 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
In advance of the SC16 expo in Salt Lake City next week, the OpenACC standards group today welcomed newest member NSSC-Wuxi and highlighted a number of important developments for the directives-based programming standard. Ahead of the announcement, HPCwire spoke with Michael Wolfe, technical director of OpenACC, and Duncan Poole, OpenACC president and director of platform alliances for accelerated computing at Nvidia.
OpenACC (Open Accelerators) was developed by Cray, CAPS, Nvidia and PGI circa 2011. The standard was designed to simplify parallel programming of heterogenous CPU-GPU machines and has since added support for additional multicore/manycore platforms, while maintaining code portability.
OpenACC’s newest member is the National Supercomputing Center (NSCC) in Wuxi, China, home to the TaihuLight Sunway system, which made its grand TOP500 entrance at ISC 2016, pushing the LINPACK record to 93 petaflops. NSCC-Wuxi runs a custom version of OpenACC developed for the Sunway system’s 260-core Chinese-made processor.
“The OpenACC paradigm was chosen for its better fit to our many-core processor, with a few extensions to better support the efficient utilization of the new hardware features such as the Scratch Pad Memory for each core and DMA instructions,” said Dr. Haohuan Fu, deputy director of the National Supercomputing Center in Wuxi and associate professor Center for Earth System Science at Tsinghua University, in a prepared statement.
TaihuLight’s Sunway manycore processors are composed of four core groups; each core group has one management processing element (MPE) and 64 compute processing elements (CPEs) for a total of 260 cores per CPU. Says Wolfe, who is also a compiler engineer with PGI (Nvidia), “Essentially, there’s a control processor that runs the main application and offloads the parallel region to the compute elements. When they’re using OpenMP the offload model offloads the parallel part to the compute elements and the master thread goes on with the scalar part of the code. NSCC-Wuxi wanted that master thread to participate in the parallel work and thought that would be more natural with the OpenACC model.” Wolfe added that OpenMP also has a lot of synchronization constructs that are challenging to implement on the manycore architecture.
OpenACC was used to parallelize and tune one of three NSCC-Wuxi codes on the short-list to receive the prestigious Gordon Bell prize at SC16. CAM-SE is a “10 million core scalable fully-implicit solver for nonhydrostatic atmospheric dynamics” that contains 530,000 lines of code.
A number of flagship HPC codes are also using OpenACC, notably Gaussian, widely-used in quantum chemistry, and ANSYS Fluent, the popular commercial CFD software. “We build and support Fluent on a wide variety of parallel computing systems, and we need to be able to write a single version of our source code that runs efficiently on all of those systems,” said Sunil Sathe, Fluent lead software developer. “With OpenACC, we were able to quickly enable a key solver for GPU acceleration while keeping the same code base for CPU execution. The OpenACC performance was excellent on NVIDIA GPUs and very competitive on CPUs.”
OpenACC is also being used by five of the thirteen application-readiness codes used to qualify the 200-petaflops Summit supercomputer that is going in at Oak Ridge Labs. “This shouldn’t be a surprise because the Oak Ridge Leadership Computing Facility is a big OpenACC user today,” said Duncan Poole, president of OpenACC and Nvidia executive.
