Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
NVIDIA is excited to announce the release of the stdexec library on GitHub and in the 22.11 release of the NVIDIA HPC Software Development Kit. The stdexec library is a proof-of-concept implementation of the Sender model (or Senders) for asynchronous computing—expected to become part of the C++ Standard in C++26. Senders help you separate the logic of your algorithm – the work you actually care about – from the details of where and how it gets executed. Unlike the C++17 parallel algorithms, with Senders you can chain multiple asynchronous computations (like GPU kernels) without unnecessary synchronization.
The upshot is that you can write your program logic once and then decide how to execute it, whether on a single thread, a thread pool, or a GPU, without changing the program logic. It is also possible to target multi-GPU systems or heterogeneous multi-node compute clusters.
The design of stdexec is the product of an industry collaboration between NVIDIA and other members of the C++ Standardization Committee. It gives C++ an extensible, asynchronous programming model, a suite of generic algorithms that capture common async patterns, and hooks that let you say precisely where and how you want your work to execute. The Sender model is slated for standardization with C++26, but stdexec allows you to experiment with it today.
Asynchronous vs. Synchronous Programming
In the previous two posts (Leveraging Standards-Based Parallel Programming in HPC Applications and Why Standards-Based Parallel Programming Should be in Your HPC Toolbox), we discussed the benefits of standards-based parallel programming in the form of the C++17 standard parallel algorithms. The standard parallel algorithms provide an easy way to accelerate your application because they are a drop-in replacement for the classic standard algorithms.
Like the classic standard algorithms, the standard parallel algorithms are synchronous — they block until their work is done. They don’t let you leverage the inherent asynchrony of today’s hardware to hide latencies or to overlap communication and computation. We would need a standard asynchronous programming model and asynchronous parallel algorithms for that, things C++ lacks today.
The importance of asynchrony in HPC is illustrated in the example below, which implements a simulation of Maxwell’s Equations using the C++17 standard parallel algorithms. Maxwell’s equations model propagation of electromagnetic waves. We use the finite-difference time-domain method (FDTD), which requires the computational domain to be represented as a grid of cells. The simulation requires two passes over the grid per iteration to update the magnetic and electric fields. Since the computation in each cell is independent within one iteration, we can parallelize cell updates using the C++17 standard parallel algorithms.
for (int step = 0; step < n_steps; step++) { std::for_each(par_unseq, cells_begin, cells_end, update_h); std::for_each(par_unseq, cells_begin, cells_end, update_e); } |
The straightforward CUDA C++ implementation is similar:
for (int step = 0; step < n_steps; step++) { kernel<<<grid_blocks, block_threads, 0, stream>>>(n_cells, update_h); kernel<<<grid_blocks, block_threads, 0, stream>>>(n_cells, update_e); } cudaStreamSynchronize(stream); |
Although both of these implementations run on the GPU, the CUDA implementation performs better than the one that’s based on the standard parallel algorithms. That’s because each call to std::for_each() is synchronous, and the latency of kernel launches is not overlapped. We profiled both implementations, and Figure 1 shows the execution timeline. It shows that the CUDA implementation is faster because the inherent asynchrony of kernel launches allows overlapping launching the kernels for the next iteration with execution of the current iteration—effectively hiding the kernel launch latency. In contrast, the std::for_each implementation must synchronize after every invocation and prevents any opportunity for overlap.

To illustrate the importance of exploiting asynchrony, Figure 2 compares the performance of the std::for_each implementation relative to the CUDA implementation across a variety of problem sizes.
