 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
A near node local storage innovation called Rabbit factored heavily into Lawrence Livermore National Laboratory’s decision to select Cray’s proposal for its CORAL-2 machine, the lab’s first exascale-class supercomputer, El Capitan. Details of this new storage technology were revealed by Livermore Computing CTO Bronis de Supinski at the Riken-CCS International Symposium, which took place earlier this week (Jan. 15).
A 2 exaflops supercomputer slated for delivery at Livermore in late 2022 or early 2023, El Capitan is a partnership between the Department of Energy lab and HPE (which acquired Cray in 2019). As has been previously disclosed, El Capitan will be powered by AMD CPUs and GPUs as part of the Cray EX architecture (formerly known as Shasta) with Slingshot networking.
Under a non recurring engineering (NRE) contract funded by Livermore, HPE is developing near node local storage technology that it calls its Rabbit program. De Supinski explains that NRE contracts allow procurers, such as Livermore, to improve elements of the overall system, and those innovations then flow to the broader HPC market through the partnering vendor’s portfolio.
At its core, Rabbit is a 4U solution for node local storage that encompasses 18 SSDs (16 and 2 spares) and one (AMD Epyc) storage processor. HPE refers to Rabbit as near node local storage that combined with its custom Rabbit software supports a wide range of use cases, including resolving network bursts, optimizing input, and even running analysis processes.
De Supinski described the arrangement: “You have PCI connections from each of the compute nodes into what HPE calls the Rabbit-S boards, and that gives you a PCIe network that connects you to a fairly large number of SSDs and also to a Rabbit-P board, which has a separate AMD processor located on it that allows you to interact with the storage independent of the compute blades.”
Here’s what HPE expects the Rabbit design to look like:
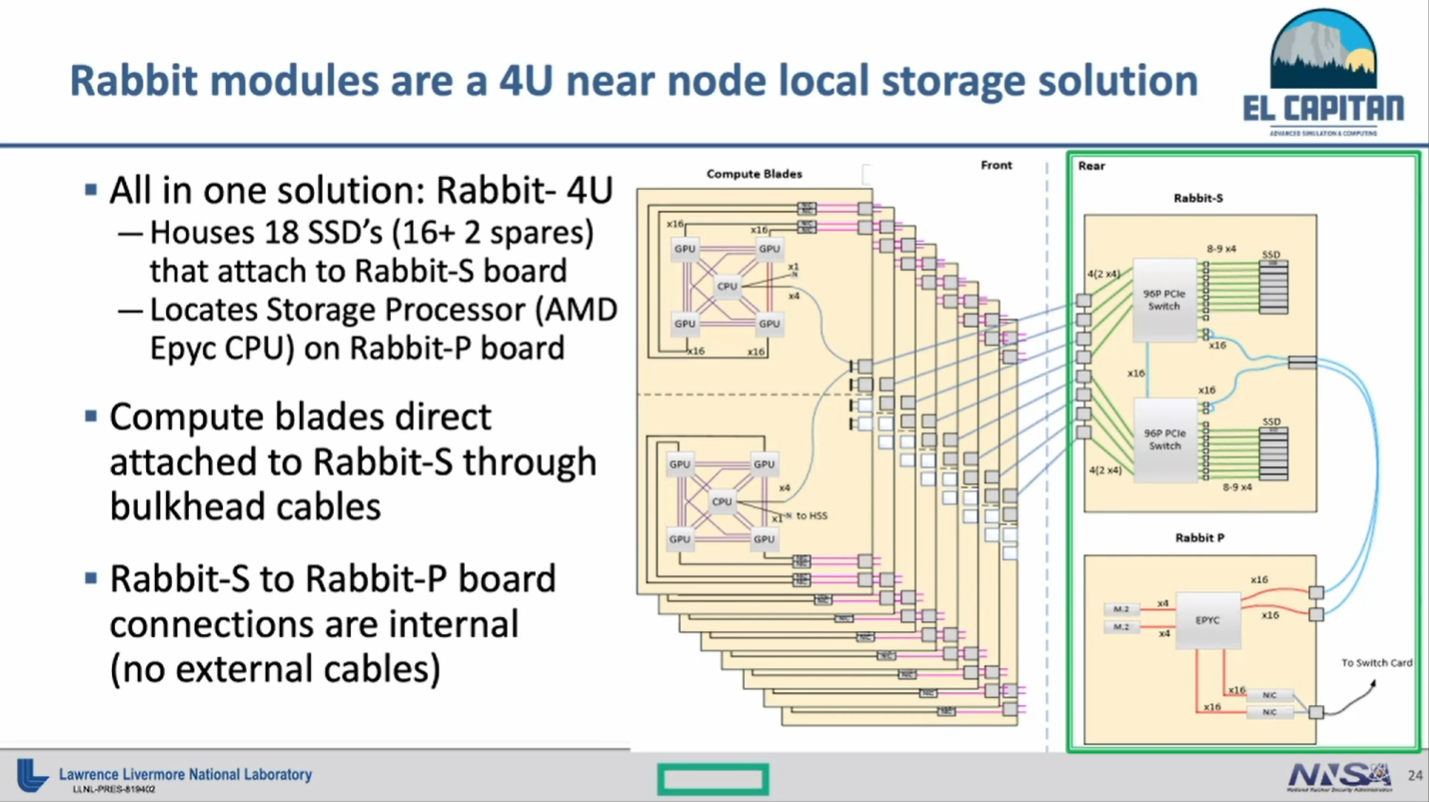
“If we think about how Rabbit works, this is really like building a little nest of PCIe networks within the larger system,” said de Supinski.
