 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
IBM today introduced its next generation Power10 microprocessor, a 7nm device manufactured by Samsung. The chip features a new microarchitecture, broad new memory support, PCIe Gen 5 connectivity, hardware enabled security, impressive energy efficiency, and a host of other improvements. Unveiled at the annual Hot Chips conference (virtual this year) Power10 won’t turn up in IBM systems until this time next year. IBM didn’t disclose when the chip would be available to other systems makers.
IBM says Power10 offers a ~3x performance gain and ~2.6x core efficiency gain over Power9. No benchmarks against non-IBM chips were presented. Power9, of course, was introduced in 2017 and manufactured by Global Foundries on a 14nm process. While the move to a 7nm process provides many of Power10’s gains, there are also significant new features, not least what IBM calls Inception Memory that allows Power10 to access up to “multi petabytes” of pooled memory from diverse sources.
 “You’re able to kind of trick a system into thinking that memory in another system belongs to this system. It isn’t like traditional [techniques] and doing an RDMA over InfiniBand to get access to people’s memory. This is programs running on my computer [that] can do load-store-access directly, coherently,” said William Starke, IBM distinguished engineer and a Power10 architect in a pre-briefing. “They use their caches [to] play with memory as if it’s in my system, even if it’s bridged by a cable over to another system. If we’re using short-reach cabling, we can actually do this with only 50-to-100 nanoseconds of additional latency. We’re not talking adding a microsecond or something like you might have over and RDMA.”
“You’re able to kind of trick a system into thinking that memory in another system belongs to this system. It isn’t like traditional [techniques] and doing an RDMA over InfiniBand to get access to people’s memory. This is programs running on my computer [that] can do load-store-access directly, coherently,” said William Starke, IBM distinguished engineer and a Power10 architect in a pre-briefing. “They use their caches [to] play with memory as if it’s in my system, even if it’s bridged by a cable over to another system. If we’re using short-reach cabling, we can actually do this with only 50-to-100 nanoseconds of additional latency. We’re not talking adding a microsecond or something like you might have over and RDMA.”
IBM is promoting Inception as a major achievement.
“HP came out with their big thing a few years ago. They called it The Machine and it was going to be their way of revolutionizing things largely by disaggregating memory. Intel you’ve seen from their charts talking about their Rack Scale architectures [that] they’re evolving toward. Well, this is IBM’s version of this and we have it today, in silicon. We are announcing we are able to take things outside of the system and aggregate the multiple systems together to directly share memory,” said Starke.


Inception is just one of many interesting features of Power10, which has roughly 18 billion transistors. IBM plans to offer two core types – 4 SMT (simultanous multi-threaded) cores and 8 SMT cores; IBM focused on the latter in today’s presentation. There are 16 cores on the chip and on/offchip bandwidth via the OMI interface or PoweAXON (for adding OpenCAPI accelerators) or PCIe5 interface, all of which are shown delivering up to 1 terabyte per sec on IBM’s slides.
CXL interconnect is not supported by Power10, which is perhaps surprising given the increasingly favorable comments about CXL from IBM over the past year.
Starke said as part of a Slack conversation tied to Hot Chips, “Does POWER10 support CXL? No, it does not. IBM created OpenCAPI because we believe in Open, and we have 10+ years of experience in this space that we want to share with the industry. We know that an asymmetric, host-dominant attach is the only way to make these things work across multiple companies. We are encouraged to see the same underpinnings in CXL. It’s open. It’s asymmetric. So it’s built on the right foundations. We are CXL members and we want to bring our know-how into CXL. But right now, CXL is a few years behind OpenCAPI. Until it catches up, we cannot afford to take a step backwards. Right now OpenCAPI provides a great opportunity to get in front of things that will become more mainstream as CXL matures.”
Below is the block diagram of IBM’s new Power10 chip showing major architecture elements.