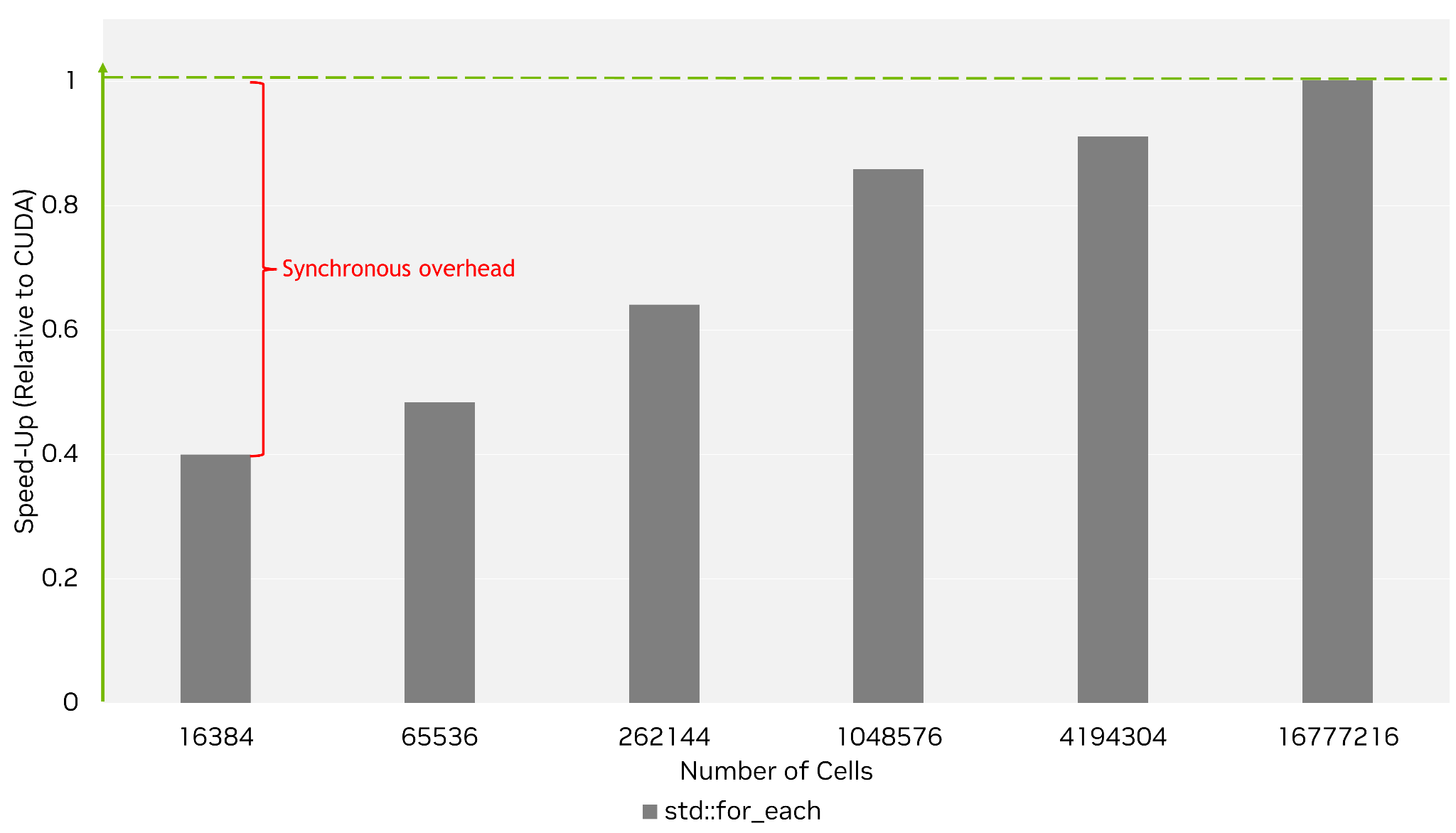
As we can see from Figure 2, the std::for_each implementation suffers at smaller problem sizes where kernel launch latency is large relative to kernel execution time. As discussed above, the CUDA implementation is effective at hiding this latency by overlapping it with useful work. In contrast, the synchronous std::for_each implementation cannot hide this latency and therefore it contributes to the overall execution time. As the problem size increases, kernel launch latency becomes trivial compared to kernel execution time and the performance difference eventually disappears.
