 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
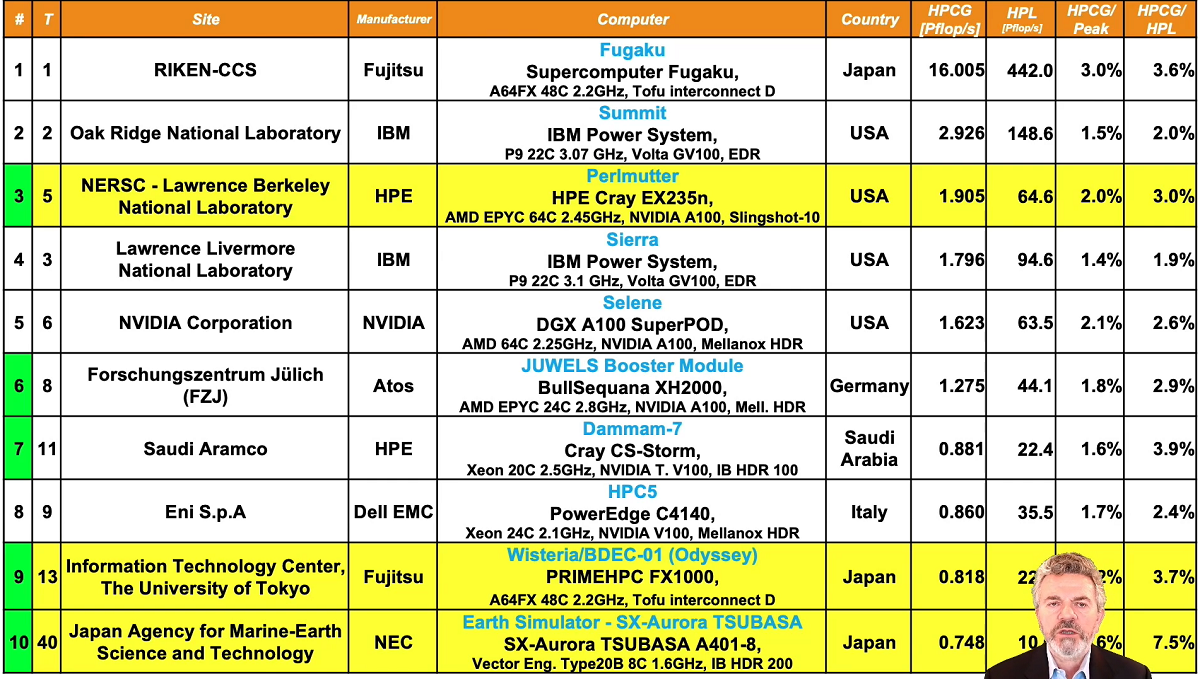
The 57th Top500, revealed today from the ISC 2021 digital event, showcases many of the same systems as the previous edition, with Fugaku holding its significant lead and only one new entrant in the top 10 cohort: the Perlmutter system at the DOE Lawrence Berkeley National Laboratory enters the list at number five with 64.59 Linpack petaflops. Perlmutter is the largest Nvidia A100 GPU system and the largest HPE Cray EX system (publicly) deployed to date based on the architecture formerly known as “Shasta.”
Japan’s Fugaku system retains its crown with 442 Linpack petaflops. Installed at Riken for over a year, the Fujitsu Arm-based machine has been instrumental in the fight against COVID-19. Fugaku also keeps its strong lead on the simultaneously published HPCG, Graph500 and HPL-AI benchmarks.
Summit and Sierra (IBM/Mellanox/Nvidia, United States) remain at number two and three, respectively. Summit at Oak Ridge National Lab claims 148.6 petaflops, while Sierra at Lawrence Livermore National Lab delivers 94.6 petaflops. Sunway TaihuLight (China) holds steady in fourth place with 93 petaflops.

The fifth position has been secured by Perlmutter, installed at Berkeley Lab’s National Energy Research Scientific Computing Center (NERSC). The HPE Cray EX system is powered by AMD Milan CPUs and Nvidia A100 40GB GPUs, connected by HPE’s Slingshot technology. The namesake of Saul Perlmutter, the system delivered 65.69 Linpack rMax petaflops out of a potential peak (rPeak) of 93.75 petaflops, which comes out to 70 percent Linpack efficiency. Note that the rPeak is different from the system’s marketing peak of about 62 double-precision standard IEEE petaflops (the GPUs alone provide 59.6 petaflops); so as with Selene, we see an Nvidia-powered system returning a Linpack score higher than its marketing peak.
Sliding down a notch into sixth position is Nvidia’s Selene system. Selene delivers 63.46 Linpack petaflops out of an rPeak of 79.22 petaflops for an efficiency of 80.1 percent. Selene implements Nvidia’s SuperPod A100 DGX modular architecture with AMD Eypc Rome CPUs and Nvidia’s 80GB A100 GPUs.
