 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Lately the quantum news cycle never slows. More advances were reported on different underlying qubit technologies (superconducting and cold atom) by Lawrence Berkeley National Laboratory’s Advanced Quantum Testbed (AQT) and Atom Computing. It’s still not clear which of many competing qubit technologies (superconducting, cold atom, trapped ion, etc.) will become the dominant engines in quantum computing.
Back in January, the Quantum Economic Development Consortium (QED-C) released a paper on application-oriented benchmarks; last week IonQ referenced those benchmarks in its first report to the financial industry since going public. Quantum performance benchmarking is still nascent and it will be interesting to if efforts by QED-C, which is focused on commercialization, are embraced by the quantum community. In its paper, QED-C contrasts its approach with the IBM-developed Quantum Volume (QV) metric.
Amazon Web Services (AWS) reported it joined Q-NEXT, a quantum research center that is developing the science and technology for controlling and distributing quantum information. Yesterday, PsiQuantum introduced an initiative – Qlimate – to prioritize work on decarbonization technology projects. Last on the list, and perhaps further away from near-term direct application in quantum computing, Las Alamos National Laboratory researchers reported a break-through in chaos theory that has implications for quantum information sciences.
Let’s start with advances in competing underlying qubit technologies.
AQT Reports High-Fidelity iToffoli Gate
Noisy intermediate-scale quantum processors typically support one- or two-qubit native gates, the types of gates that can be implemented directly by hardware. More complex gates are implemented by breaking them up into sequences of native gates. AQT researchers, working with semiconductor-based superconducting qubits, reported implementing a “robust native three-qubit iToffoli with a gate fidelity of 98.26 percent. The work was published in Nature Physics this month.
An account of the work, written by Monica Hernandez, was posted this week on Berkeley Lab’s website. The Toffoli or the controlled-controlled-NOT (CCNOT) is a key logical gate in classical computing because it is universal, so it can build all logic circuits to compute any desired binary operation. Furthermore, it is reversible, which allows the determination and recovery of the binary inputs (bits) from the outputs, so no information is lost. Here’s a brief excerpt from the article:
“In quantum circuits, the input qubit can be in a superposition of 0 and 1 states. The qubit is physically connected to other qubits in the circuit, which makes it more difficult to implement a high-fidelity quantum gate as the number of qubits increases. The fewer quantum gates needed to compute an operation, the shorter the quantum circuit, thereby improving the implementation of an algorithm before the qubits decohere causing errors in the final result. Therefore, reducing the complexity and running time of quantum gates is critical.
“In tandem with the Hadamard gate, the Toffoli gate forms a universal quantum gate set, which allows researchers to run any quantum algorithm. Experiments implementing multi-qubit gates in major computing technologies – superconducting circuits, trapped ions, and Rydberg atoms – successfully demonstrated Toffoli gates on three-qubit gates with fidelities averaging between 87% and 90%. However, such demonstrations required researchers to break up the Toffoli gates into one- and two-qubit gates, making the gate operation time longer and degrading their fidelity.”
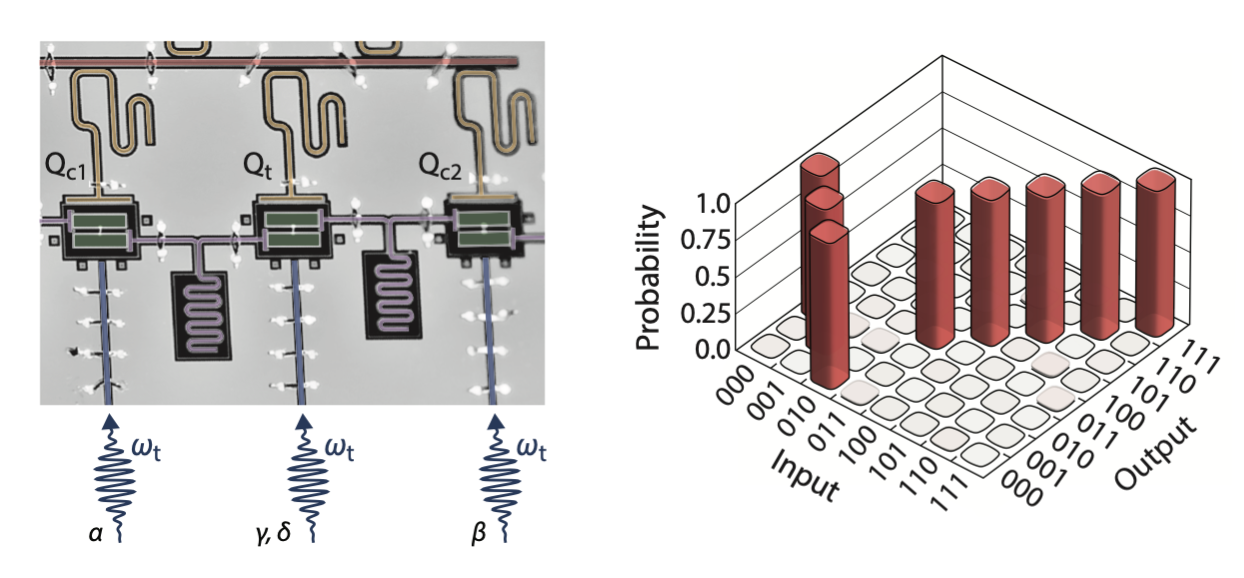
In their Nature Physics paper (High-fidelity three-qubit iToffoli gate for fixed-frequency superconducting qubits), the researchers write, “The development of noisy intermediate-scale quantum devices has extended the scope of executable quantum circuits with high-fidelity single- and two-qubit gates. Equipping these devices with three-qubit gates will enable the realization of more complex quantum algorithms and efficient quantum error correction protocols with reduced circuit depth. Several three-qubit gates have been implemented for superconducting qubits, but their use in gate synthesis has been limited owing to their low fidelity.