While the CUDA C++ implementation is faster, it is platform specific. In order to achieve the same results in Standard C++, we need a new programming model that allows us to exploit asynchrony. To this end, the Sender model was developed as a new way to describe and execute asynchronous work in Standard C++. Senders are expected to become part of the C++ Standard in C++26, but NVIDIA already has a proof-of-concept implementation provided by the stdexec library.
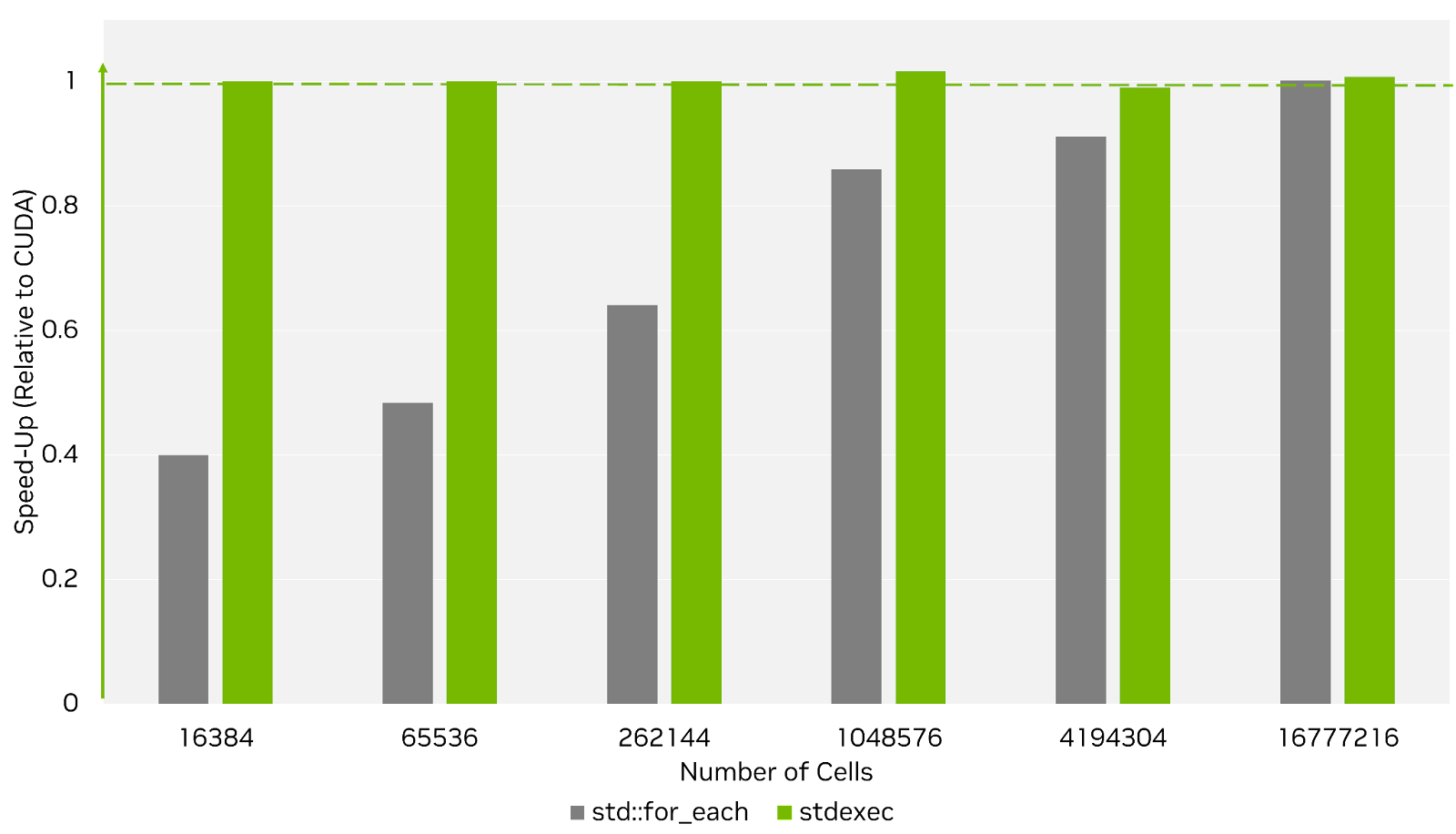
To show the benefits of Senders, Figure 3 shows the performance of the Maxwell’s Equations example using stdexec compared to the CUDA and std::for_each implementations from earlier. Like the parallel algorithms, it can match raw CUDA performance for larger problem sizes, but it also performs well for smaller problem sizes, when latency dominates. This is because the asynchronous Sender model effectively hides kernel launch latency by overlapping it with execution of another kernel. All of the Maxwell’s Equation example programs can be found in the stdexec repository on GitHub. Keep reading to find out more about Senders and stdexec.