The Chinese-built Tianhe-2A falls one spot to number seven with 61.4 Linpack petaflops. Equipped with Intel Xeon chips and custom Matrox-2000 accelerators, Tianhe-2A (aka MilkyWay-2A) entered the list in 2018 at number four. It is installed at the National Super Computer Center in Guangzhou.
In eighth position is the Atos-built JUWELS Booster Module – still the most powerful in Europe with 44.12 Linpack petaflops. Installed at Forschungszentrum Juelich (FZJ) in Germany, the system is powered by AMD Eypc Rome CPUs and Nvidia A100 GPUs.
Rounding out the top ten segment, Dell remains the top academic and top commercial supplier with HPC-5/Eni and Frontera/TACC in ninth and tenth place respectively. The 34.5-petaflops HPC-5 is an Nvidia GPU accelerated machine, while the 23.4-petaflops Frontera is a straight x86 Intel Cascade Lake system. Both systems rely on Mellanox HDR InfiniBand.
Extending our purview to the top 20 segment puts the spotlight on three new entrants to the list. In twelfth position with 22.2 petaflops is ABCI 2.0. Made by Fujitsu, the new system replaces the original ABCI, which was benchmarked in 2018 at 19.9 petaflops.
In the 13th spot is Japan’s Wisteria/BDEC-01 (Odyssey) system with 25.95 Linpack petaflops. Installed at the University of Tokyo, Odyssey was built by Fujitsu, leveraging its A64FX Arm cores.
The 19th-ranked supercomputer with 19.3 petaflops is Saudi Arabia’s Ghawar-1 – an HPE Cray EX system that integrates AMD Epyc Rome CPUs and HPE Slingshot interconnect technology. It was built by HPE for Saudi Aramco.
List Trends
China still leads by number of systems despite a significant drop to 186 systems from 214 machines six months ago and 226 machines one year ago. Geopolitical tensions between the U.S. and China seem to have quelled China’s appetite for Top500 bragging rights. According to trusted sources, two large systems (200-300+ petaflops range) were benchmarked two years ago but not officially placed on the list.
The U.S. has 123 systems on the current list up from 113 machines on the last list. Out of the top 100 systems, the U.S. has the highest share with 33. Japan has the second highest with 19. Next is Germany with 11 systems. China has three systems in the top 100, none of which are new.
Of the 58 new systems on the list, 16 are claimed by the U.S. China had the second most with eight systems, all from Lenovo. Germany is next with seven, then Japan with five.
There are no new IBM systems as the number of IBM systems contracts from nine to eight. Dropping off is Blue Joule, an IBM BlueGene/Q installed at STFC Daresbury Laboratory (UK). The nine-year-old machine was the very last BlueGene on the list and its departure symbolizes the end of an era for an architecture that once ruled the HPC/supercomputing roost.
The Top500 team notes that interconnect usage patterns have not changed much since six months ago. They report: “Ethernet is still used in around half of the systems (245), InfiniBand was around a third of the machines (169), OmniPath interconnects made up less than one-tenth (42), and only one system relied on Myrinet. Custom interconnects accounted for 37 systems, while proprietary networks were found on six systems.”
Although there is a new roadmap for OmniPath under the direction of Cornelis Networks, there were no new Cornelis-OmniPath systems on this list. There is one such system on the list, though; Livermore’s Ruby supercomputer debuted six months ago and uses Cornelis Networks’ OmniPath.
Also noteworthy, HPE’s Slingshot interconnect is now used in seven systems up from one system on the last list (CSCS Alps).
Focusing on the top 100 segment, InfiniBand is still dominant. It is used in 65 of the top 100 systems, inclusive of the Sunway TaihuLight system, which uses a semi-custom version of HDR InfiniBand. That’s up from 61 IB-connected machines last November. OmniPath held steady at 13 installations.