“Here, using fixed-frequency superconducting qubits, we demonstrate a high-fidelity iToffoli gate based on two-qubit interactions, the so-called cross-resonance effect. As with the Toffoli gate, this three-qubit gate can be used to perform universal quantum computation…Our work not only brings a high-fidelity iToffoli gate to current superconducting quantum processors but also opens a pathway for developing multi-qubit gates based on two-qubit interactions.”
Explanation of the difference between a Tofolli and iTofolli gate from AQT: “Short answer: The iToffoli gate is a Toffoli gate with a phase shift/phase rotation of “i”. The longer answer is, the Toffoli gate is a controlled-controlled-NOT gate, meaning that if the first two qubits are in the 1 state, then the last qubit is flipped. The iToffoli gate on the other hand is very similar, also a controlled-controlled-NOT gate, but the last qubit is flipped and also gets a phase rotation of “i”, which is equivalent to 90 degrees, and done so by applying the microwave pulses at the same frequency in a linear chain.”
Atom Computing Showcases Phoenix Capabilities
The use of neutral, cold atoms as the basis for qubits is attractive for many reasons and Atom Computing is one of several companies pursuing the approach (see HPCwire coverage).
As noted in Atom Computing’s paper in Nature last week, “Until recently, optical tweezer systems primarily used alkali metal atoms, which have favorable level structures for rapid loading and cooling of the atoms, along with the ground-state hyperfine structure that enables the manipulation of metastable spin states via microwave transitions. However, optical tweezer technology is agnostic to the specific atom chosen. Recent work has demonstrated the ability to use the same platform for trapping alkaline-earth atoms, which have attractive properties for the storage and coherent manipulation of quantum information, as well as for cooling, state preparation, and measurement of the internal state of the atoms.”
In the work, Atom Computing showcases its first-generation Phoenix system for assembling a register of highly coherent qubits encoded in the nuclear spin degree of freedom of atoms with a closed-shell S- orbital. The new system, reports the company, is an evolution of recent alkali-based programmable quantum simulators, “but, importantly, Phoenix is able to apply tailored pulses to subsets of individual qubits in parallel—a crucial feature for gate-based quantum computation. In particular, we trap individual 87Sr atoms in an array of optical tweezers, prepare a uniformly filled register of spin-polarized atoms, then individually manipulate, and read out the spin state of the qubits.”
The researchers reported that even with simultaneous manipulation of multiple qubits within the register, they achieved coherence in excess of 105 times the current length of the operations, with Techo of 40 ± 7 seconds. “We anticipate that nuclear spin qubits will combine readily with the technical advances that have led to larger arrays of individually trapped neutral atoms and high-fidelity entangling operations, thus accelerating the realization of intermediate-scale quantum information processors.”
According to a company spokesperson, “The most notable achievement we describe in this paper is the long coherence times of each of our qubits. Coherence is a term used to describe how long a qubit maintains its quantum state or encoded information. It’s important because longer coherence times mean fewer limitations on running deep circuits, and error-correction schemes have more time to detect and correct errors through mid-circuit measurements. On Phoenix, we set a new high water mark for coherence time.”
As always, it’s best to read the paper directly.
QED-C Benchmark Cited by IonQ
Benchmarking is an important developmental area in quantum computing and quantum information sciences generally with efforts scattered widely throughout the community (companies, DOE labs, QED-C). In January, QED-C issued a paper– Application-Oriented Performance Benchmarks for Quantum Computing – which is an early QED-C effort to stimulate standards use and development. (For a fuller discussion on QED-C’s mission see HPCwire interview with executive director Celia Merzbacher.)
Produced by a QED-C technical committee, the latest paper’s authors write:
“[W]e introduce an extensible suite of quantum application-oriented performance benchmarks, complementing other recent methods that use, e.g., small chemistry problems or basic quantum circuits as benchmarks. Demonstrated in Figure 1, each benchmark in our suite is derived from an algorithm or application and specifies a scalable family of quantum circuits. The benchmarks are designed to evaluate the capability of quantum hardware to successfully execute a meaningful computational task, and are intended to reflect likely use cases for quantum computers. The benchmarking suite is available as a public, open-source repository with extensive documentation. Validated implementations of our benchmarks are supplied in multiple common quantum programming languages, including Qiskit, Cirq, Braket and Q#, and can be rapidly deployed on nearly all major cloud quantum computers.