A Standard C++ Model for Asynchrony
The results above show why it is important for Standard C++ to have a way to efficiently chain together asynchronous work. The std::execution, or Senders, proposal solves this problem by providing a programming model baked into the language for describing and executing asynchronous operations. The stdexec library introduced above is the NVIDIA proof-of-concept implementation of the Sender model.
The Sender model has two key concepts: a Scheduler, which describes where and how to perform a computation; and a Sender, which is a description of an asynchronous computation. Senders can be chained together to build a pipeline where a Sender produces a value and then sends its value to the next Sender in the chain. The Sender model provides a set of algorithms to create and compose Senders to build completely asynchronous pipelines.
For example, the following code shows a Sender pipeline that implements the Maxwell’s Equations demo from above.
auto compute = stdexec::just() // (1) | exec::on( scheduler, // (2) nvexec::repeat_n( n_steps, // (3) stdexec::bulk( n_cells, update_h ) // (4) | stdexec::bulk( n_cells, update_e ) ) ); stdexec::sync_wait( std::move(compute) ); // (5) |
First, you may notice we use several different namespaces. This is to help differentiate what is part of the formal std::execution proposal from the other things stdexec provides. The stdexec:: namespace is for anything that is already part of the std::execution proposal. The exec:: namespace is for generic utilities not yet part of the proposal, but will be considered for future proposals. Finally, nvexec:: is for NVIDIA specific schedulers and algorithms.
The pipeline starts with the stdexec::just() Sender (1), which represents an empty computation that gives us an entry point upon which we can chain additional work using the pipe operator (operator|), like the Unix shell.
Next in our chain, we use exec::on() (2) to transition to a new scheduler and continue executing the pipeline there. The on() algorithm takes a scheduler as its first argument to say where the work should happen. The second argument is the work chain to execute. After the pipeline finishes, on() will transition automatically back to the starting execution context – in this case, the thread that called sync_wait() and is waiting for the pipeline to finish.
The nvexec::repeat_n() algorithm (3) repeats the execution of the work chain passed to it a fixed number of times.
Finally, the stdexec::bulk() algorithm (4) is similar to std::for_each() – it invokes the provided function with every index in [0, n_cells). If the scheduler supports parallelism, each invocation of the function may execute in parallel.
No work has started at this point; the variable compute above is just a description. To submit the entire pipeline and wait for its completion we use the sync_wait() algorithm (5).
Sender expressions like compute above are high-level descriptions of work that capture a computation’s structure and semantics; they are declarative. The scheduler used to run them controls how that description gets translated into the actual instructions that execute that work. Pass a CUDA scheduler, get CUDA execution. Pass a CPU-based thread-pool scheduler and the work is executed on the thread-pool. The translation happens at compile-time so you get native performance.