EuroHPC systems now on the list
Four of the eight EuroHPC systems were delivered on-schedule and debut on the list. Two of the systems have two partitions, so there are actually six systems: Vega (#107, 3.8 petaflops, Slovenia, Atos), MeluXina accelerator module (#37, 10.5 petaflops, Luxemborg, Atos), MeluXina cluster module (#232, 2.3 petaflops, Luxemborg, Atos), Karolina GPU partition (#70, 6.0 petaflops, Czechia, HPE), Karolina CPU partition (#149, 2.8 petaflops, Czechia, HPE) and Discoverer (#92, 4.5 petaflops, Bulgaria, Atos). Petascale Deucalion (Portugal, Fujitsu) and larger pre-exascale systems Leonardo (Italy, Atos) and Lumi (Finland, HPE) are still on the way. We are still awaiting details on the eighth EuroHPC system MareNostrum 5 (Spain, ?). [Update: Read about the latest developments for MareNostrum 5 on HPCwire]
Energy efficiency: Green500
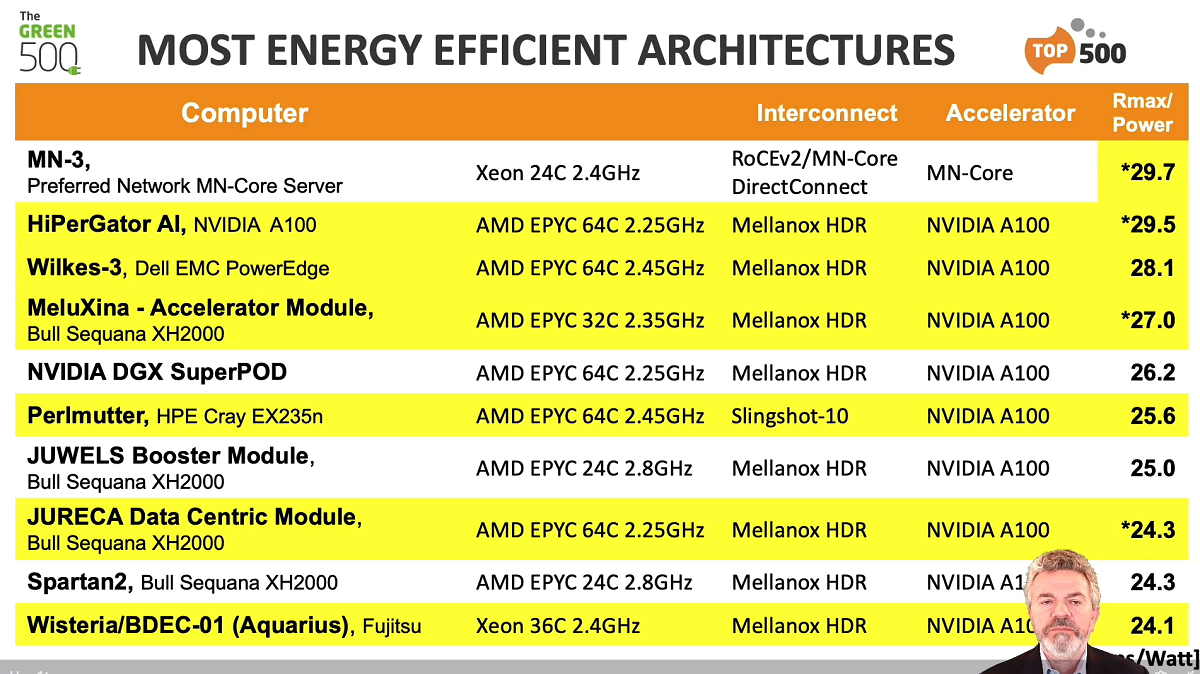
 Reclaiming the number one spot on the Green500 is Preferred Networks’ MN-3 system. After being knocked off by Nvidia’s DGX Superpod six months ago, PFN boosted the power-efficiency of its deep-learning-optimized MN-3 system to deliver 29.70 gigaflops-per-watt up from 26.0 gigaflops-per-watt. MN-3 is powered by the MN-Core chip, a proprietary accelerator that targets matrix arithmetic. The system is ranked number 337 on the Top500 list with 1.8 Linpack petaflops.
Reclaiming the number one spot on the Green500 is Preferred Networks’ MN-3 system. After being knocked off by Nvidia’s DGX Superpod six months ago, PFN boosted the power-efficiency of its deep-learning-optimized MN-3 system to deliver 29.70 gigaflops-per-watt up from 26.0 gigaflops-per-watt. MN-3 is powered by the MN-Core chip, a proprietary accelerator that targets matrix arithmetic. The system is ranked number 337 on the Top500 list with 1.8 Linpack petaflops.
The Green500’s second place finisher is HiPerGator AI of the University of Florida, delivering 29.52 gigaflops-per-watt power efficiency. The Nvidia DGX A100 system uses AMD Epyc Rome CPUs, Nvidia A100 GPUs and InfiniBand HDR networking. At number 22 on the Top500 with 17.20 petaflops, this is a much larger machine than the number-one greenest system.
In third place on the Green500 is Wilkes-3, made by Dell and installed at the University of Cambridge. The new entrant – powered by AMD Eypc Milan CPUs and Nvidia A100 80GB GPUs with HDR InfiniBand – delivered 28.14 gigaflops-per-watt power efficiency. It is ranked at number 101 on the Top500 with 4.1 petaflops.
Out of the top 10 most power-efficient systems, six are new machines. 17 of the top 20 Green500 machines are accelerated. The other three (non-accelerated) machines are all Fujitsu Arm based: Fugaku, the Fugaku prototype and Odyssey.
