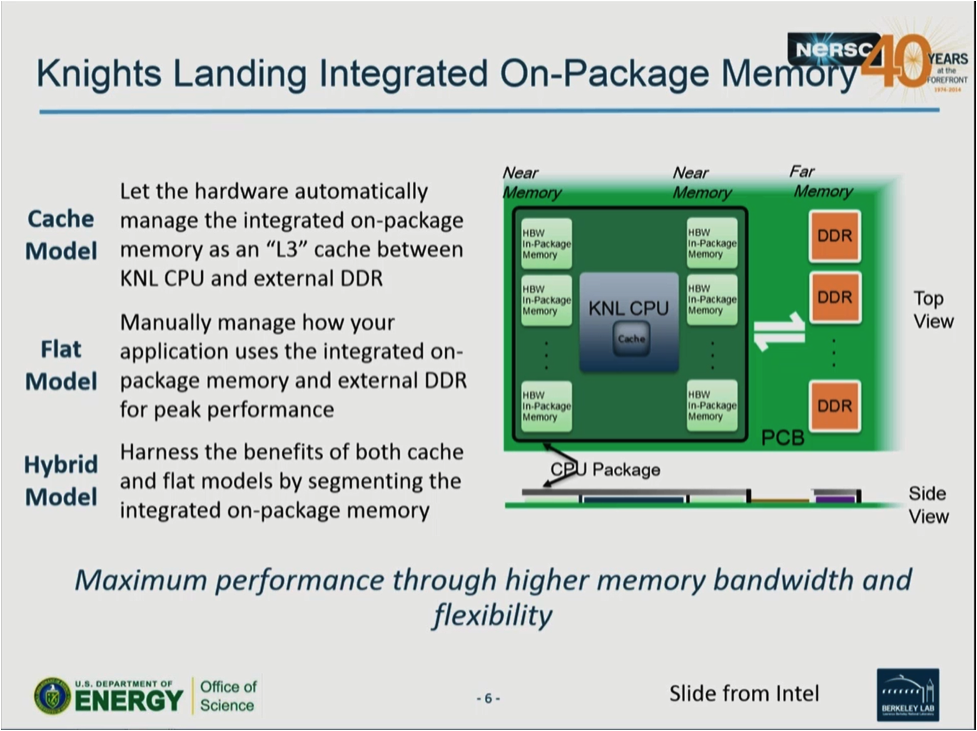
Overall, the NERSC team is excited about the on-package high-bandwidth MCDRAM near-memory memory shown in the graphic below. Typically NERSC applications are limited by memory bandwidth not flop/s.
The challenge with deep memory on the Cori Intel Xeon Phi processor nodes is the small 16 GB MCDRAM memory capacity compared to the 100 GB of DDR far-memory memory. To get the best performance, users will need to determine which arrays benefit most from the fast on-package MCDRAM memory. Fortunately, users can also access the MCDRAM via a ‘cache-mode’ which does not require any changes to a code. In the coming months NERSC staff and NESAP teams will be exploring the different memory modes and the performance and usability trade-offs between ‘flat-mode’ and ‘cache-mode’.
Doerfler pointed out that a primary benefit of transitioning applications to KNL is that developers have to think harder about vector and thread level parallelism. The result is codes that run faster on both Intel Xeon Phi and Intel Xeon processors. Doerfler also noted, “The transition to multilevel memory is important to exascale because developers are thinking about data locality.”
As for optimizing codes right now, Doerfler likes Intel VTune Analyzer to profile application performance but he has found that the Intel Software Development Emulator (or Intel SDE) can be very illuminating. The more he uses it the more excited he gets by it. Succinctly he said, “I encourage people to go out and use it”.
Austin told the audience that if you can run well on the older Intel Xeon Phi processors then you are well prepared to run on the Cori nodes. The performance key is to ensure that your MPI code can utilize threads on each MPI client to exploit the vector and thread-parallel features of the Intel Xeon Phi processors.
Gerber stressed that anyone who wishes to prepare for Cori should talk to the Intel Xeon Phi User’s Group (IXPUG), which is an independent user group whose mission is to provide a forum for the free exchange of information to improve the efficiency and usability of HPC applications running on large Intel Xeon Phi processor based HPC systems. Gerber pointed out that the IXPUG five minute lighting talks, “Tales from the trenches” are a great source of information about lessons learned for performance tricks, tools, and other useful Intel Xeon Phi processor performance information. IXPUG has proven to be wildly popular with numerous events happening all around the world. For example, Gerber noted that over 150 people showed up at the Berkeley meeting, which filled the room beyond capacity and prevented some from attending.
Until we have operational Cori nodes, the NERSC panel suggests using the following hardware proxies based on the characteristics of the application. However, the key point is simply to develop hybrid MPI/threaded applications code and then start running when hardware is available.
- Lots of threads: run on Intel Xeon Phi processor.
- Lots of vectorization: use Intel Xeon Phi processor but groups can do a lot of good vectorization work on Intel Xeon processors.
- Investigate memory depth: there is no good proxy for memory depth until the Knight Landing processor is available, but groups can use memkind (a user extensible heap manager for heterogeneous and mixed memory platforms), but the speed differentials are not that great on the current generation of hardware.
In conclusion, the NERSC team pointed out that they have some great application case studies on the NERSC website. NERSC is really trying to educate the community.
View the video of the entire panel discussion.
For more information:
IXPUG: https://www.ixpug.org
Cori application porting: http://www.nersc.gov/users/computational-systems/cori/application-porting-and-performance/
About the Author
Rob Farber is a global technology consultant and author with an extensive background in HPC and a long history of working with national labs and corporations engaged in both HPC and enterprise computing. He can be reached at info@techenablement DOT com.























