Application Performance Portability
In the example above, you’ll notice the scheduler is specified in just one place. In the performance results we showed above in Figure 3, we provided a scheduler that executes on the GPU using CUDA. However, we’re free to use other schedulers to execute elsewhere by changing a single line of code. Running this simulation on the CPU is as simple as passing a different scheduler.
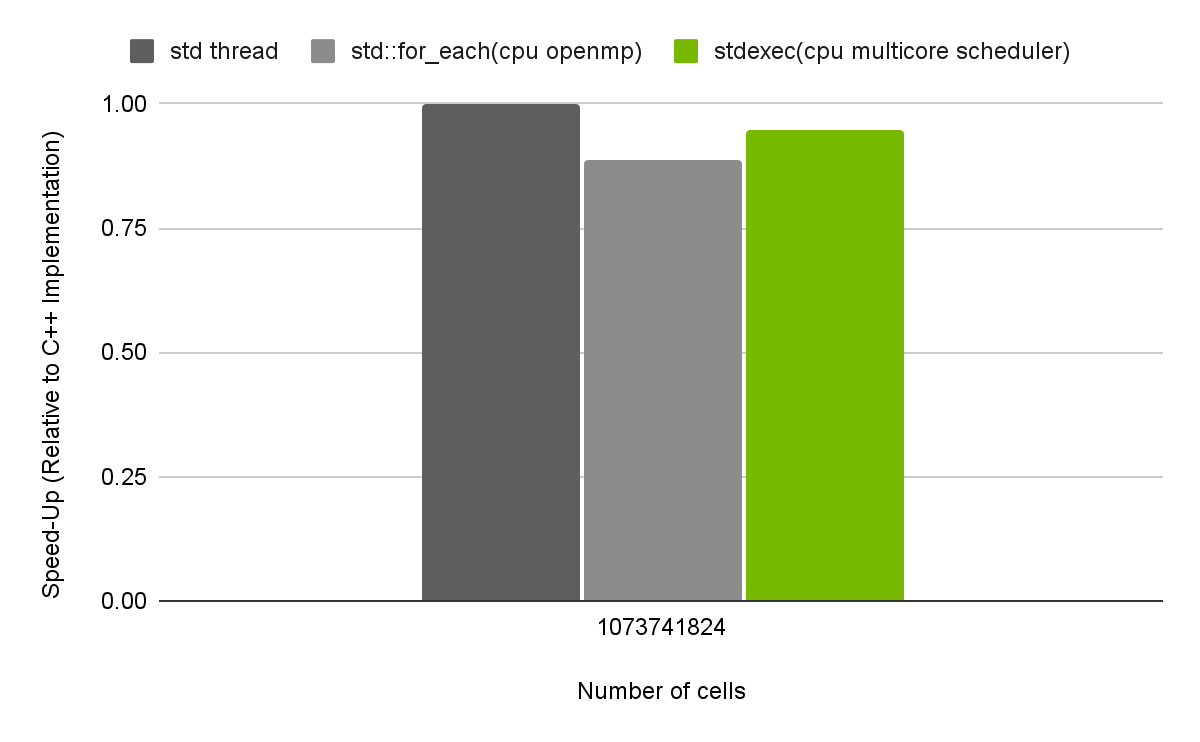
For example, Figure 4 below shows the performance of the stdexec pipeline described above using a CPU thread pool scheduler. We compare its performance relative to two other CPU-based solutions: a parallel std::for_each() with OpenMP, and a highly-tuned implementation using raw std::threads. Here we see the solution with raw threads is fastest, closely followed by stdexec with a thread pool, and std::for_each with OpenMP not far behind.