Once again, the diversity of international representation within the upper tier of the Green500 that we’ve seen over the last few years is an encouraging trend. Japan, the United States, the United Kingdom, Luxembourg, Germany, France, Czechia and Italy all have machines in the top 25.
Additional highlights: Cloud, Interconnects, Processor Diversity & More
Microsoft Azure debuts on the 57th Top500 list as the manufacturer of four cloud-based clusters, making a run on spots 26 through 29. The four machines – each benchmarked at 16.6 petaflops – are based on Azure’s NDv4 cluster. This is an Nvidia HGX design that leverages eight Nvidia A100 GPUs and two AMD Epyc Rome 48-core processors, interconnected by 200 Gbps HDR InfiniBand.
Microsoft told us that the actual Azure ND A100 v4-series clusters are significantly larger than the four benchmarked machines. “We are not disclosing how big, but we chose to only run the benchmarks on a portion of each cluster, in part to better satisfy the incredible demand for access by our customers,” noted Ian Finder, senior program manager with the Azure HPC Group.
Anther cloud provider, Amazon Web Services, refreshed its presence on the list via customer Descartes Labs. The geospatial intelligence company spun up the number 41 machine, comprised of AWS EC2 xlarge R5 instances, using Xeon 24-core Cascade Lake CPUs and 25G Ethernet. The 2019-era machine delivers 9.96 Linpack petaflops out of a theoretical peak of 15.11 petaflops (66 percent efficiency). “Our cloud usage today spans the range of analysis of earth observation datasets at the petascale, particularly moving beyond just optical imagery into more esoteric types of earth observation such as radar, InSAR, and AIS data,” said Mike Warren, Descartes Labs cofounder and CTO.
This list includes 144 systems that make use of accelerator/co-processor technology, down from 148 in June. Out of the 144 current accelerated systems, 138 (96 percent) employ Nvidia technology. There is only one entry on the list that uses AMD GPUs: a Sugon-made, Chinese system at Pukou Advanced Computing Center, powered by AMD Epyc “Naples” CPUs and AMD Vega 20 GPUs. That system, now at #378, first made its appearance in November 2019.

The Top500 reports that Intel continues to provide the processors for the largest share (86.20 percent) of Top500 systems, down from 91.80 percent six months ago and 94 percent one year ago. Intel Ice Lake processors made their debut this list in eight systems.
AMD supplies CPUs for 49 systems (9.8 percent), up from 4.2 percent six months ago and 2 percent one year ago. AMD Epyc processors power half of the 58 new entries on the June 2021 list. Four third-gen Epyc Milan systems debuted on this list, including Perlmutter.
AMD enjoys higher top rankings with Selene (#5) and Perlmutter (#6) than Intel with Tianhe-2A (#7). The top four systems on the list are not x86-based.
The aggregate Linpack performance provided by all 500 systems is 2.80 exaflops, up from 2.43 exaflops six months ago and 2.22 exaflops 12-months ago. The Linpack efficiency of the entire list is holding essentially steady at 63.1 percent compared with 63.3 percent six months ago, and the Linpack efficiency of the top 100 segment is down slightly: 70.7 percent compared with 71.2 percent six months ago. The number one system, Fugaku, delivers a healthy computing efficiency of 82.28 percent.
The minimum Linpack score required for inclusion on the 57th Top500 list is 1.52 petaflops compared with 1.32 petaflops six months ago. The entry point for the top 100 segment is 4.13 petaflops versus 3.16 petaflops for the previous list. The current number 500 system was ranked at number 450 on the last edition.
With just 50 systems pushed off the list, the low-turnover trend continues. The last three lists have seen the lowest replacement rates in the project’s history.

Five current or former number-one systems are on the June 2021 list. Besides Fugaku are Summit, Sunway TaihuLight, Tianhe-2A and Tianhe-1A. Tianhe-1A is very old by HPC terms, and in fact it is the oldest system on the list. Installed at National Supercomputing Center in Tianjin (China) over a decade ago, Tianhe-1A first entered the Top500 list in November 2010. The second oldest system on the list, debuted in June 2011, is an internal Intel cluster, called (appropriately) Endeavor. It is now at at number 379 with 1.6 petaflops.
Whence exascale?
The one-time goal for exascale, 2020, has come and gone and an exascale system has not yet made it on to the Top500 list. The U.S. is on track to stand up its first exascale system, Frontier, at Oak Ridge National Lab, later this year. It is an open question whether it will be benchmarked in time for the November 2021 Top500 list. China is in the running to stand up an exascale system in the 2020-2021 timeframe, and may have already done so. A “status report from China” will be delivered by Depei Qian (Beihang University, China) this Thursday during the ISC proceedings.

























































