 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
A new Top500 champ was unveiled today. Supercomputer Fugaku, the pride of Japan and the namesake of Mount Fuji, vaulted to the top of the 55th edition of the Top500 list with 415.5 Linpack petaflops, marking a win for system builder Fujitsu, for Arm-based supercomputing and for the fight against the COVID-19 pandemic in which Fugaku is already engaged. In reduced precision, measured via the new HPL-AI benchmark, Fugaku achieved a record 1.4 exaflops. The Fujitsu Arm system is installed at RIKEN Center for Computational Science (R-CCS) in Kobe, Japan.
A decade in the making, Fugaku was developed by RIKEN in close collaboration with Fujitsu and the application community with funding from MEXT. At the centerpiece is a new processor, Fujitsu’s 48-core Arm A64FX SoC. Riken’s Top500 run was performed with 396 racks, comprising 152,064 A64FX nodes, which is approximately 95.6 percent of the entire (158,976-node) system. With nearly 7.3 million Arm cores running at 2.2GHz, Fugaku achieved a double-precision Linpack performance of 415.53 petaflops out of 513.98 theoretical petaflops, delivering a computing efficiency of 80.87 percent.
An in-depth report from Top500 co-author Jack Dongarra provides these technical details:
The Fugaku system is built on the A64FX ARM v8.2-A, which uses Scalable Vector Extension (SVE) instructions and a 512-bit implementation. The Fugaku system adds the following Fujitsu extensions: hardware barrier, sector cache, prefetch, and the 48/52 core CPU. It is optimized for high-performance computing (HPC) with an extremely high bandwidth 3D stacked memory, 4x 8 GB HBM with 1024 GB/s, on-die Tofu-D network BW (~400 Gbps), high SVE FLOP/s (3.072 TFLOP/s), and various AI support (FP16, INT8, etc.). The A64FX processor provides for general purpose Linux, Windows, and other cloud systems.
Fugaku provides 4.85 petabytes of total memory with an aggregate 163 petabytes-per-second of memory bandwidth. The Tofu-D 6D Torus network delivers 6.49 petabytes-per-second injection bandwidth. The storage system consists of three layers: 15.9 petabytes of NVMe, a Lustre-based global file system, and cloud storage services that are in preparation. The installation occupies 1,920 square meters of floor space (equivalent to four basketball courts) and operates within a 30MW power envelope.
“We have a brand new processor,” said Fugaku project lead Satoshi Matsuoka, director of R-CCS, in today’s live-streamed Top500 briefing, hosted as part of the ISC 2020 Digital proceedings. “It’s an Arm instruction set, but is a brand new design by Fujitsu and RIKEN. [As a general-purpose CPU], it runs the same Arm code as a smartphone, it will run Red Hat Linux out of the box, [and] it will run Windows. It will run PowerPoint, even, but it’s also built to accommodate very large bandwidth, which is very important to sustain the speed up of the applications.”

“You can think of Fugaku as putting 20 million smartphones in a single room, or equivalently 300,000 standard servers in a single room,” said Matsuoka, highlighting the scale of the system. “And these by coincidence, are about the same number as the annual shipment of respective units in Japan. So if you have two Fugakus basically, you can pretty much fill the so called edge-to-cloud compute requirements for the entire country of Japan.”
The cost to build Fugaku was about one billion dollars, on par with what is projected for the U.S. exascale machines. The total includes “significant R&D cost & the DC upgrade cost,” Matsuoka indicated in a Tweet, adding “it would have cost 3 times as much if we had used off-the-shelf CPUs.”
Fugaku demonstrated more than 2.8 times the performance of the previous list leader Summit (ORNL), benchmarked at 148.6 petaflops (and now in second place). The last time Japan clinched the top spot of the list was in November 2011, with the launch of the K computer, which held its position for six months before being supplanted by Sequoia, an IBM BlueGene/Q system installed at the National Nuclear Security Administration.