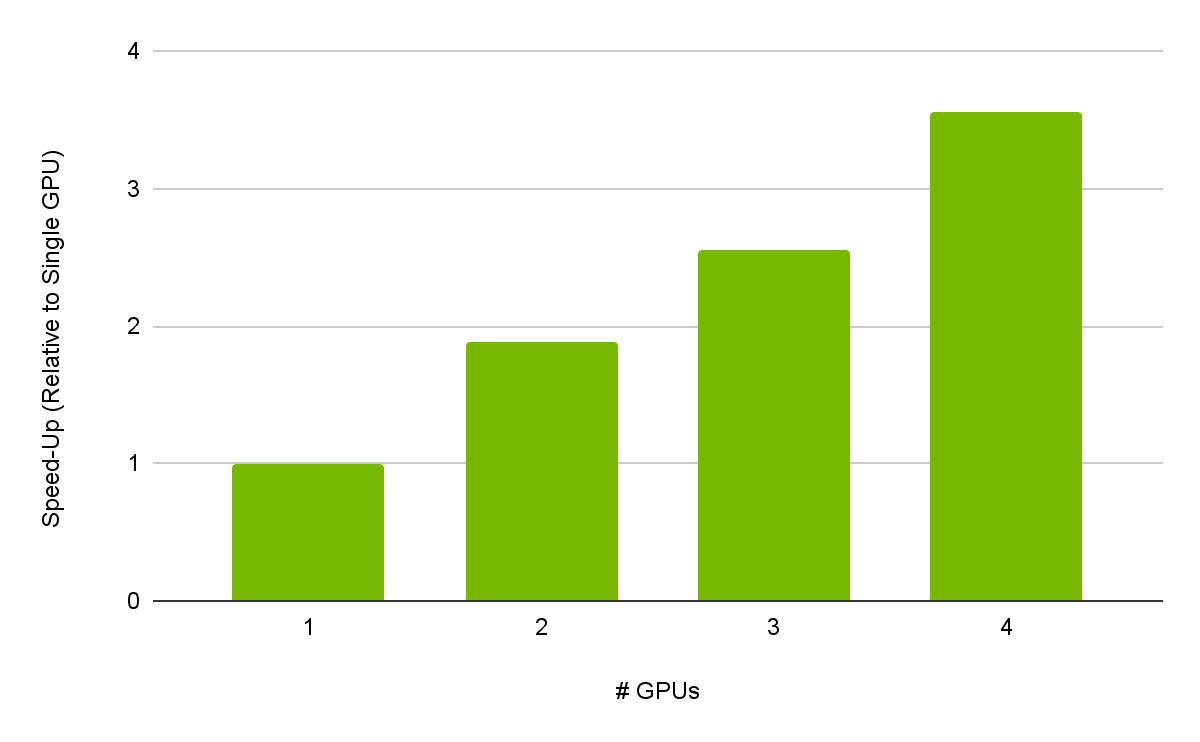
The flexibility of the Sender model also enables us to trivially scale to multiple GPUs. In stdexec we also provide a multi-GPU scheduler to take advantage of a system with multiple GPUs. Our preliminary results show the multi-GPU scheduler has 90% strong scaling with four GPUs, as shown in Figure 5.
Fine-Grained Execution Context Control
It’s common in HPC applications for your work to cascade from one execution context to another to match the workload with the computing resource best suited to it. Senders make it simple to define pipelines that span multiple execution contexts.
For example, consider the code below that uses stdexec for a distributed, multi-node implementation of the Maxwell’s Equation example using MPI for communication. We use a straightforward 2D partitioning of the matrix where each rank operates on a 2D tile of the matrix. It first updates the magnetic field within that tile, then uses MPI to send the new values to the other ranks before doing the same thing for the electric field.
nvexec::stream_scheduler gpu = /*...*/; auto work = stdexec::just() | exec::on( gpu, ex::bulk(accessor.own_cells(), update_h) ) | stdexec::then( mpi_exchange_hx ) | exec::on( gpu, ex::bulk(accessor.own_cells(), update_e) ) | stdexec::then( mpi_exchange_ez ); stdexec::sync_wait( std::move( work ) ); |
Here, we use the exec::on() algorithm to transition to the GPU to perform the computation and back to the CPU to initiate communication in the stdexec::then(). This algorithm calls the specified function using the values produced by the previous operation as arguments. Since we did not specify a scheduler for the MPI communication performed in stdexec::then(), it is implicitly performed on the thread that invoked sync_wait().
