 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Already entrenched in the deep learning community for neural net training, Nvidia wants to secure its place as the go-to chipmaker for datacenter inferencing. At the GPU Technology Conference (GTC) in Beijing today (Tuesday), Nvidia CEO Jen-Hsun Huang unveiled the latest additions to the Tesla line, Pascal-based P4 and P40 GPU accelerators, as well as new software all aimed at improving performance for inferencing workloads that undergird applications like voice-activated assistants, spam filters, and recommendation engines.
Employing the same form factor as the Maxwell-based M4 and M40 GPUs, the new Pascal cards were designed to accelerate inferencing workloads. Most significantly, the GPUs feature specialized inference instructions based on 8-bit (INT8) operations. Using the VGG image recognition model as a benchmark, Nvidia reports that the P40 achieved a 45x faster response than a E5-2690v4 Xeon (with the latest Intel Math Kernel Library) and a 4x improvement over the M40, which debuted last November at Supercomputing. In both cases, the P40 was running INT8 instructions, while the comparison hardware was employing FP32.
For the test, Nvidia paired the Tesla P40 with an internal version of the company’s TensorRT library, which is also being announced today. TensorRT, formerly known as GIE (GPU Inference Engine), enables the trained neural net to run well on Pascal GPUs, says Nvidia. The library takes neural nets, typically built with 32-bit or 16-bit operations, and tunes them for the specific GPU to be used for deployment.
“If there’s a GPU in the datacenter like the P4 or P40 then TensorRT will automatically recognize that and transform that neural net into 8 bit,” said Roy Kim, a product manager in Nvidia’s Tesla HPC business unit. “And TensorRT will take neural net and deploy it anywhere – it could deploy it in an embedded Jetson program for example.”
On the training side, models need the higher accuracy of at least 16-bit floating point (FP16), but once the models are trained, this dynamic range can be reduced down to an 8-bit range without a loss of accuracy. The upshot of INT8, is that it enables four times as much throughput compared to single-precision floating point (FP32).
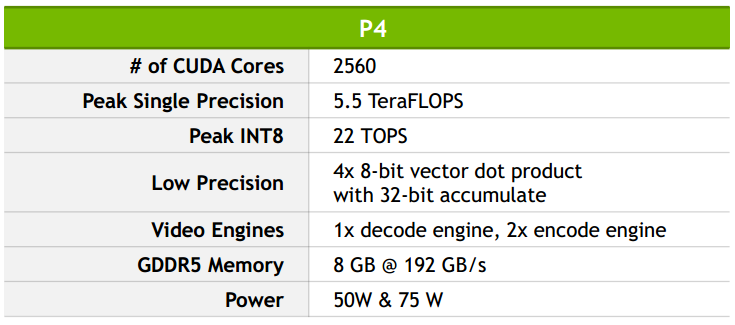
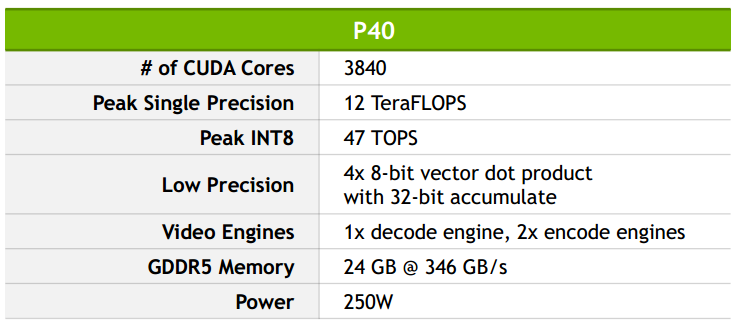
The P4 is designed for the scale-out datacenter server and prioritizes energy efficiency whereas the P40 emphasizes high throughput for deep learning workloads. The P40 is for customers who want to deploy lots of GPUs in a box in batch mode for overnight processing of video data, for example, said Kim. A single Tesla P4 provides 22 Tera-Operations per second (TOPS) while the P40 offers 47 Tera-Operations per second (TOPS) — both figures are with boost clock enabled.
Nvidia also unveiled a new software development kit to help speed video analytics workloads. DeepStream SDK has APIs for transcoding video onto various formats, it has SDK to preprocess those videos, and it has the APIs and support for deep learning frameworks, the company said. With DeepStream, a single Tesla P4 server (with two E5-2650 v4 CPUs) can simultaneously decode and analyze up to 93 HD video streams in real time compared with seven streams on a GPU-less Broadwell-based box, according to Nvidia.
Nvidia continues to count Baidu as a key partner and confirmed that the Chinese search giant still uses Nvidia GPUs for training and inferencing its Deep Speech 2 system. Hyperscalers like Baidu are increasingly concerned with minimizing the time it takes for their systems to recognize speech, images or text in response to queries from users and devices.
“Delivering simple and responsive experiences to each of our users is very important to us,” said Greg Diamos, senior researcher at Baidu. “At Baidu, we have deployed NVIDIA GPUs in production to provide AI-powered services such as our Deep Speech 2 system and the use of GPUs enables a level of responsiveness that would not be possible on un-accelerated servers.”
“The complexity of that Deep Speech 2 model has increased by 10x in just one year,” said Nvidia’s Kim. “So it makes sense from the training side why they need GPUs. But on the inferencing side, they are seeing a problem. Whereas it used to be okay to deploy on CPU servers, it isn’t tenable anymore. With hyperscalers every millisecond matters. Baidu believes that after 500 milliseconds, user engagement goes down. With the Pascal GPU the response is almost immediate, about 100 milliseconds.”
Nvidia said it went through pains to ensure it used the latest Intel hardware and software for its comparison testing. The graphics chipmaker’s message is that even the latest Broadwell CPUs are challenged by today’s complex inferencing workloads. To Intel’s mind, however, the star of its deep learning portfolio is its Xeon Phi manycore processor. We imagine a fuller picture of the comparative performance advantages of Nvidia and Intel silicon will emerge when Pascal GPUs go head to head against Knights Landing on a range of workloads. Things will get even more interesting next year with the debut of the next-generation Phi processor, Knights Mill, which will support lower-precision computations.
The Tesla P40 is expected to be available next month and the P4 the month after. The cards will be available from all major OEMs and ODMs, including Dell Technologies, HPE, Inspur, Inventec, Lenovo, QCT, Quanta Computer and Wistron.
The DeepStream SDK will be available to early users as part of an invite-only closed beta program.

























































