Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Greetings from Frankfurt and the 2017 International Supercomputing Conference where the latest Top500 list has just been revealed. Although there were no major shakeups — China still has the top two spots locked with the the 93-petaflops TaihuLight and the 33.8 petaflops Tianhe-2 — there are some interesting historical and global trends to share, as well as notable Green500 results with Japan capturing the top four spots.
In the top ten strata of the 49th Top500 list, the names are the same but Piz Daint, the Cray XC50 system installed at the Swiss National Supercomputing Centre (CSCS), has moved up five positions from number eight to number three. The punched-up processing was provided thanks by replacing older Tesla gear with Nvidia Tesla P100 GPUs (see coverage here for more details), doubling the previous 9.8 Linpack petaflops score to 19.6 petaflops. The Intel processors were also upgraded: from Sandy Bridge to Haswell architecture.
Piz Daint’s rise has pushed the 17.6-petaflops U.S. Titan supercomputer down to fourth position, leaving the United States without a claim to any of the top three rankings. As the Top500 authors observe in today’s announcement, the only other time this has happened was in November 1996, when Japan dominated all three top spots.
For reference, the new top 10 rankings are reproduced below:

This minimal list reshuffling led Top500 watcher and market analyst Addison Snell to comment, “With no changes in the Top 10 systems other than the Piz Daint upgrade, it may look like things aren’t moving forward, but this is the lull before a spate of new supercomputers that could hit the next list, particularly the two CORAL pre-exascale systems at U.S. national labs and the possibility of the Chinese Tienhe-2A upgrade.
“Some of the more interesting trends occur over the rest of the list population,” the CEO of Intersect360 Research continued. “For example, the number of manycore systems continues to rise, whether as accelerators or co-processors, which are mostly Nvidia GPUs, or with the Intel Xeon Phi as a standalone processor. This is driving related improvements in power efficiency, which is necessary in the run-up to exascale. It’s also notable to see Intel Omni-Path adoption continuing on the list. We are monitoring this in our end-user surveys to see how much penetration Omni-Path might have versus Ethernet and InfiniBand.”
When asked if he thought the CORAL systems, Summit and Sierra, would be ready next time this year, Snell said he wouldn’t be surprised if they come sooner than that. So SC17? We caught Snell in between flights but we’ll be asking him more about his thinking here during ISC. The U.S. has announced an exascale accelerated timeline (see our latest U.S. exascale coverage here) and promised additional monies to fund it, so a quickening for “pre-exascale” here makes sense if partners IBM, Nvidia and Mellanox can accommodate.
Then, as Snell also noted, there is still the matter of the Tianhe-2A system. The Tianhe-2 upgrade, which was to go forward with Feiteng processors after a U.S. embargo derailed the Knights Landing refresh, has not yet materialized. Signs now point to Tianhe-2A being NUDT’s exascale prototype, one of three exascale contenders in China (along with the Sugon and Wuxi Supercomputing Center efforts). It is speculated that the next Tianhe will employ the Feiteng FT-2000/64 that Phytium Technologies introduced at the 2016 Hotchips conference. The FT-2000/64 is a 64-core ARM processor with a stated 512 gigaflops peak performance at a frequency of 2.0 GHz in a 100 watt power envelope (max).
Splitting the Top500 Pie
While the U.S. has lost supremacy at the peak, it counts five systems within the top ten, still more than any other country. The U.S. leads total system share as well with 169 machines. China is a close second with 160. Recall the U.S. and China were tied with 171 systems each six months ago, but other countries have assumed some of that share, notably Japan and the UK. Japan is now third with 33 supercomputers up from 27 in November. Germany ranks fourth with 28, down from 31. France and the UK are tied for fifth with 17 systems each, with France dropping three systems and the UK adding four.
Shifting the perspective to aggregate performance share, maintains the ordering: U.S. (33.8 percent), China (32 percent), Japan (6.6 percent), Germany (5.6 percent), France (3.4 percent), United Kingdom (3.4).
Looking at the vendor landscape, Hewlett Packard Enterprise (HPE) asserts itself as the number one vendor by system volume with 143, picking up 25 systems in the SGI acquisition, finalized last November. Lenovo is second with 88 systems, followed by Cray (57 systems), Sugon (46) and IBM (27). On the previous list iteration, it was HPE (112 systems), Lenovo (92 systems), Cray (56 systems), Sugon (47) and IBM (with 33). There was only one new IBM system on today’s listing.