The distributed algorithm above works, but it needlessly serializes operations that can be done in parallel; namely, computation and communication. Each tile has neighbors that are processed on other ranks. Those other ranks don’t need the full results of this rank, they only need to know the values of the elements at the edges of the tile. We can hide latency by having each rank compute the updated values at the edges of its tile and then sending those results while the inner elements of the tile are updated. We would do this iteratively, first for the magnetic field and then for the electric.
The code below shows how we can modify the example above to overlap the communication of the boundary elements with the computation of interior elements. It uses stdexec::when_all() which takes an arbitrary number of Senders and executes them concurrently. In this example, there are two concurrent operations:
- Processing interior elements
- Processing and then exchanging the boundary elements
Both of these operations start at the same time, but the boundary cells are processed on a scheduler with a higher CUDA priority to ensure overlap. When the boundary elements are finished processing, it immediately sends the updated boundary elements to neighbors while processing interior cells may still be ongoing.
auto compute_h = stdexec::when_all( stdexec::just() | exec::on(gpu, ex::bulk(interior_cells, // (1) interior_h_update)), stdexec::just() | exec::on(gpu_with_priority, // (2) stdexec::bulk(border_cells, border_h_update)) | stdexec::then(exchange_hx); |
Using when_all() to execute these two operations concurrently allows us to overlap the MPI communication inside exchange_hx with the computation of interior cells. This delivers up to 50% speedup compared to the example above. As shown in Figure 6 below, communication overlapping also provides better scaling.
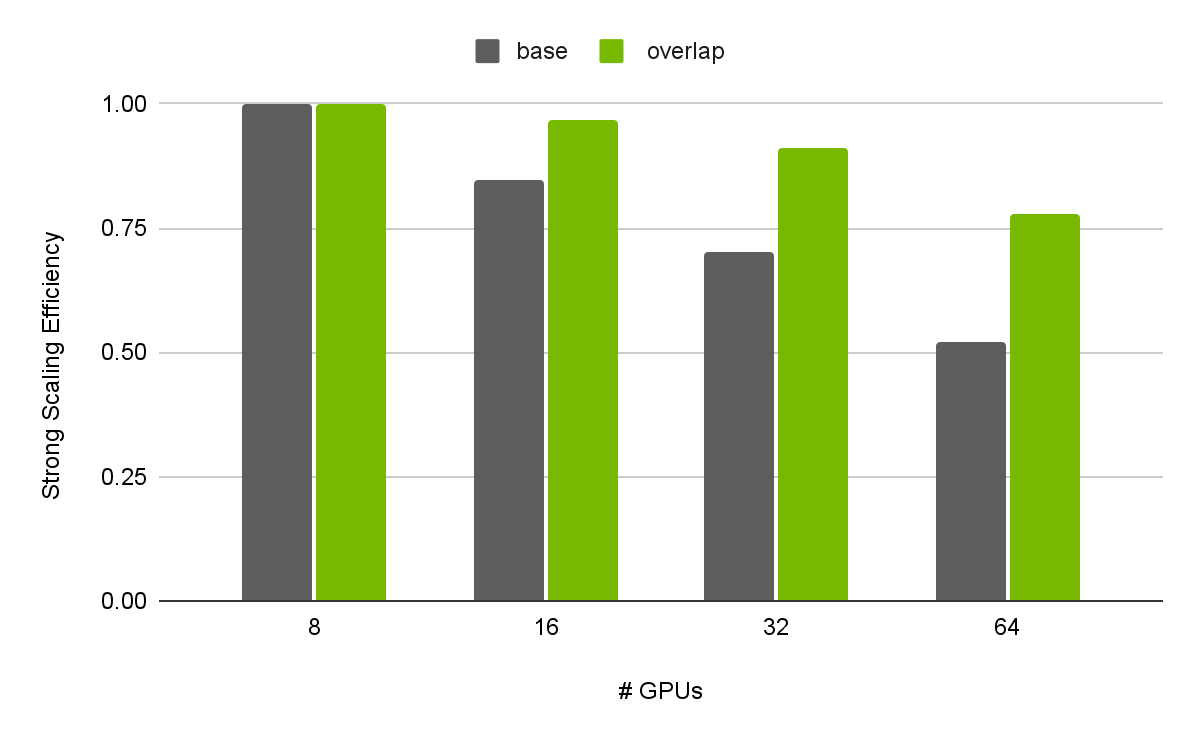
To illustrate the difference in the strong scaling efficiency we selected a small problem size (three GB/GPU) and started with a single node (eight GPUs per node). For larger problem sizes (40 GB/GPU when launched on a single node), the efficiency of the overlapping version is 93%. It’s important to note that no low-level synchronization primitives such as stream synchronization or thread management were used in the example.