The 4U Rabbit box plugs into the back of the Cray XE racks, where the switch modules are housed. “Instead of populating all the switch blades, which would have given us far more interconnect bandwidth than we feel our workloads need, we’re going to populate some of those slots with Rabbit modules,” said de Supinski.
The HPE Rabbit software is of course where much of the magic happens and allows the SSDs to be accessed both as direct attached storage and network attached storage. “You can actually access the SSDs directly from the compute blade, or you can treat it as just a block storage device allocated to a specific compute blade,” said de Supinski.
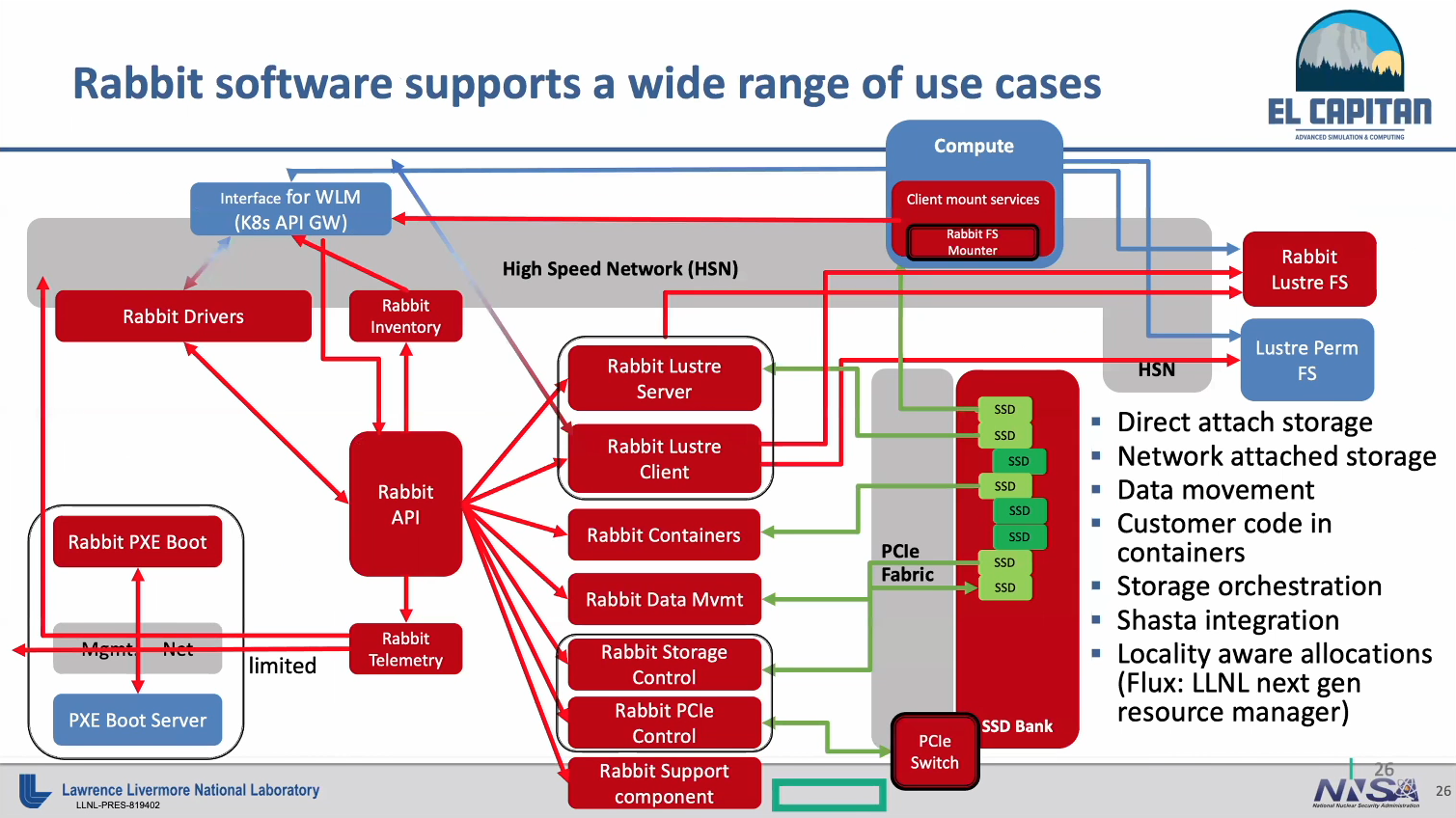
Rabbit can be implemented as a “transient Lustre file system” across the compute blades. The software facilitates moving files from these block devices — these transient Lustre file systems — to the capability tier of the overall IO subsystem of El Capitan, said De Supinski. “It will automate movements between these different tiers, but they are effectively very different in how we intend to use them.”