“Our benchmarking suite is designed to measure proxies for the quality of and the time to solution for each application. In analyzing the results of these benchmarks, we adopt the framework of volumetric benchmarking, as shown in Figure 1. This approach, which generalizes the quantum volume, displays the result quality for each application as a function of the problem size (circuit width) and the computation’s length (circuit depth). To do so, we define a normalized measure of result quality that makes results from different applications comparable, and we define a normalized, device-independent measure of circuit depth that removes complications associated with diverse native gate sets and dissimilar device connectivity. The resulting analysis enables easy comparison of how various quantum devices execute the same computational tasks.”

The QED-C work cites IBM’s QV metric, “IBM introduced the quantum volume (QV) metric in recognition of the need for a simple way to quantify and compare the capabilities of quantum computing devices. The quantum volume is a single metric that is influenced by multiple factors contributing to the overall performance of a quantum computer, including its number of qubits, systemic errors, device connectivity, and compiler efficiency. Several vendors and users have welcomed this as a step towards quantifying what a quantum computer can do…Note, however, that arguably no single number can summarize the many dimensions that make up a quantum computer’s performance characteristics. For example, the quantum volume is not guaranteed to reliably predict the performance.”
The real test, of course, will be how widely QED-C benchmarks are used and being cited by IonQ last week is a positive step – “In February, IonQ announced that the latest-generation IonQ Aria system achieved a record 20 algorithmic qubits, representing a significant leap forward for IonQ.” In this case “algorithmic qubit” is a metric derived in part from the QED-C work.
IonQ told HPCwire, “In short, algorithmic qubits (#AQ) is IonQ’s preferred single-number metric for quantum computing that it proposed in 2020, where it was developed as an application-oriented metric to assist the industry in evaluating quantum computers’ utility in real-world settings. Moreover, #AQ uses a series of algorithmic benchmarks first pioneered by the Quantum Economic Development Consortium (QED-C) to evaluate the number of algorithmically-relevant quantum bits (qubits) in a system in order to focus on the practical application of quantum computers…Additional information on #AQ can be found in IonQ’s algorithmic qubits blog.”
PsiQuantum to Tackles Climate Change Tech
Mitigating the effects of climate change is rightfully on many agendas. At the Davos conference yesterday, PsiQuantum announced Qlimate, “A subsidiary of PsiQuantum, Qlimate is a quantum computing net zero initiative that builds partnerships to develop and scale decarbonization technology breakthroughs.”
PsiQuantum, like many others, has set ambitious goals. It reported that Qlimate has “short-listed the most promising and highest impact decarbonization use cases that can run on first-generation utility-scale quantum computers. These use cases will enable breakthrough solutions across agriculture, solar, electric batteries, green hydrogen, carbon capture, green ammonia, cement and more. Taken together, these use cases will enable substantial decarbonization impact, and contribute towards the planet getting back on a 1.5°C pathway.”
The company says Qlimate is partnering with business, government and philanthropy to deliver on this mission, and will “optimize use case algorithms for deployment on the first utility-scale quantum computer, quantify their impact, and scale the resulting solutions.”
AWS Joins Q-NEXT; Las Alamos Researchers on Chaos

Last week AWS joined Q-NEXT, one of the quantum research centers established by the National Quantum Initiative Act and based at Argonne National Laboratory. Currently there are 13 companies, 10 universities, and three DOE labs at Q-NEXT. In 2021, AWS opened the AWS Center for Quantum Computing. Its goal is to accelerate the development of quantum computing hardware and applications based on superconducting qubits.

Lastly, Las Alamos National Laboratory reported a “breakthrough in understanding quantum chaos could open new paths into researching quantum information and quantum computing.” Here’s an excerpt from the announcement:
“By applying balanced energy gain and loss to an open quantum system, we found a way to overcome a previously held limitation that assumed interactions with the surrounding environment would decrease quantum chaos,” said Avadh Saxena, a theoretical physicist at Los Alamos National Laboratory and member of the team that published the paper on quantum chaos in Physical Review Letters. “This discovery points to new directions in studying quantum simulations and quantum information theory.”
“Quantum chaos differs from classical-physics chaos theory. The latter seeks to understand deterministic, or non-random, patterns and systems that are highly sensitive to initial conditions. The so-called butterfly effect is the most familiar example, whereby the flap of a butterfly’s wings in Texas could, through a bewilderingly complicated but not random chain of cause and effect, lead to a tornado in Kansas.”























