OpenACC also has production support for OpenPower, both multicore OpenPOWER and CPU + GPU implementations. Poole said that support for manycore Xeon CPUs (i.e., the Knight Landing Phi and follow-ons) is on track for 2017. The latter will be key for the Summit supercomputer, which will have some 3,400 nodes comprising multiple Power9 CPUs and multiple NVIDIA Volta GPUs, connected with Nvidia’s second-generation NVLink technology. For more information about how OpenACC is supporting the OpenPower architecture, see our June coverage.
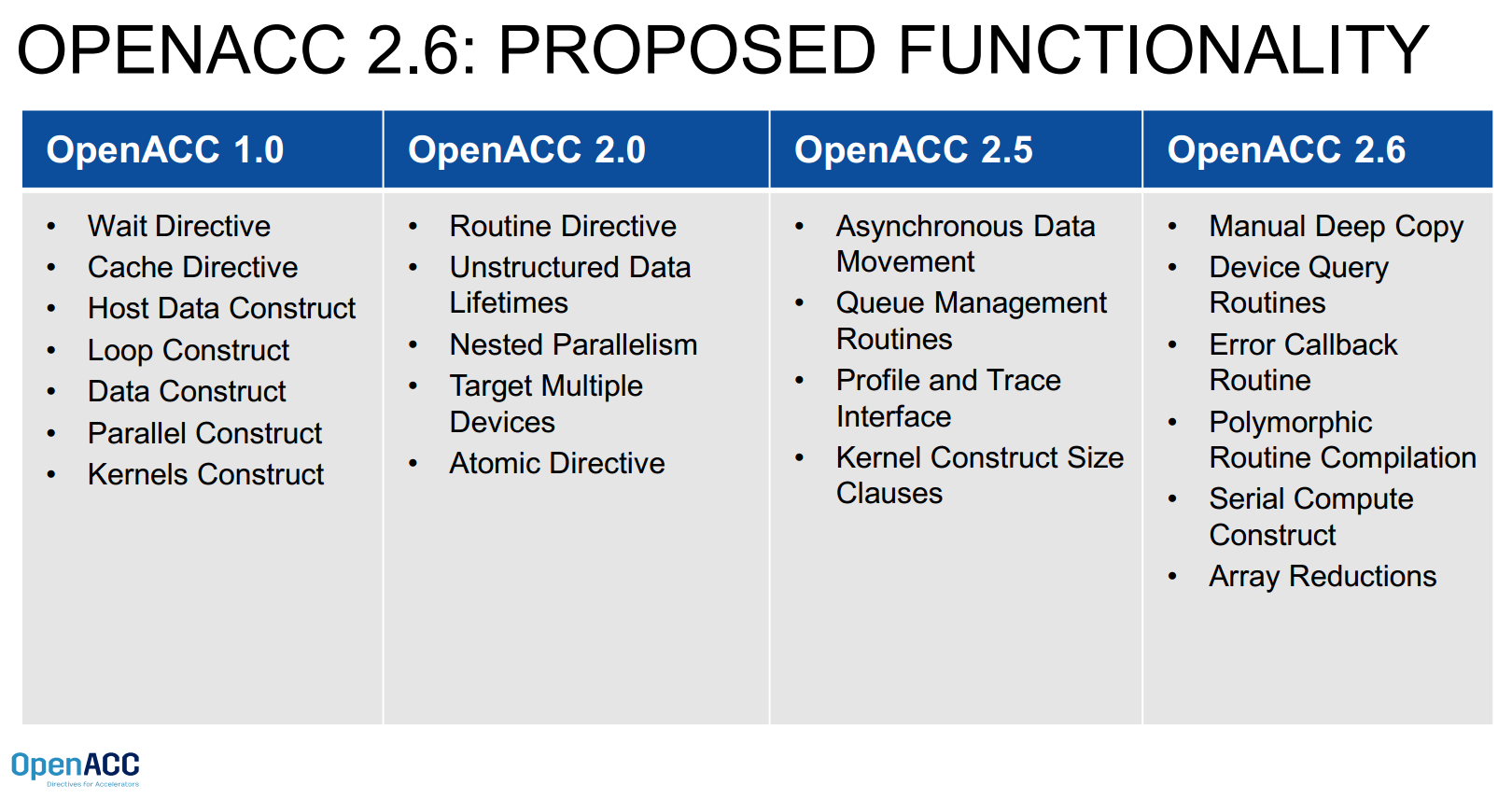
The OpenACC roadmap
OpenACC also previewed features that will be added to its next release (2.6), being targeted for the middle of next year. One of the key features that’s been requested by users for the last couple years is “deep copy.” When we talked with Wolfe last year at this time, he said deep copy was being targeted for the 3.0 release, but now the standards body is planning a sort of interim step, to enable OpenACC to support a manual deep copy.
Wolfe explains, “This is where you have deeply nested data structures with pointers to other data structures that have pointers to other data structures and want to move the whole structure over to the device, which is a different memory space with different addresses and still keep the pointers valid.
“We’ve been struggling with a way to define this in manner that is seamless to use and still performant. We arrived at the decision to make a small change to the specification so that users can do a manual deep copy.”
Manual deep copy gives users the behavior that they want although it’s not as conventient as they would like, Wolfe commented. The standards group is looking for someone to do an implementation of the true deep copy before it is hardened into the specification. Wolfe wouldn’t speculate on a timeline: “If we can get a prototype implementation, our hope is that that may shake out potential problems, but we cannot predict how many of those there might me.”
Additional features planned for OpenACC include Device Query Routines, Error Callback Routine, Polymorphic Routine Compilation, Serial Compute Construct, and Array Reductions.
These are all highly requested by users, the actual people working on programs, said Wolfe.
OpenACC doesn’t have a calendar-based release cadence. Instead, they collect requests and push out a new release when they have a critical mass to constitute a new release.
“What we want to work on is the big items, things like true deep copy or a seamless way to spread parallel regions across multiple devices, or load balancing across the GPU and the CPU and how do you manage that. Those are big items; those are what users really want,” said Wolfe.
He added, “Last summer I was visiting CSCS in Lugano, Switzerland, and each node of the cluster they host for the weather forecasting service MateoSwiss has four K80s, so eight GPUs per node. Well how do you manage that? Is it easy or is there a way to make it even easier, that’s a big challenge, and we’re ready to take it on.”
Community engagement and education
Via partnerships with Oak Ridge National Laboratory and other member orgs, OpenACC continues to offer hackathons around the world. More info is at http://www.openacc.org/hackathons. Oak Ridge and OpenACC will also be conducting a series of free two and half day workshops starting next year. These are designed to introduce developers to the framework and are a new addition to OpenACC’s training and education program.
SC16 activities include:
OpenACC Birds of a Feather, Wed. Nov. 16th 5:30–7:00PM in room 155-C. Discussion will include such topics as “Should OpenACC and OpenMP ever merge”.
Free “Parallel Programming with OpenACC” books will be signed by author Rob Farber Monday, November 14 from 7:00 to 9:00 pm in the OpenACC booth #634.
Bringing About HPC Open-Standards World Peace, Nov. 16th, 10:30 am 255-BC
Members will be available for questions in the OpenACC booth #634.
Visit http://www.openacc.org/sc16 for a list of all OpenACC member activities.

























