When it comes to total list performance share, Cray maintains its lead at 21.4 percent, a skosh up from 21.3 percent six months back. Bolstered by its SGI acquisition, HPE comes back to a solid second place with 16.6 percent up 9.8 percent. With the strong showing of the combined HPE+SGI installs, Sunway TaihuLight developer NRCPC drops to third with 12.5 percent of the total installed performance (down from 13.8). Lenovo is next (9.3 percent, up from 8.8 percent), then IBM (7.5 percent, down from 8.8 percent).
The aggregate performance of all 500 computers on the 49th list stands at 749 petaflops, compared to 672 petaflops six months ago and 567 petaflops one year ago. This 32 percent annual growth rate is far below historical trends, which prior to 2008 averaged about 90 percent per year and more recently averaged around 55 percent per year. It’s a trend that shows no signs of reversal, according to the Top500 authors.

The aggregate performance of the top ten machines is 235.9 petaflops up from 226 petaflops owed solely to the Piz Daint upgrade. 21 systems have joined the petaflops club, bringing total membership to 138 from 117 six months ago. The admission point for the TOP100 is currently 1.21 petaflops up from 1.07 petaflops. The bar for entry onto the list has been raised to 432.2 Linpack teraflops compared to 349.3 teraflops on the last list.
Other notable trends observed by Top500 authors:
-
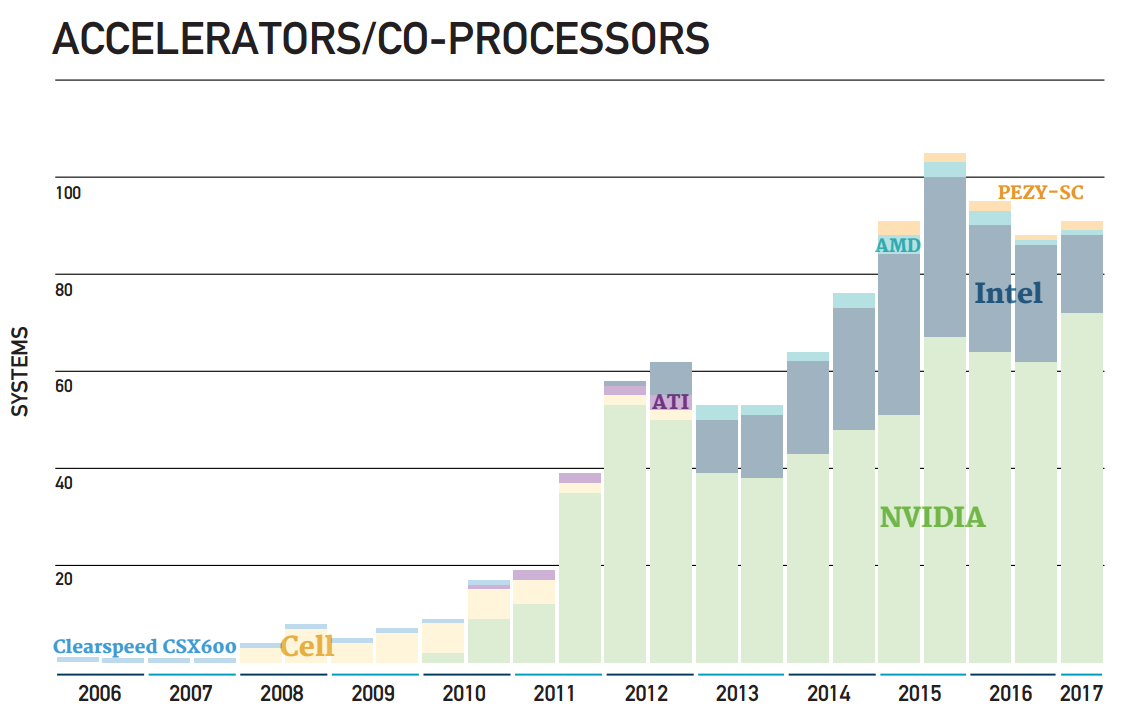
Accelerator/Co-processor trends through June 2017 (Source: Top500) A total of 91 systems on the list are using accelerator/co-processor technology, up from 86 on November 2016. 71 of these use NVIDIA chips, 14 systems with Intel Xeon Phi technology (as Co-Processors), one uses ATI Radeon, and two are using PEZY technology. Three systems use a combination of Nvidia and Intel Xeon Phi accelerators/co-processors. An additional 13 Systems now use Xeon Phi as the main processing unit.
