 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The details of China’s upgrade to Tianhe-2 (MilkyWay-2) – now Tianhe-2A – were revealed last week at the Third International High Performance Computing Forum (IHPCF2017) in China. The Tianhe-2A will use a proprietary accelerator (Matrix-2000), a proprietary network, and provide support for OpenMP and OpenCL. The upgrade is about 25 percent complete and expected to be fully functional by November 2017 according to a report by Jack Dongarra who attended the meeting and has written a fairly detailed summary.
“The most significant enhancement to the system is the upgrade to the TianHe-2 nodes; the old Intel Xeon Phi Knights Corner (KNC) accelerators will be replaced with a proprietary accelerator called the Matrix-2000. In addition, the network has been enhanced, the memory increased, and the number of cabinets expanded. The completed system, when fully integrated with 4,981,760 cores and 3.4 PB of primary memory, will have a theoretical peak performance of 94.97 petaflops, which is roughly double the performance of the existing Tianhe-2 system. NUDT also developed the heterogeneous programming environment for the Matrix-20002 with support for OpenMP and OpenCL,” writes Dongarra (Report on The TianHe-2A System).
Dongarra told HPCwire, “The Matrix-2000 was designed by the NUDT people. They claim it was fabbed in China. They did not want to have the manufacturing process disclosed.”
The Tianhe-2 vaulted China atop the Top500 list in June of 2013 (with 33.9 petaflops Linpack performance) where it stayed until June 2016 when China’s Sunway TaihuLight topped the list with a Linpack of 93 petaflops. The Sunway was China’s first supercomputer to use homegrown processors (see HPCwire article, China Debuts 93-Petaflops ‘Sunway’ with Homegrown Processors). China has held the top two positions ever since.
“The TianHe-2A is one of the three prototype systems for Exascale in China. The others are the TaiHu Light in Wuxi and the Sugon Machine based on X86 architecture,” said Dongarra.

Each of the 17,792 Tianhe-2A compute nodes will use two of Intel’s Ivy Bridge CPUs (12 cores clocked at 2.2 GHz) and two of the new NUDT-designed Matrix-2000 accelerators (128 cores clocked at 1.2 GHz). This combination results in a compute system with 35,584 Ivy Bridge CPUs, 35,584 Matrix-2000 accelerators, reports Dongarra.
Introduction of the China-developed Matrix-2000 accelerator showcases China’s continued progress towards technology independence.