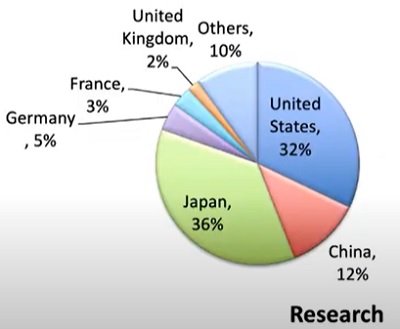
Fugaku contributes 18.7 percent of aggregate list flops, setting a new record. The machine’s magnitude shakes up the list dynamics, boosting Fujitsu into first place by performance share, and raising Japan into third place by performance share (behind the U.S., which still leads, and China). Segmenting the list by top 100 research systems, Japan zooms into first place (with 36 percent), and the Arm architecture, which only entered the list a year-and-a-half ago, now dominates with a 31 percent performance share.
There are just three other Arm systems on the Top500: the A64FX Fugaku prototype at Fujitsu (#205); the new Fujitsu PRIMEHPC FX1000 A64FX system, Flow, at Japan’s Nagoya University (#37); and Astra, the Marvell/Cavium ThunderX2 installation at Sandia (#245), recognized as the world’s first petascale Arm system in November 2018.

Fugaku also broke records on the HPCG (13.4 petaflops), the Graph500 (70,980 gigaTEPS) and the HPL-AI (1.42 exaflops), coming in first in all three. Remarking on the system’s placement on the new AI-geared HPL-AI benchmark, Top500 co-author Erich Strohmaier observed, “That’s non trivial, because to satisfy the requirements of the benchmark, you cannot just compute only in 16-bit, you actually have to make up for the lost precision at the end of the benchmark to get back to the full 64-bit precision in the results. But that penalty was easily overcome by the more than two exaflops of peak performance Fugaku has in 16-bit operations.”
Fugaku is also one of the most energy-efficient machines on the Top500, joining its “mini-me” A64FX prototype, in the top ten of the Green500. With its 28.33 MW Linpack run, Fugaku delivered 14.7 gigaflops-per-watt, earning it a ninth-place finish on the Green500 list. The smaller A64FX prototype (#205 on the Top500), installed at Fujitsu’s Numazu plant, holds the fourth spot on the Green500 with 16.87 gigaflops-per-watt. Green500 glory goes to newcomer Preferred Networks, which achieved 21.1 gigaflops-per-watt, with its MN-3 system (#394 on the Top500) that combines Intel Xeon and specialized AI processors.
The two Arm systems — Fugaku and its prototype — are notable as the only systems in the top 20 of the Green500 that do not make use of GPUs or specialized accelerators. “Our power efficiency is pretty much in the range of GPUs or the latest specialized accelerators while being a general purpose CPU,” said Matsuoka, adding that the Fugaku processor is three times more powerful and also three times more power efficient [for Riken’s target workloads] compared to traditional CPUs, on account of extensive tuning.
Matsuoka reported that Fugaku was put into production almost a year ahead of schedule to combat COVID-19 (see additional HPCwire coverage here). For medical pharma applications that assess the effectiveness of drug targets, Fugaku is showing 100X speedups over K, according to Matsuoka. Efforts are also being directed to societal and epidemiological applications to simulate how infections spread and the effectiveness of contact tracing. “The latter has tremendous potential and is already helping to mitigate the virus infections at macroscale,” Matsuoka added.
Asked about potential plans to grow Fugaku across the 64-bit precision exascale threshold, Matsuoka responded wryly, “If we have the money, obviously, anything is possible.” But he emphasized the goal of the project was never about peak performance.
“Our design metric was basically to accelerate existing applications by two orders of magnitude,” he said. “In some sense, the excellence is in the variety of the benchmarks, not just the Top500, but across the board, HPCG, HPL-AI, Top500, and so forth — showing basically the result of our efforts to accelerate the applications. So the outcome is applications describing the benchmarks and not the other way around. So, we’re very satisfied with the result. If we make progress it’ll only be because we will have made progress in the application speedup by which we could be achieving exaflop.”
Matsuoka added that the software ecosystem was the priority in the development of Fugaku. “That’s why we went to the Arm ecosystem from Spark, which was the K’s ecosystem and was not very, let’s say, proliferating,” he said. “The decision to go with Arm has led to a variety of collaborations with various institutions worldwide, with the DOE, with the European institutions, and so forth. Software is the key. That’s the heart of the computing system, and we’re making every effort to enrich the Arm ecosystem so that it’ll be one of the dominant systems in the HPC community.”
Feature image courtesy Riken.


























































{kind=link}