How to Get Started with stdexec
If you want to try stdexec in your application, you can download the NVIDIA HPC SDK 22.11 for free today and experiment with our various compilers and tools. Alternatively, if you want to stay up-to-date with the latest developments, stdexec is actively maintained on GitHub. The NVIDIA HPC SDK nvc++ compiler and stdexec are also available on Compiler Explorer to enable you to easily try it out.
Happy computing.
About Eric Niebler
 Eric Niebler is a Distinguished Engineer and Developer Lead for the CUDA C++ Core Libraries Team at NVIDIA. He’s passionate about improving C++ programmer productivity and software quality with the use of great libraries. He specializes in generic library design and contributed std::ranges to the C++20 Standard Library. For the past few years, he has been working to give C++ a standard async programming model that accommodates massive parallelism and exotic hardware.
Eric Niebler is a Distinguished Engineer and Developer Lead for the CUDA C++ Core Libraries Team at NVIDIA. He’s passionate about improving C++ programmer productivity and software quality with the use of great libraries. He specializes in generic library design and contributed std::ranges to the C++20 Standard Library. For the past few years, he has been working to give C++ a standard async programming model that accommodates massive parallelism and exotic hardware.
About Georgy Evtushenko
 Georgy is a member of the CUDA C++ Core Libraries Team at NVIDIA. His core interest has been high-performance computing ever since the beginning of his career. After developing various production HPC applications, his interest turned into delivering Speed-Of-Light performance through high-level C++ abstractions.
Georgy is a member of the CUDA C++ Core Libraries Team at NVIDIA. His core interest has been high-performance computing ever since the beginning of his career. After developing various production HPC applications, his interest turned into delivering Speed-Of-Light performance through high-level C++ abstractions.
About Jeff Larkin
 Jeff is a Principal HPC Application Architect in the NVIDIA HPC Software team. He is passionate about the advancement and adoption of parallel programming models for high-performance computing. He was previously a member of the NVIDIA Developer Technology group, specializing in performance analysis and optimization of high performance computing applications. Jeff is also the chair of the OpenACC technical committee and has worked in both the OpenACC and OpenMP standards bodies. Before joining NVIDIA, Jeff worked in the Cray Supercomputing Center of Excellence, located at Oak Ridge National Laboratory.
Jeff is a Principal HPC Application Architect in the NVIDIA HPC Software team. He is passionate about the advancement and adoption of parallel programming models for high-performance computing. He was previously a member of the NVIDIA Developer Technology group, specializing in performance analysis and optimization of high performance computing applications. Jeff is also the chair of the OpenACC technical committee and has worked in both the OpenACC and OpenMP standards bodies. Before joining NVIDIA, Jeff worked in the Cray Supercomputing Center of Excellence, located at Oak Ridge National Laboratory.