Another important aspect of the Rabbit software is it allows customer code to be run in containers on the Rabbit processors. This ties to Livermore’s choice of resource manager for El Capitan, which is Flux, a departure from Slurm. Designed by Livermore, Flux has awareness of the local compute node relationship to the SSDs, which is not supported in Slurm, according to de Supinski.
De Supinski reviewed some of the different use cases that Rabbit will facilitate at Livermore that make sense for the lab’s IO patterns. “There’s productive output, which is really the reason we run the simulations,” he shared. “And there’s checkpoints [typically a defensive output]. Those checkpoints can be one per MPI process, or at least one per all of the processes running on a given compute node. Or they can be shared across multiple processes and frequently across all of the processes in a given job. And so that’s this N-to-N versus N-to-M checkpoint.

“What we actually see in our jobs is frequently a combination of these where they maybe have a shared file that’s accessed by all of the processes in the job and then they write the bulk of their data to a file per compute process. And then you can have things that are semi-defensive or are semi-productive. In fact, it turns out that usually our application sciences want to use a checkpoint for subsequent data analysis.”
Using Rabbit to run analysis processes is an attractive use case for Livermore, and both post facto and in transit data analysis can be done in containers running on the Rabbit processors.
Like other leading HPC centers, Livermore has experienced compute capability outpacing the ability to deploy large file systems. “The cost would make it so that basically we can’t save all those checkpoints,” said de Supinski. “We tend to do much less input than output. The input can be executables, things like the applications themselves, but also operating system files and other system software files. We have the simulation input, which may just be something as simple as the parameters of a job, or you can restart data, i.e. the checkpoints that were previously output.”
The lab anticipates using Rabbit for caching OS files in order to reduce boot time, and notes that Rabbit will be an efficient input mechanism for machine learning model training.
When Rabbit is used as network attached storage, it’s as if the NVRAM servers were directly attached to the interconnect. While that does a good job of alleviating the swamping of the storage area network, it doesn’t alleviate the problem of swamping the high performance interconnect, said de Supinski. To address this, Livermore is developing a file system called UnifyFS. “We will use the Rabbit processors to run that, use the PCIe connections to access those disks, but with a file system that gives us shared file access.”
 Livermore is planning to put one Rabbit module in every El Capitan compute chassis (each chassis houses 8 blades / 16 compute nodes). “We expect that using these Rabbit models is going to significantly reduce system interference from IO on the overall system,” said de Supinski.
Livermore is planning to put one Rabbit module in every El Capitan compute chassis (each chassis houses 8 blades / 16 compute nodes). “We expect that using these Rabbit models is going to significantly reduce system interference from IO on the overall system,” said de Supinski.
Checkpointing is the lab’s top priority, but other aspects of IO are becoming more important. De Supinski believes the Rabbit modules will support these other storage workloads very well.
“When we were evaluating the responses we got to the CORAL-2 RFP at Livermore, we found the Rabbit solution to be one of the key innovations that HPE was offering,” said de Supinski. “It was a significant factor in our choice of the Cray response for El Capitan.”























