As described by Dongarra, each Matrix- 2000 has 128 compute cores clocked at 1.2 GHz, achieving 2.4576 teraflops of peak performance. The peak power dissipation is about 240 watts and the dimensions are 66mm by 66mm. The accelerator itself is configured with four supernodes (SNs) that are connected through a scalable on-chip communication network. Each SN has 32 compute cores and complies with the cache coherence. The accelerator supports eight DDR4-2400 channels and is integrated with a ×16 PCI Express 3.0 endpoint port. The compute core is an in-order 8~12 stage reduced instruction set computer (RISC) pipeline extended with a 256-bit vector instruction set architecture (ISA). Two 256-bit vector functional units (VFUs) are integrated into each compute core, resulting in 16 double precision FLOPs per cycle. Thus, the peak performance of the Matrix-2000 can be calculated as: 4 SNs × 32 cores × 16 FLOPs per cycle × 1.2 GHz clock = 2.4576 Tflop/s.
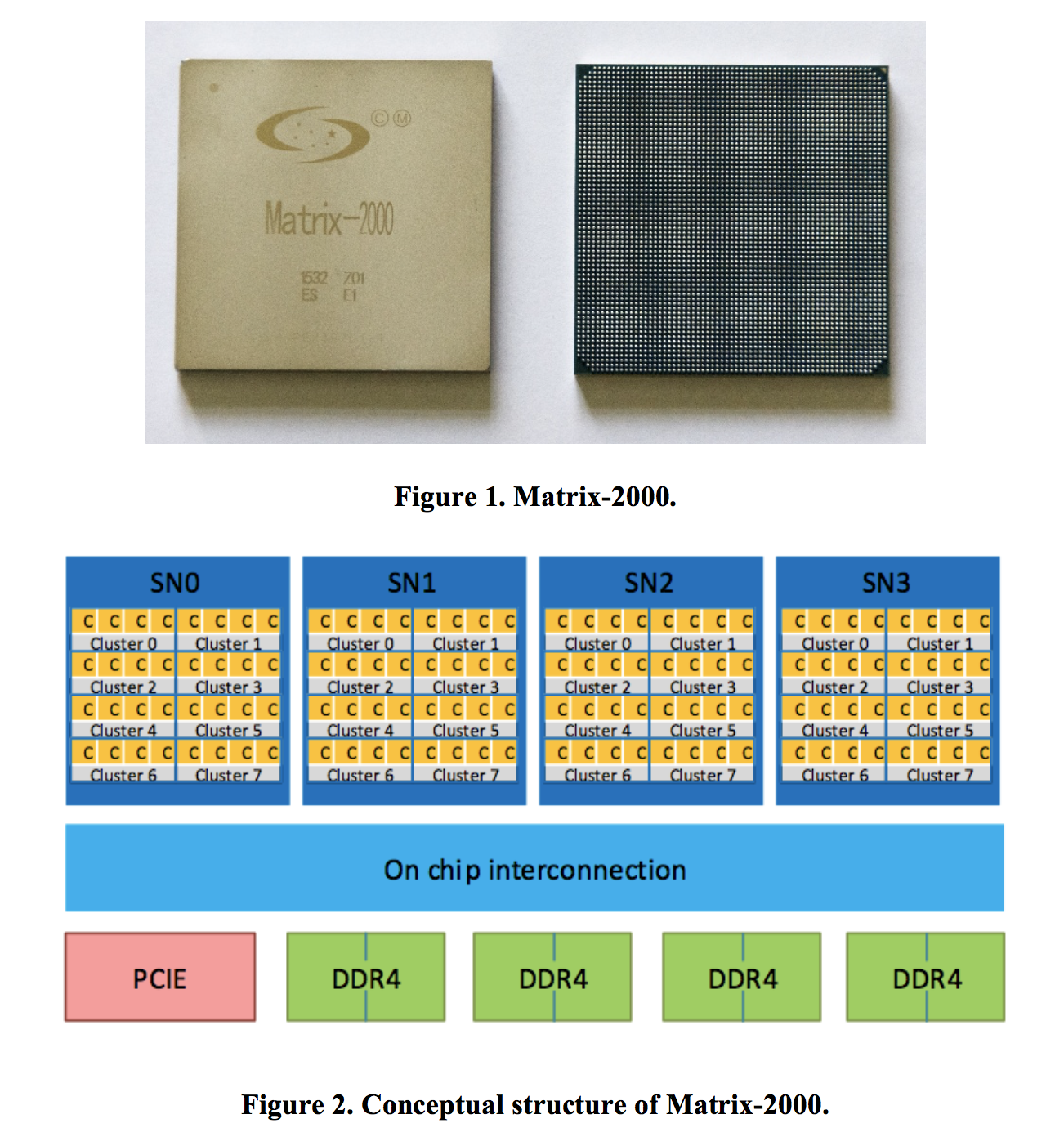
As shown below, a TH-2A compute blade is composed of two parts: the CPM (left) and the APU (middle). The CPM integrates four Ivy Bridge CPUs, and the APU integrates four Matrix- 2000 accelerators. Each compute blade contains two heterogeneous compute nodes.

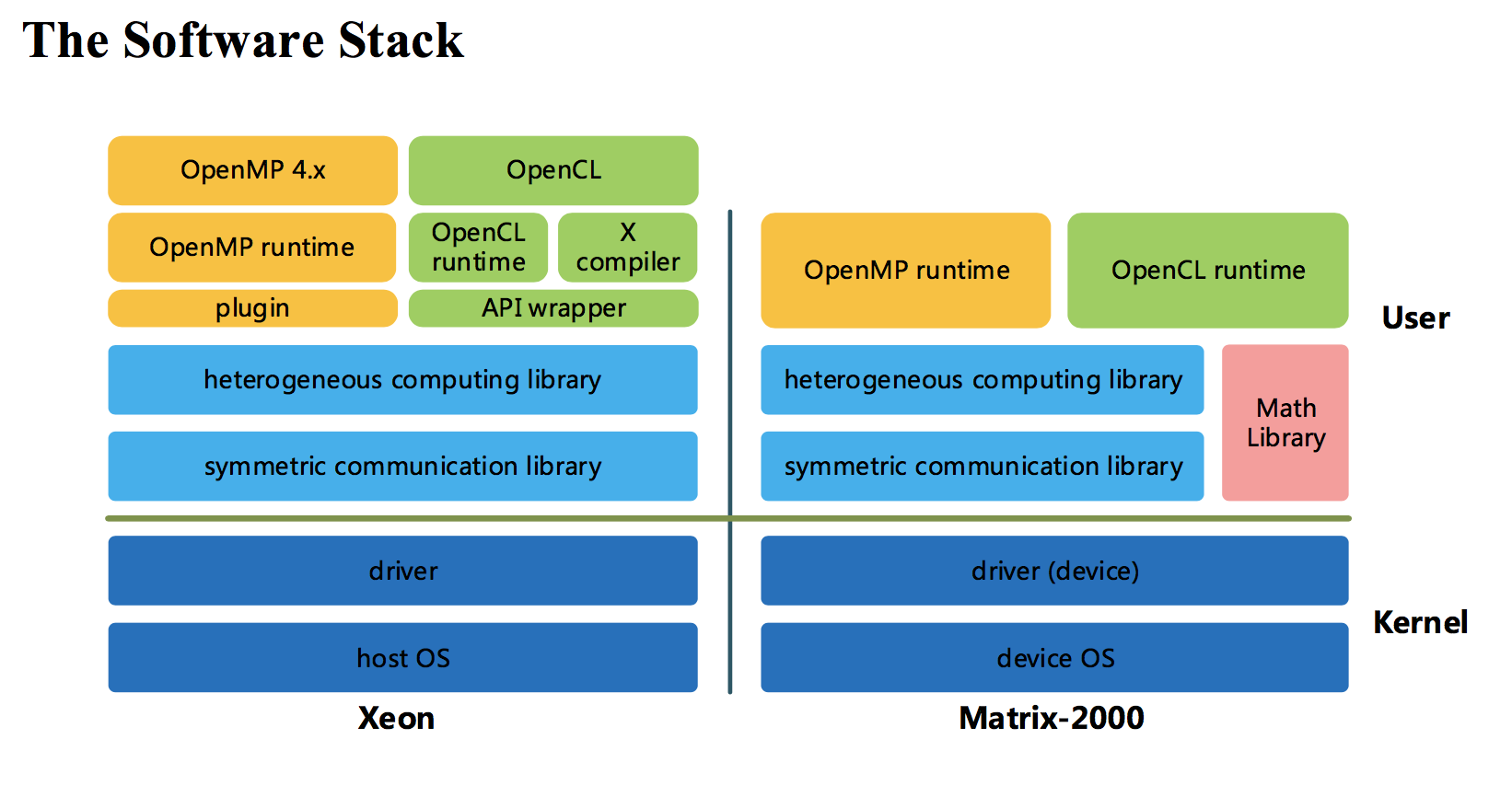
The TH-2A upgrades required the design and implementation of a heterogeneous computing software stack for the Matrix-2000 accelerator writes Dongarra. This software stack provides a compiling and execution environment for OpenMP 4.5 and OpenCL 1.2. The runtime software stack is illustrated in figure below.
“In kernel mode, there is a light-weight Linux-based operating system (OS), with the accelerator device driver embedded within it, running on the Matrix-2000 that provides device resource management and data communication with the host CPU through the PCI Express connection. The OS manages the computing cores through an elaborately designed thread pool mechanism, which enables task scheduling with low overhead and high efficiency.”
China’s rapid advance in supercomputing and its accelerated effort to build its own technology ecosystem has been a hot topic for some time. Dongarra captures the dynamics and technology achievement neatly his summary:
“In February 2015, the US Department of Commerce prevented some Chinese research groups from receiving Intel technology. The department cited concerns about nuclear research being performed on compute systems equipped with Intel components. The research centers affected include: NSCC-G, site of Tianhe-2; the National SC Center Tianjin, site of Tianhe-1A; the NUDT, developer; and the National SC Center Changsha, location of NUDT.
“At the 2015 International Supercomputing Conference (ISC) in Frankfurt, Yutong Lu, the director of the NSCC-G, described the TianHe-2A system (Figure 10). Most of what was shown in her slide in 2015 has been realized in the Matrix-2000 accelerator. They had hoped to replace the Intel KNC accelerator in their TH-2 with the Matrix-2000 by 2016. However, because of delays that has not happened until very recently.
“After the embargo on Intel components by the US Department of Commerce, it has taken NUDT about two years to design and implement a replacement for the Intel Xeon Phi KNC accelerator. Their replacement is about the same level of performance as the current generation of Intel’s Xeon Phi, known as Knights Landing (KNL). Equaling the performance of the state-of-the-art KNL chip and developing the accompanying software stack in such a short time is an impressive result.”
Last week’s IHPCF2017 meeting was sponsored by the Ministry of Science and Technology (MOST) and the National Science Foundation of China (NSFC), organized by NUDT, and hosted by the National Supercomputer Center in Guangzhou (NSCC-GZ); it was held on September 18–20, 2017 in Guangzhou, China. There were roughly 160 attendees, reported Dongarra.
Given this latest announcement, and speculation of what may be happening with the TaihuLight system, the SC17 conference in November should spark interesting discussion. Clearly the international jostling for sway in the race to pre- and full exascale machines continues to heat up. Just last week, the U.S. Exascale Computing Project announced the retirement of Paul Messina as director and appointment of Doug Kothe as new director.
Expectations are high that Summit (Oak Ridge National Laboratory) will be at or near the top of the Top500 list. Likewise, there’s been speculation that Sierra (Lawrence Livermore National Laboratory) might be ready by then. It’s been awhile since the U.S. was top dog in the Top500. In any case, it will be interesting to see the next batch on LINPACK scores and what shuffling of the Top500 emerges.
Link to Dongarra’s excellent summary paper: https://www.dropbox.com/s/0jyh5qlgok73t1f/TH-2A-report.pdf?dl=0

























