The process shrink does play role in allowing to IBM to offer two packaging options shown below (slide below).
“We’re offering two versions of the processor module and were able to do this primarily because of the energy efficiency gains,” said Starke. “We’re bringing out a single chip module. There is one Power10 chip and exposing all those high bandwidth interfaces, so very high bandwidth per compute type of characteristics. [O]n the upper right you can see [it]. We build a 16-socket, large system that’s very robustly scalable. We’ve enjoyed success over the last several generations with this type of offering, and Power10 is going to be no different.
“On the bottom you see something a little new. We can basically take two Power10 processor chips and cram them into the same form factor where we used to put just one Power9 processor. We’re taking 1200 square millimeters of silicon and putting it into the same form factor. That’s going to be very valuable in compute-dense, energy-dense, volumetric space-dense cloud configurations, where we can build systems ranging from one to four sockets where those are dual chip module sockets as shown there on the lower right,” he said.
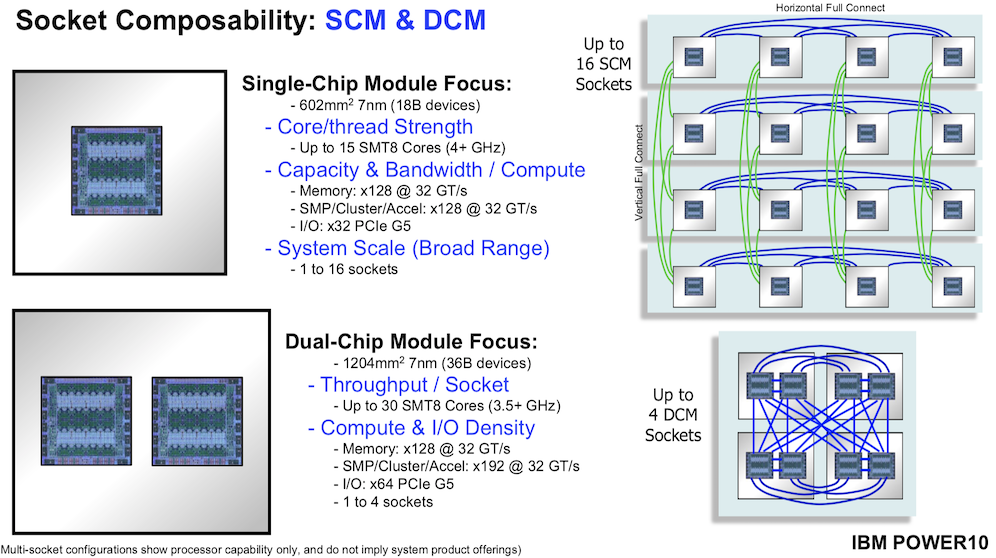
It will be interesting to see what sort of traction the two different offerings gain among non-IBM systems builders as well as hyperscalers. Broadly IBM is positioning Power10 as a strong fit for hybrid cloud, AI, and HPC environments. Hardware and firmware enhancements were made to support security, containerization, and inferencing, with IBM pointedly suggesting Power10 will be able to handle most inferencing workflows as well as GPUs.
Talking about security, Satya Sharma, IBM Fellow and CTO, IBM Cognitive Systems, said “Power10 implements transparent memory encryption, which is memory encryption without any performance degradation. When you do memory encryption in software, it usually leads to performance degradation. Power10 implements transparent hardware memory encryption.”
Sharma cited similar features for containers and acceleration cryptographic standards. IBM’s official announcement says Power10 is designed to deliver hardware-enforced container protection and isolation optimized with the IBM firmware and that Power10 can encrypt data 40 percent faster than Power9.
IBM also reports Power10 delivers a 10x-to-20x advantage over Power9 on inferencing workloads. Memory bandwidth and new instructions helped achieve those gains. One example is a new special purpose-built matrix math accelerator that was tailored for the demands of machine learning and deep learning inference and includes a lot of AI data types.

Focusing for a moment on dense-math-engine microarchitecture, Brian Thompto, distinguished engineer and Power10 designer, noted, “We also focused on algorithms that were hungry for flops, such as the matrix math utilized in deep learning. Every core has built in matrix math acceleration and efficiently performs matrix outer product operations. These operations were optimized across a wide range of data types. Recognizing that various precisions can be best suited for specific machine learning algorithms, we included very broad support: double precision, single precision, two flavors of half-precision doing both IEEE and bfloat16, as well as reduced precision integer 16-, eight-, and four-bit. The result is 64 flops per cycle, double precision, and up to one K flops per cycle of reduced precision per SMT core. These operations were tailor made to be efficient while applying machine learning.
“At the socket level, you get 10 times the performance per socket for double and single-precision, and using reduced precision, bfloat16 sped up to over 15x and int8 inference sped up to over 20x over Power9,” Thompto added.

More broadly, he said, “We have a host of new capabilities in ISA version 3.1. This is the new instruction set architecture that supports Power10 and is contributed to the OpenPOWER Foundation. The new ISA supports 64-bit prefixed instructions in a risk-friendly way. This is in addition to the classic way that we’ve delivered 32-bit instructions for many decades. It opens the door to adding new capabilities such as adding new addressing modes as well as providing rich new opcode space for future expansion.”
Link to Hot Chips: https://www.hotchips.org
Link to IBM Blog: https://newsroom.ibm.com/Stephen-Leonard-POWER10
























