- The average number of accelerator cores for these 91 systems is 115,000 cores/system.
- Intel continues to provide the processors for the largest share (92.8 percent) of TOP500 systems.
- Ninety-three (93.0) percent of the systems use processors with eight or more cores, sixty-eight (68.6) percent use twelve or more cores, and twenty-seven (27.2) percent twelve or more cores.
- Gigabit Ethernet is now at 207 systems (unchanged), in large part thanks to 194 systems now using 10G interfaces. InfiniBand technology is now found on 178 systems, down from 187 systems, and is the second most-used internal system interconnect technology.
- Intel Omni-Path technology which made its first appearance one year ago with 8 systems is now at 38 systems up from 28 system six month ago.
Also noteworthy, the Top500 list now incorporates the HPCG benchmark results “to provide a more balanced look at performance,” according to the list editors. They further report that “the fastest system on the HPCG benchmark is Fujitsu’s K computer which is ranked #8 in the overall Top500. It is followed closely by Tianhe-2 which is also No. 2 on the Top500.” This lineup is unchanged since the November HPCG ranking results.
Highlights from the Green500
The new list has an interesting tale to tell when it comes to energy efficiency metrics. Japan captured the top four spots of the Green500 with four new systems and the upgraded Swiss Piz Daint has the fifth spot. The fact that all five of these systems employ Tesla P100 GPUs speaks well for Nvidia, which also claims the seventh through fourteenth Green500 spots.
At the top of the green ranking, touting 14.110 gigaflops/watt, is the new TSUBAME 3.0, a modified HPC ICE XA machine, designed by Tokyo Tech and HPE. The system earned a 61st place spot on the TOP500 with a 1.998-petaflop Linpack run. The new Green500 record holder bests the previous record set by Nvidia’s internal Saturn V supercomputer six months ago (8.17 gigaflops/watt) by 72.7 percent.
The second-place Green500 system is “kukai,” built by Exascaler and installed at the Yahoo Japan Corporation. It achieves 14.045 gigaflops/watt, a mere 0.3 percent behind TSUBAME 3.0. It’s Top500 ranking is 466. Coming in at number three is the AIST AI Cloud system at the National Institute of Advanced Industrial Science and Technology, Japan. The NEC machine achieves 12.681 gigaflops/watt and is ranked number 148 on the Top500. The fourth place Green500 system is the Fujitsu-made RAIDEN GPU system, installed at RIKEN’s Center for Advanced Intelligence Project. It accomplished 10.603 gigaflops/watt and sits at number 306 on the Top500 line-up. The Dell Wilkes-2 machine installed at the University of Cambridge is in fifth place with 10.428 gigaflops/watt. Its Top500 ranking is 100.
Piz Daint, the sixth-ranked supercomputer on the Green500, achieved 10.398 gigaflops/watt. As a number three system, this is quite the accomplishment, as the latest energy-efficiency technologies don’t always scale well or make it to the top of the list due to long development cycles. The fact that Piz Daint is the most energy-efficient supercomputer within the top 50 fastest supercomputers speaks to that point.
In seventh position is “Gyoukou,” the Exascalar ZettaScaler-1.6 system at the Japan Agency for Marine-Earth Science and Technology with 10.226 gigaflops/watt. Relying on PEZY-SC2 accelerators, Gyoukou is the highest ranking non-GPU system on the Green500 list.
The TOP500 and Green500 awards will be presented by Top500 co-author Horst D. Simon, deputy director of Lawrence Berkeley National Laboratory, at 10:30 am today in Frankfurt. We expect lots more analysis to come out of the Top500 and Green500 program tracks. We will report back on these and other benchmarking results presented at ISC 2017. If you have any insights or comments to share, please catch me by email or in-person at the show.